这里参考了这位大神的文章:https://blog.csdn.net/youyuyixiu/article/details/72840893
先膜拜一下
自己处理过一些房价预测的数据,但是test测试集的特征情况和train训练集是不一样的,所以之前捣鼓了好久都没有成功,索性,就按照大佬的方法吧两个数据集给合并起来处理,具体如下:
step 0:引入相关的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
一开始用这三个足矣
step 1: 检查源数据集,读入数据,将csv数据转换为DataFrame数据
train_df = pd.read_csv('./data.csv',index_col = 0)
test_df = pd.read_csv('./test.csv',index_col = 0)
step2: 合并数据
进行数据预处理,这么做主要是为了用DF进行数据预处理的时候更加方便。等所有的需要的预处理进行完之后,我们再把他们分隔开。实际项目中,不会这样做。首先,SalePrice作为我们的训练目标,只会出现在训练集中,不会在测试集中。所以,我们先把SalePrice这一列给拿出来,不让它碍事儿。
prices = pd.DataFrame({'price':train_df['SalePrice'],'log(price+1)':np.log1p(train_df['SalePrice'])})
# log1p即log(1+x),可以让label平滑化
y_train = np.log1p(train_df.pop('SalePrice'))
all_df = pd.concat((train_df,test_df),axis = 0)
step3: 变量转化
正确化变量属性:MSSubClass 的值其实应该是一个category,但是Pandas是不会懂这些事儿的。使用DF的时候,这类数字符号会被默认记成数字。这种东西就很有误导性,我们需要把它变回成string
print(all_df['MSSubClass'].dtypes)
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
print(all_df['MSSubClass'].dtypes)
print(all_df['MSSubClass'].value_counts())
把category的变量转变成numerical表达形式:当我们用numerical来表达categorical的时候,要注意,数字本身有大小的含义,所以乱用数字会给之后的模型学习带来麻烦。于是我们可以用One-Hot的方法来表达category。pandas自带的get_dummies方法,可以帮你一键做到One-Hot。
print pd.get_dummies(all_df['MSSubClass'],prefix = 'MSSubClass').head()
all_dummy_df = pd.get_dummies(all_df)
print all_dummy_df.head()
one-hot参考:https://blog.csdn.net/u010712012/article/details/83002388
处理好numerical变量:比如,有一些数据是缺失的
print all_dummy_df.isnull().sum().sort_values(ascending = False).head(11)
# 我们这里用mean填充
mean_cols = all_dummy_df.mean()
print mean_cols.head(10)
all_dummy_df = all_dummy_df.fillna(mean_cols)
print all_dummy_df.isnull().sum().sum()
标准化numerical数据:一般来说,regression的分类器都比较傲娇,最好是把源数据给放在一个标准分布内。不要让数据间的差距太大。这里,我们当然不需要把One-Hot的那些0/1数据给标准化。我们的目标应该是那些本来就是numerical的数据,所以这是针对数值的数据的
# 标准化numerical数据
numeric_cols = all_df.columns[all_df.dtypes != 'object']
print(numeric_cols)
numeric_col_means = all_dummy_df.loc[:,numeric_cols].mean()
numeric_col_std = all_dummy_df.loc[:,numeric_cols].std()
all_dummy_df.loc[:,numeric_cols] = (all_dummy_df.loc[:,numeric_cols] - numeric_col_means) / numeric_col_std
step4:建立模型之前的数据集
# 把数据处理之后,送回训练集和测试集
dummy_train_df = all_dummy_df.loc[train_df.index]
dummy_test_df = all_dummy_df.loc[test_df.index]
print (dummy_train_df.shape,dummy_test_df.shape)
这里确实解决了我当时走不下去的难题,因为送回之后两个集合的特征都是一样的了。。。
# 将DF数据转换成Numpy Array的形式,更好地配合sklearn
X_train = dummy_train_df.values
X_test = dummy_test_df.values
step5: 把训练集切分成两部分,80%训练,20%用作测试
import xgboost as xgb
from sklearn.metrics import mean_squared_error
matrix=xgb.DMatrix(data=X_train,label=y)
from sklearn.model_selection import train_test_split
X_train1,X_test1,y_train1,y_test1=train_test_split(X_train,y,test_size=0.2,random_state=123)
这里需要解释一下,因为我们需要训练出一个可以去预测的模型,所以能想到的就是把训练集中的数据拿出80%的做训练,20%的做测试,这里的X_train1就是那80%,X_test1就是那20%,y就是后面的价格标签。
重点就是要调整xgboost的参数
max_depth: boosting过程中每一颗树的最大深度
learning_rate: 学习率(0-1)
colsample : 列采样率
subsample:每棵树的样本采样率
n_estimator:子树的数量,在这里应该是迭代次数
gamma/alpha:代表L1/L2
random_state: 不要让他随机生成,数据集是不断随机选择的。
要能更好地理解地去调参,就应该去好好看看决策树和boosting的知识了。
调参,是不可能调参的,这辈子都不可能的。。。谁叫你不分析数据!!!
