1.前言
这篇主要是进行多元线性回归问题的解决,也是参考了csdn的大神们摸索写出来的,所需的材料环境和上一篇相同,就连代码都非常相似,但是多了一个正规方程的算法
2.导入包以及数据准备
1.导入三个数据分析常用的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt2.数据准备
注意:这里所取出的data数据需要进行归一化处理(也就是特征缩放),因为数据的范围相差太大,影响平衡,所以可以用每一列的数据减去当前列的平均值除以方差来得到我们需要的数据
# 取出ex1data2.txt的内容
data = pd.read_csv('ex1data2.txt', header=None, names=['hs_area', 'hs_num', 'hs_price'])
# print(data) # 查看一下data是否取出
# 数据范围太大,进行归一化处理
data = (data - data.mean()) / data.std() # data.mean()方法默认求出每一列的平均值,data.sta()为方差
data.insert(0, 'ones', 1)
x = data.iloc[:, 0:-1] # 取出所有行,除了最后一列剩下都给 x
y = data.iloc[:, 3:4] # 取出所有行,取出最后一列给 y
x = np.matrix(x) # 将x转换为matrix类型的矩阵
y = np.matrix(y) # 将y也转换成matrix
theta = np.matrix(np.zeros((3, 1))) # 将theta初始化为3*1维的矩阵3.未归一化之前,data的内容

4.归一化之后,data的内容
可以看出范围明显的减少,大约在(-3,3)之间

3.代价函数
这里的代价函数和上一篇的线性回归是一样的
# 代价函数
def cost_fuc(x, y, theta):
cost = np.power(x @ theta - y, 2) # 求出一条数据差值的平方
return np.sum(cost) / (2 * len(x))
pass测试一下初始代价
print(cost_fuc(x, y, theta)) # 测试一下初始代价 
4.梯度下降算法
1.多元即增加了多个特征值
虽然增加了多个特征值,但是求解的方式还是一样的,同样是利用矩阵来求解,这次的案例分别有房屋面积,以及房屋房间这俩个特征值,算上最开始插入的一列1,x就是一个n*3维的矩阵,theta同时也被初始化为3*1维的矩阵,相乘得到包含所有预估值的n*1维的矩阵
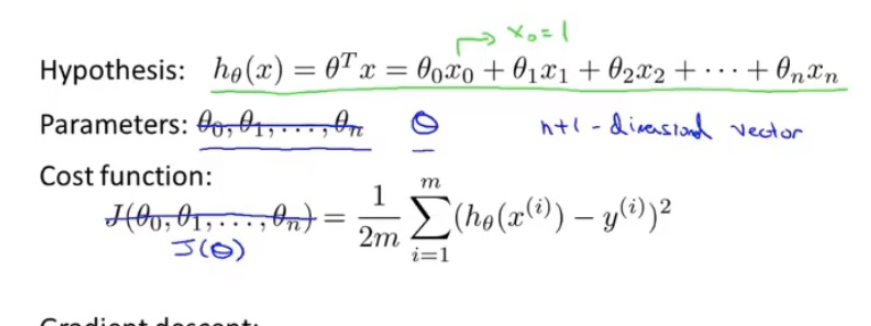
2.偏导计算
因为特征值的增加,theta也在增加,所以所要求的偏导的也在增加,这里的偏导函数手动计算就可以得出,可以看出是有规律的(x0代表插入的第一列,x1代表第一个特征值的属性值列,x2同理)

# 梯度下降算法
def gradient_descent(x, y, theta, alpha, update_times):
cost_list = []
for i in range(update_times):
temp0 = theta[0] - (x @ theta - y).sum() * (alpha / len(x))
temp1 = theta[1] - (np.multiply((x @ theta - y), x[:, 1:2])).sum() * (alpha / len(x))
temp2 = theta[2] - (np.multiply((x @ theta - y), x[:, 2:3])).sum() * (alpha / len(x))
theta[0] = temp0
theta[1] = temp1
theta[2] = temp2
cost_list.append(cost_fuc(x, y, theta))
return theta, cost_list
pass
5.学习率的选择
可以选择多个学习率进行比较,如果学习率选取教大,那可能就不会收敛,而是跨过收敛最佳值变得原来越发散,如果学习率选取教小,那么收敛的速度将会非常慢,一点点的向终点蹭

