房价预测
目录
一、认识数据
House Prices数据集分为train(即训练)数据和test(即测试)数据,其中,训练集含有1460个样本,80个属性(包括序号),一个标签(SalePrice,即房价);测试集含有1459个样本,80个属性。
需要做的工作:根据测试集的属性预测每个样本的房价。
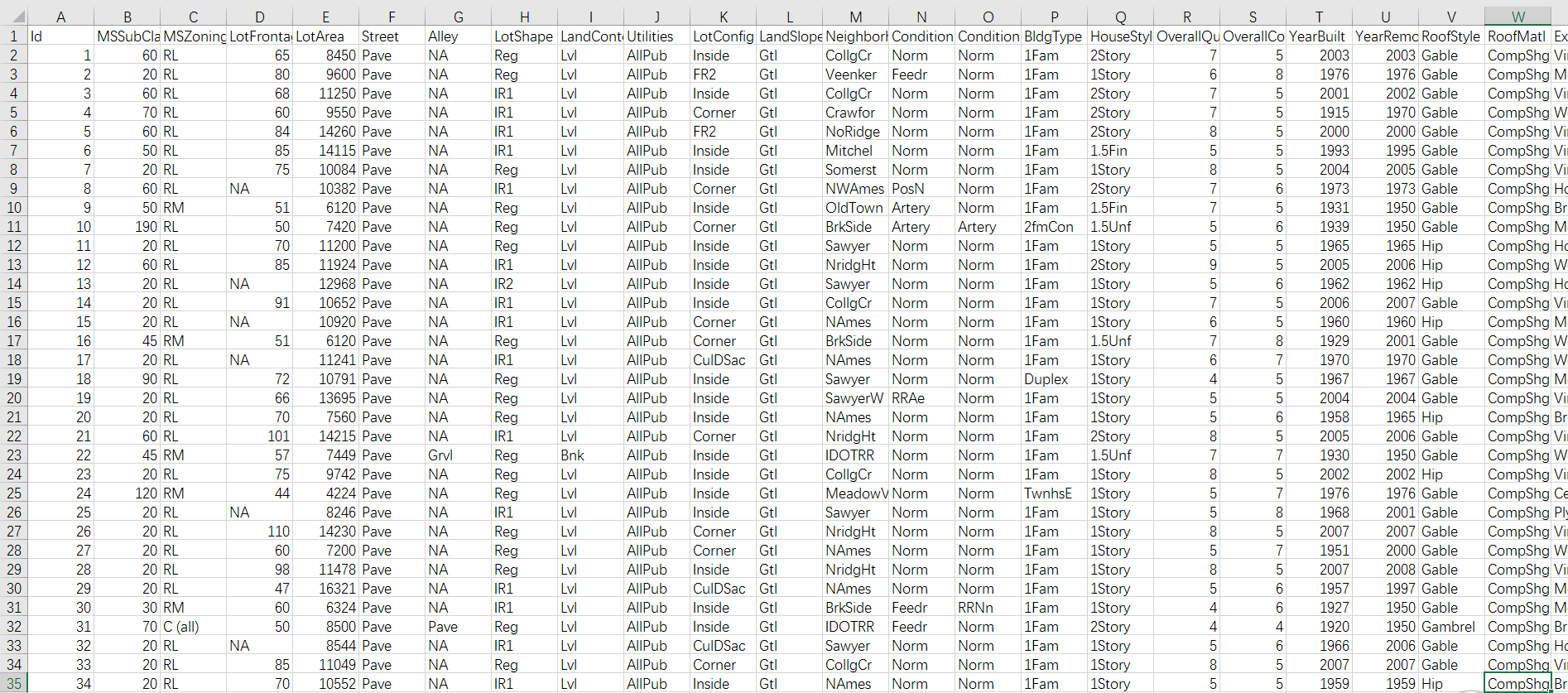
图1
二、定性分析
2.1 属性的意义
SalePrice 以美元出售的房产价格。
MSSubClass 建筑类
MSZoning 城市总体规划分区
LotFrontage 连接物业的街道线
LotArea: Lot size in square feet 方块大小
Street 道路入口类型
Alley 巷类型
LotShape 地产的外形
LandContour 地产的扁平化
Utilities 地产的公用事业类型
LotConfig 地产配置
LandSlope 地产的坡
Neighborhood 城市范围内的物理位置
Condition1 接近主干道或铁路
Condition2 接近主路或铁路
BldgType 住宅类型
HouseStyle 居家风格
OverallQual 整体质量和表面质量
OverallCond 总体状态额定值
YearBuilt 原施工日期
YearRemodAdd 重塑日期
RoofStyle 屋顶类型
RoofMatl 屋顶材料
Exterior1st 房屋外墙
Exterior2nd 外部第二层:房屋外部覆盖物
MasVnrType 圬工单板型
MasVnrArea 砌体单板覆盖面积
ExterQual: 外观材质
ExterCond 外墙材料的现状
Foundation 地基类型
BsmtQual 地下室的高度
BsmtCond 地下室概况
BsmtExposure: 走道或花园式地下室墙
BsmtFinType1 地下室竣工面积质量
BsmtFinSF1 1型成品面积
BsmtFinType2 第二成品区域的质量(如果存在)
BsmtFinSF2 2型成品面积
BsmtUnfSF 地下室面积
TotalBsmtSF 地下室面积总计面积
Heating 暖气方式
HeatingQC 暖气质量与条件
CentralAir 空调
Electrical 电气系统
1stFlrSF 一楼面积
2ndFlrSF 二楼面积
LowQualFinSF 低质量完工面积(所有楼层)
GrLivArea 高档(地面)居住面积