step6: XGBoost模型和调参在这
xg_reg=xgb.XGBRegressor(objective='reg:linear',colsample_bytree=0.5,learning_rate=0.02,max_depth=4,alpha=8,n_estimators=800,subsample=0.7,random_state=123)
xg_reg.fit(X_train1,y_train1)
pred=xg_reg.predict(X_test1)
logrmse=np.sqrt(mean_squared_error(np.log(y_test1),np.log(pred)))
print(logrmse)
注意这里打印的结果是logmse,我们所说的mse是mean square error,即均方误差准则,但是我们一般都要加上一个log。
以上是训练集切分出来的训练模型测试结果。
下面开始训练我们的整个训练数据和label
xg_reg.fit(X_train, y)
预测的房价结果
y_final = xg_reg.predict(X_test)
step7: 最后提交预测结果
最后当然要提交看自己的成绩啦。
submission_df = pd.DataFrame(data = {'Id':test_df.index,'SalePrice':y_final})
print (submission_df.head(10))
submission_df.to_csv('./submission_xgboost.csv',columns = ['Id','SalePrice'],index = False)
这样就会生成一个csv的文件,有没有很激动!
到这里:https://www.kaggle.com/c/house-prices-advanced-regression-techniques/submit
提交你的数据
最后完成啦,下面是我的结果:
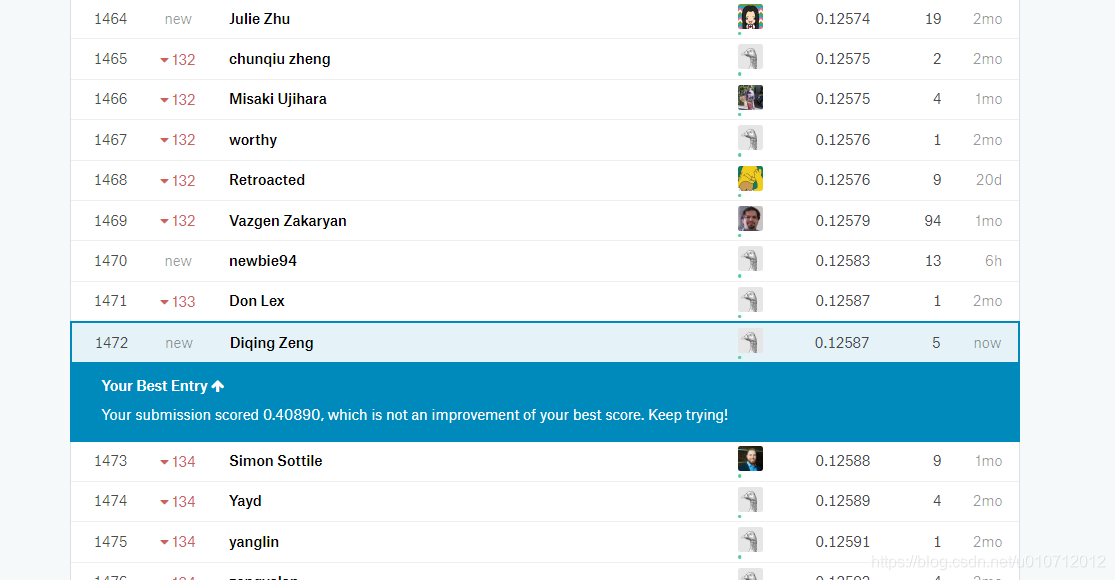
说来惭愧,自己没有把测试集完整地去填充空值,导致后面特征和训练集不一致,又急切想要去交数据结果,所以才参考了大佬的做法,之后还会继续做这个项目,争取把每一个特征都搞清楚。最后分开来处理,再加上使用集成和神经网络的算法,一定能取得更好的成绩!