alpha_list = [0.003, 0.03, 0.3] # 设置a的值,画图看哪一个效果最好
update_times = 200 # 更新的次数6.构图
构图主要是为了看学习率的选取结果,随着迭代次数的增加,不同的学习率所得出的代价函数的运动轨迹
# 构图
fig, ax = plt.subplots()
for alpha in alpha_list: # 迭代不同学习率alpha
theta = np.matrix(np.zeros((3, 1))) # 将theta初始化为3*1维的矩阵
_, costs = gradient_descent(x, y, theta, alpha, update_times) # 得到损失值
ax.plot(np.arange(update_times), costs, label=alpha) # 设置x轴参数为迭代次数,y轴参数为cost
ax.legend() # 加上这句 显示label
7.正规函数方程
梯度下降是通过不停迭代的方式使代价函数不断降低,如果学过高数就会知道有一个求函数最小值的方法,那就是对函数求导,令求出的导数为0,其中得到的theta的值通常就是最优解,正规函数方程就利用了这个方法(正规方程适合小于10000的数据集,如果超过10000还是用梯度算法更快一些)

得到的theta解如下,想知道过程的可以自行推导,也可以取找大神们的笔记
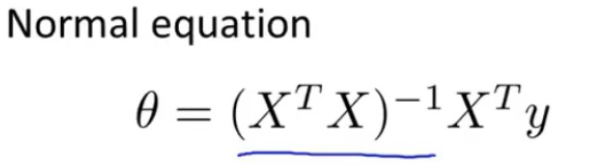
# 正规函数方程
def normal_func(x, y):
theta = np.linalg.inv(x.T@x)@x.T@y
return theta打印正规函数所得到的theta矩阵

8.全部代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 取出ex1data2.txt的内容
data = pd.read_csv('ex1data2.txt', header=None, names=['hs_area', 'hs_num', 'hs_price'])
# print(data) # 查看一下data是否取出
# 数据范围太大,进行归一化处理
data = (data - data.mean()) / data.std() # data.mean()方法默认求出每一列的平均值,data.sta()为方差
data.insert(0, 'ones', 1)
x = data.iloc[:, 0:-1] # 取出所有行,除了最后一列剩下都给 x
y = data.iloc[:, 3:4] # 取出所有行,取出最后一列给 y
x = np.matrix(x) # 将x转换为matrix类型的矩阵
y = np.matrix(y) # 将y也转换成matrix
theta = np.matrix(np.zeros((3, 1))) # 将theta初始化为3*1维的矩阵
# 代价函数
def cost_fuc(x, y, theta):
cost = np.power(x @ theta - y, 2) # 求出一条数据差值的平方
return np.sum(cost) / (2 * len(x))
pass
# print(cost_fuc(x, y, theta)) # 测试一下初始代价
# 梯度下降算法
def gradient_descent(x, y, theta, alpha, update_times):
cost_list = []
for i in range(update_times):
temp0 = theta[0] - (x @ theta - y).sum() * (alpha / len(x))
temp1 = theta[1] - (np.multiply((x @ theta - y), x[:, 1:2])).sum() * (alpha / len(x))
temp2 = theta[2] - (np.multiply((x @ theta - y), x[:, 2:3])).sum() * (alpha / len(x))
theta[0] = temp0
theta[1] = temp1
theta[2] = temp2
cost_list.append(cost_fuc(x, y, theta))
return theta, cost_list
pass
# 正规函数方程
def normal_func(x, y):
theta = np.linalg.inv(x.T@x)@x.T@y
return theta
# print(normal_func(x,y)) # 打印正规方程解
alpha_list = [0.003, 0.03, 0.3] # 设置a的值,画图看哪一个效果最好
update_times = 200 # 更新的次数
# 构图
fig, ax = plt.subplots()
for alpha in alpha_list: # 迭代不同学习率alpha
theta = np.matrix(np.zeros((3, 1))) # 将theta初始化为3*1维的矩阵
_, costs = gradient_descent(x, y, theta, alpha, update_times) # 得到损失值
ax.plot(np.arange(update_times), costs, label=alpha) # 设置x轴参数为迭代次数,y轴参数为cost
ax.legend() # 加上这句 显示label
ax.set(xlabel='counts', # 图的坐标轴设置
ylabel='cost',
title='cost vs counts') # 标题
plt.show() # 显示图像