BsmtFullBath 地下室全浴室
BsmtHalfBath 地下室半浴室
FullBath 高档浴室
HalfBath 半日以上洗澡浴室
Bedroom 地下室层以上的卧室数
Kitchen 厨房数量
KitchenQual 厨房品质
TotRmsAbvGrd 总房间(不包括浴室)
Functional 家庭功能评级
Fireplaces 壁炉数
FireplaceQu 壁炉质量
GarageType 车库位置
GarageYrBlt 车库建成年
GarageFinish 车库的内饰
GarageCars 车库容量大小
GarageArea 车库大小
GarageQual 车库质量
GarageCond 车库状况
PavedDrive 铺好的车道
WoodDeckSF 木制甲板面积
OpenPorchSF 外部走廊面积
EnclosedPorch 闭走廊面积
3SsnPorch: 三季走廊面积
ScreenPorch 屏风走廊面积
PoolArea 泳池面积
PoolQC 泳池的质量
Fence 围栏质量
MiscFeature 其他类别的杂项特征
MiscVal 杂项价值
MoSold 月售出
YrSold 年销售
SaleType 销售类型
SaleCondition 销售条件
2.2 属性分析
可以看出,标签为房价,而对于79个属性主要分为几分方面:
(1)房子地理位置:
MSSubClass、MSZoning、LotFrontage、LotArea、Street、Alley、LotShape、LandContour、Utilities、LotConfig、LandSlope、Neighborhood、Condition1、Condition2
(2)房子风格:
BldgType、HouseStyle、OverallQual、OverallCond
(3)房子装修:
YearBuilt、YearRemodAdd、RoofStyle、RoofMatl、Exterior1st、Exterior2nd、MasVnrType、MasVnrArea、ExterQual:
ExterCond
(4)地下室:
Foundation、BsmtQual、BsmtCond、BsmtExposure:、BsmtFinType1、BsmtFinSF1、BsmtFinType2、BsmtFinSF2、BsmtUnfSF、TotalBsmtSF
(5)冷暖气:
Heating、HeatingQC、CentralAir、Electrical
(6)居住面积:
