1.起因
刚看了吴恩达老师讲的矢量那一部分,了解到梯度下降算法其实还可以优化一下,我就自行也进行了推导,相较于优化之前的梯度算法,优化之后的梯度算法看着更加简便一些,执行速度也更快
2.算法优化
1.优化之前的梯度算法
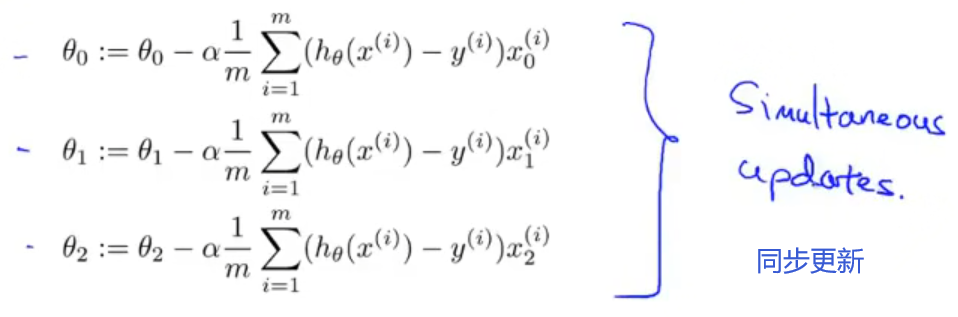
优化之前,我是把theta矩阵的每一个数据都单独拿出来进行更新操作,同时也需要3个临时变量来保证同步更新,这样做可以处理含有少量特征值的数据集,可是一旦特征值达到几百个几千个的时候,可能我们就要用for循环来进行更新了,这样的时间复杂度会非常高
def gradient_descent(x, y, theta, alpha, update_times):
cost_list = []
for i in range(update_times):
temp0 = theta[0] - (x @ theta - y).sum() * (alpha / len(x))
temp1 = theta[1] - (np.multiply((x @ theta - y), x[:, 1:2])).sum() * (alpha / len(x))
temp2 = theta[2] - (np.multiply((x @ theta - y), x[:, 2:3])).sum() * (alpha / len(x))
theta[0] = temp0
theta[1] = temp1
theta[2] = temp2
cost_list.append(cost_fuc(x, y, theta))
return theta, cost_list
pass
2.优化之后
def gradient_descent(x, y, theta, alpha, update_times):
cost_list = []
for i in range(update_times):
theta = theta - (alpha/len(x)) * (x.T @ (x @ theta - y))
cost_list.append(cost_fuc(x, y, theta))
return theta, cost_list
pass我们可以看到,多行代码只需一行就可实现了,这其实用到的也是矩阵的知识,并不难理解,我写了一下推导过程,我会尽量解释清楚
3.推导过程
下面解释一下我的推导过程

我们核心就是想利用矩阵的加减乘除一次性的算出每次迭代的全部theta,可以知道的是,theta是一个3*1维的矩阵,公式可以看出我们需要通过theta减去后面的一串才能更新自己(见图一),因此我们需要将后面的一串也变为一个3*1维的矩阵,由上面图片能看出C矩阵是一直不变的,同时一直也是保持为n*1维的矩阵,而右边的x矩阵是随着偏导的系数不同一直在改变的,那我们就可以尝试把每一个特征值的数据列放在一起,这里有三个特征值(算前面插入的第一列1),那么就可以凑出一个n*3维的X矩阵,这时我们就可以通过转质换位置来得到一个3*1维的矩阵,同时可以看出,新矩阵的每一个值都是我们所需要的,这里面用到的都是矩阵的乘法,没有点乘,所以我们也省去了.sum()求列之和这一步骤。可能我的叙述不够明确,大家也可以去了解一下线性代数的知识,相信很快就能理解了
3.附上优化之后的全部代码
代码和上一篇改动只在梯度算法那一块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 取出ex1data2.txt的内容
data = pd.read_csv('ex1data2.txt', header=None, names=['hs_area', 'hs_num', 'hs_price'])
# print(data) # 查看一下data是否取出
# 数据范围太大,进行归一化处理
data = (data - data.mean()) / data.std() # data.mean()方法默认求出每一列的平均值,data.sta()为方差
data.insert(0, 'ones', 1)
x = data.iloc[:, 0:-1] # 取出所有行,除了最后一列剩下都给 x
y = data.iloc[:, 3:4] # 取出所有行,取出最后一列给 y
x = np.matrix(x) # 将x转换为matrix类型的矩阵
y = np.matrix(y) # 将y也转换成matrix
theta = np.matrix(np.zeros((3, 1))) # 将theta初始化为3*1维的矩阵
# 代价函数
def cost_fuc(x, y, theta):
cost = np.power(x @ theta - y, 2) # 求出一条数据差值的平方
return np.sum(cost) / (2 * len(x))
pass
# print(cost_fuc(x, y, theta)) # 测试一下初始代价
# 梯度下降算法
def gradient_descent(x, y, theta, alpha, update_times):
cost_list = []
for i in range(update_times):
theta = theta - (alpha/len(x)) * (x.T @ (x @ theta - y))
cost_list.append(cost_fuc(x, y, theta))
return theta, cost_list
pass
# # 正规函数方程
# def normal_func(x, y):
# theta = np.linalg.inv(x.T@x)@x.T@y
# return theta
# theta1,cost_list = gradient_descent(x,y,theta,0.02,50)
# print(theta1)
# print(normal_func(x,y)) # 打印正规方程解
alpha_list = [0.003, 0.03, 0.3] # 设置a的值,画图看哪一个效果最好
update_times = 200 # 更新的次数
# 构图
fig, ax = plt.subplots()
for alpha in alpha_list: # 迭代不同学习率alpha
theta = np.matrix(np.zeros((3, 1))) # 将theta初始化为3*1维的矩阵
_, costs = gradient_descent(x, y, theta, alpha, update_times) # 得到损失值
ax.plot(np.arange(update_times), costs, label=alpha) # 设置x轴参数为迭代次数,y轴参数为cost
ax.legend() # 加上这句 显示label
ax.set(xlabel='counts', # 图的坐标轴设置
ylabel='cost',
title='cost vs counts') # 标题
plt.show() # 显示图像可以看出得到的结果是一样的
