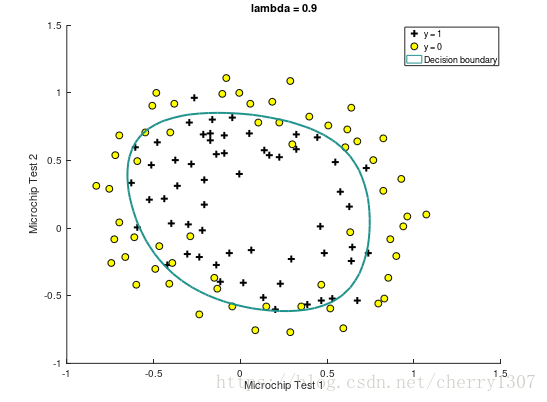
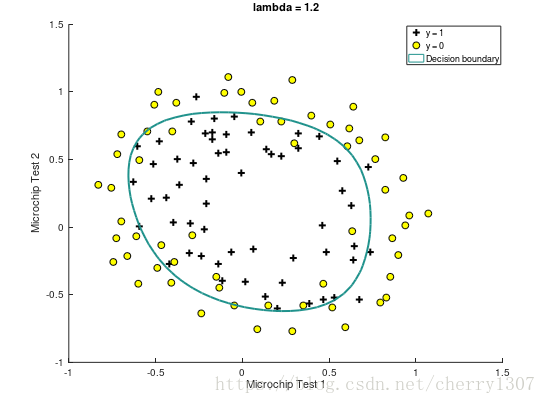
过拟合
如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集(代价函数可能几乎为0),但是可能会不能推广到新的数据。
解决:
1.丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
2.正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
正则化
正则化(regularization)的技术,它可以改善或者减少过度拟合问题
线性回归
梯度下降
theta(0)不参与惩罚项
正规方法
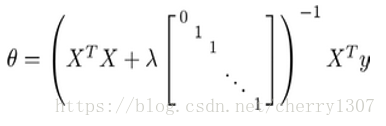
Logistic回归
theta(0)不参与惩罚项
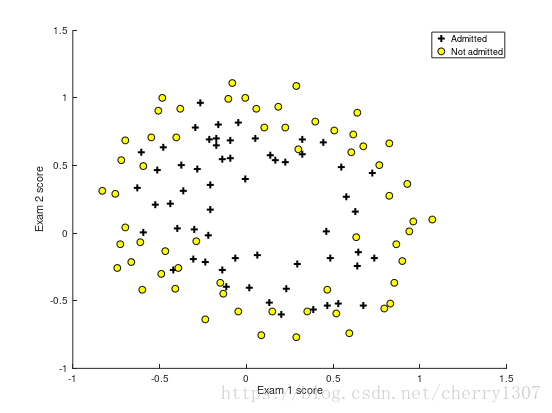
练习2
x1,x2 : the test results for some microchips on two di
erent tests
y : decision
可视化数据集
特征映射
function out = mapFeature(X1, X2)
degree = 6;
out = ones(size(X1(:,1)));
for i = 1:degree
for j = 0:i
out(:, end+1) = (X1.^(i-j)).*(X2.^j);
end
end
end

特征向量X的维度为:m*28
代价函数和梯度下降
function [J, grad] = costFunctionReg(theta, X, y, lambda)
m = length(y);
J = 0;
grad = zeros(size(theta));
h = sigmoid(X*theta);
J = (1/m)*sum((-y)'*log(h)-(1-y)'*log(1-h)) + lambda/(2*m)*sum(theta(2:end).^2);
grad(1) = (1/m)*sum((h-y).*X(:,1));
for j = 2:size(X,2)
grad(j) = (1/m)*sum((h-y).*X(:,j)) + lambda*theta(j)/m;
end
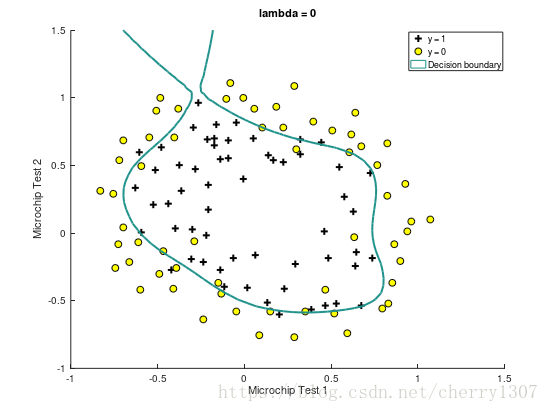
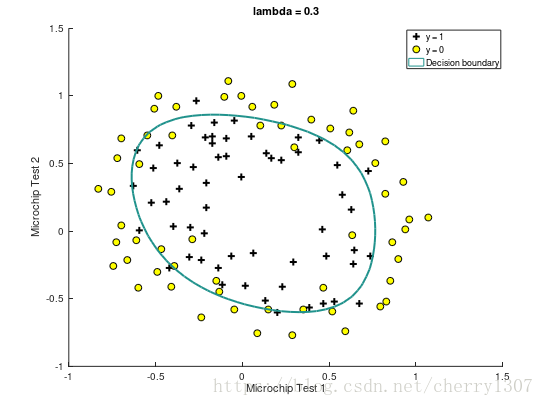
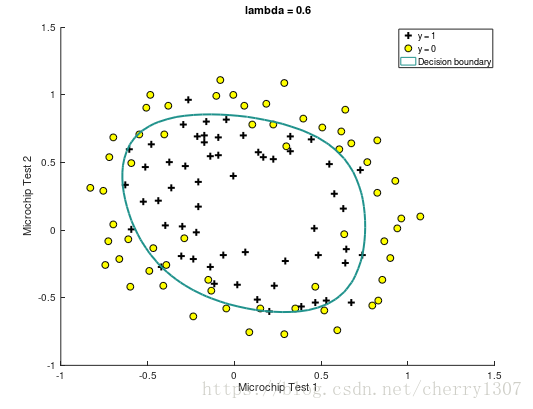
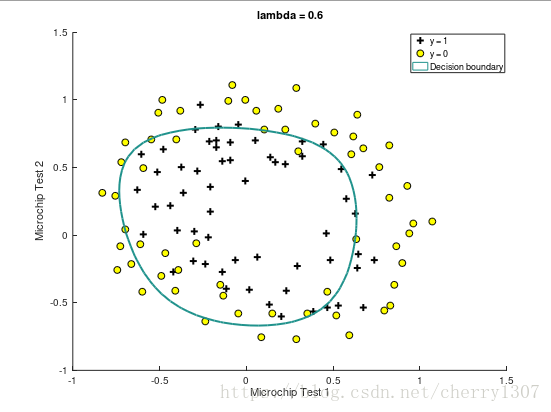
绘制出决策边界