第三周
六、逻辑回归(Logistic Regression)
这里首先区分一下线性回归和逻辑回归,线性回归就是拟合,逻辑回归是分类。
6.2 假说表式(Hypothesis Representation)
下面一个部分主要讲的是假设函数h(x)在分类问题中输出只能是0/1,所以需要引入新的函数表示,也即是逻辑函数。


6.3 判定边界
【我的理解:下边讲的其实就是逻辑回归的假设函数(Hypothesis Representation)和线性回归的假设函数的区别就是多了一层逻辑回归函数,而且里边的z是什么函数,区别在于你的分类边界时什么样子的。】
现在讲下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。



6.4 代价函数
这里主要讲的是:逻辑回归模型由于假设函数h(x)中含有非线性的逻辑函数,如果直接将假设函数带入代价函数就会出现非凸函数,那么就无法使用梯度下降。

所以,这里将代价函数通过下边的过程变换,得到了凸函数J(
).

在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。算法为:
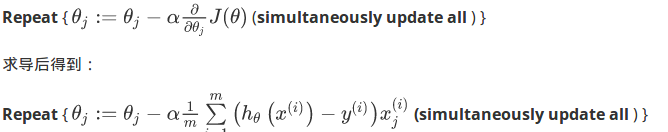
6.4.2.题外话
1.虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的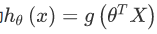 与线性回归中不同,所以实际上是不一样的。
与线性回归中不同,所以实际上是不一样的。

2.另外,在运行梯度下降算法之前,进行特征缩放依旧是非常必要的。
6.5 简化的成本函数和梯度下降 (Simplified Cost Function and Gradient Descent )
以上都是在推倒如何建立模型,如何1.构建假设函数,如何构建逻辑回归的2.代价函数与3.使用梯度下降法的话如何求导,下面通过简单的整合,我们再梳理一遍整个过程:

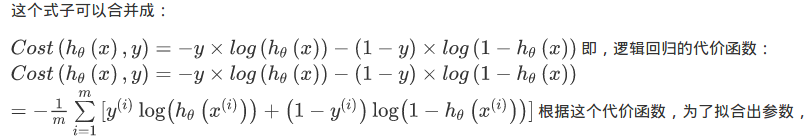

另外需要关注的三点:
1.那么,线性回归和逻辑回归是在假设函数的区别:
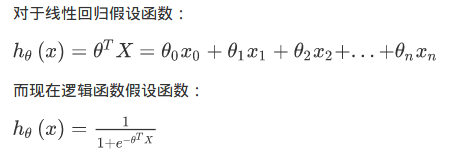
2.
向量化计算,同时更新。
3.特征缩放是如何提高梯度下降的收敛速度的,这个特征缩放的方法,也适用于逻辑回归。如果你的特征范围差距很大的话,那么应用特征缩放的方法,同样也可以让逻辑回归中,梯度下降收敛更快。
6.6 高级优化
好,现在以上的所有一切的介绍就是将分类问题归纳为:用梯度下降的方法最小化逻辑回归中代价函数 。这样一个问题,作者这里这节想介绍的是:1.如何编写代码求解这个问题。2.扩展介绍一下其他方法代替梯度下降【这个涉及到最优化问题了】。
1.如何编写代码求解这个问题。
现在我们换个角度来看什么是梯度下降,我们有个代价函数
,而我们想要使其最小化,那么我们需要做的是编写代码,当输入参数
时,它们会计算出两样东西:
以及
等于 0、1直到
时的偏导数项
。

对于梯度下降来说,我认为从技术上讲,你实际并不需要编写代码来计算代价函数 。你只需要编写代码来计算导数项 ,但是,如果你希望代码还要能够监控这些 的收敛性,那么我们就需要自己编写代码来计算代价函数 和偏导数项 .
2.扩展介绍一下其他方法代替梯度下降

这三种算法有许多优点:
一个是使用这其中任何一个算法,你通常不需要手动选择学习率 ,所以对于这些算法的一种思路是,给出计算导数项和代价函数的方法,你可以认为算法有一个智能的内部循环,而且,事实上,他们确实有一个智能的内部循环,称为线性搜索(line search)算法,它可以自动尝试不同的学习速率 ,并自动选择一个好的学习速率 ,因此它甚至可以为每次迭代选择不同的学习速率,那么你就不需要自己选择。这些算法实际上在做更复杂的事情,不仅仅是选择一个好的学习速率,所以它们往往最终比梯度下降收敛得快多了。
6.7 多类别分类:一对多
多分类问题的可以转化为二分类问题,具体转化如下过程:
1.训练的时候,构建一个“伪”训练集,将其中一个设为正类,其他为负类:构造二分类代价函数:

2.其他类别也这样做,构造一系列模型:

3.在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。