1stFlrSF、2ndFlrSF、LowQualFinSF、GrLivArea
(7)功能房间:
BsmtFullBath、BsmtHalfBath、FullBath、HalfBath、Bedroom、Kitchen、KitchenQual、TotRmsAbvGrd、Functional
(8)车库:
GarageType、GarageYrBlt、GarageFinish、GarageCars、GarageArea、GarageQual、GarageCond、PavedDrive
(9)其他面积:
WoodDeckSF、OpenPorchSF、EnclosedPorch、3SsnPorch:、ScreenPorch、PoolArea
(10)销售:
MoSold、YrSold、SaleType、SaleCondition
(11)其他:
Fireplaces、FireplaceQu、PoolQC、Fence、MiscFeature、MiscVal
假如数据真实可靠,则从实际情况考虑,对于一个房子的价格,最重要的属性首先应该有:地理位置、面积、地下室、冷暖气、车库、房子质量,还有会影响到房价的有:销售条件如时间和方式。所以先可以着重讨论这些方面的属性。
三、缺失值处理
3.1 缺失值举例
图中NA就是缺失值:
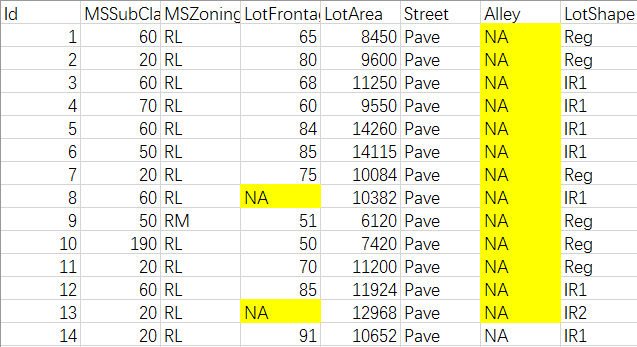
图2
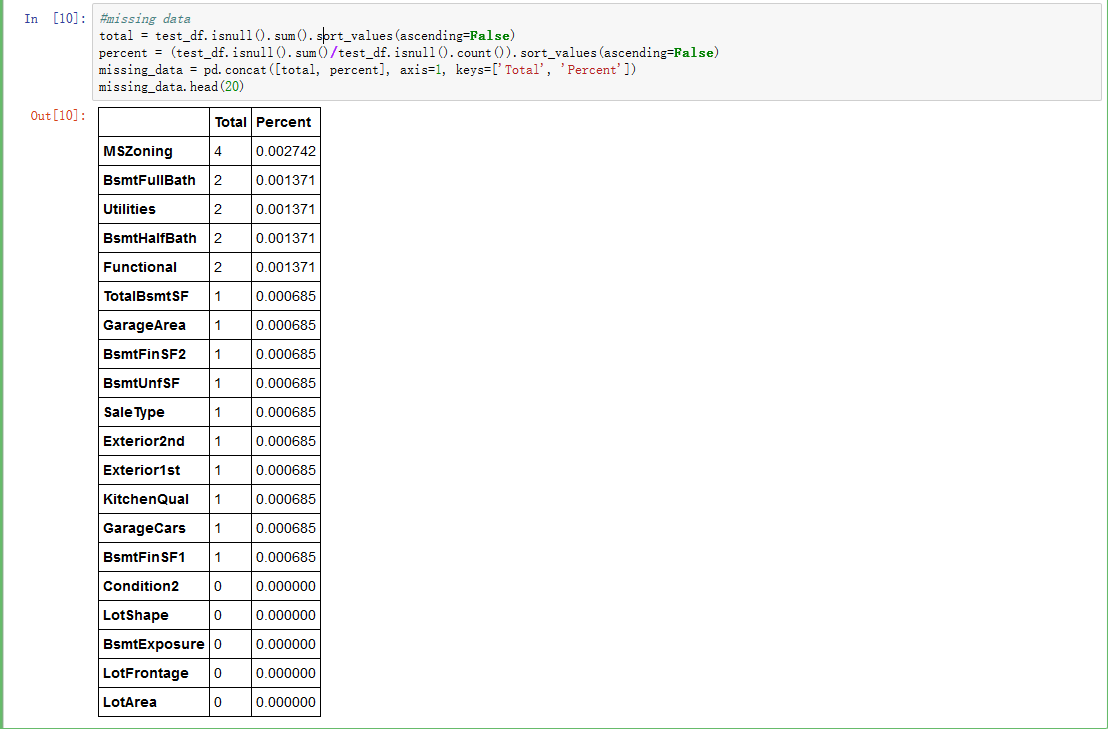
3.2 缺失值统计
训练集数据缺失情况, 和它们对应的意义为:

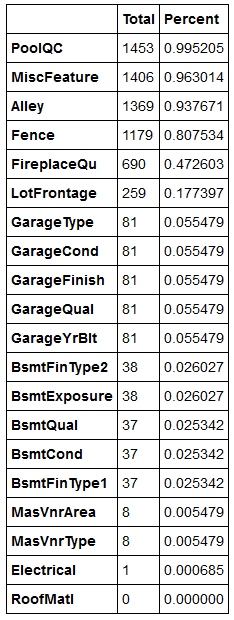
图3
3.3 填充缺失值
3.3.1 训练数据
缺失数据的变量有很多,处理情况可以分为如下几类:
(1)缺失多
直接数据集中剔除哪些存在大量缺失值的变量 缺失量比较多的PoolQC、MiscFeature、Alley、Fence、FireplaceQu是由于房子没有泳池、特殊的设施、旁边的小巷、篱笆、壁炉等设施。 由于缺失量比较多,缺失率超过40%,我们直接移除这几个变量。

(2)车库的属性
由于有些房子没有车库,造成车库相关的属性缺失,对于这种情况,我们有missing填充,同时对于车库建造时间的缺失,我们用1900填充,表示车库是年久的,使其变得不重要。
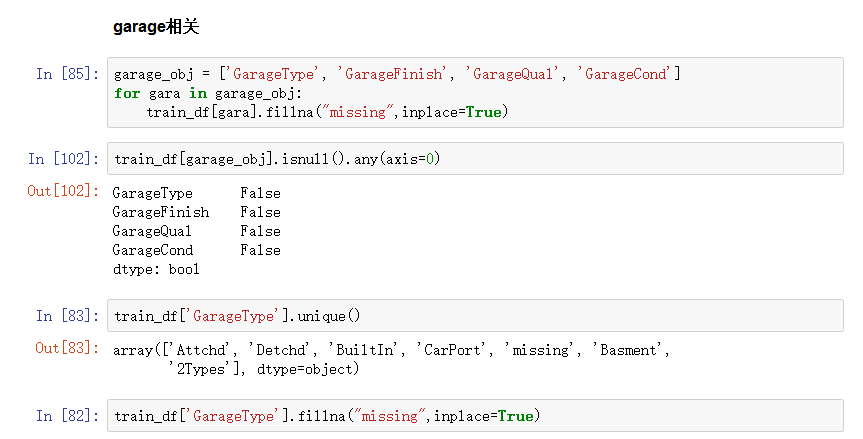

(3)与装修有关
有些房子重装修过,但是有些房子是没重装修过的,所有有关的属性可能确实。这是使用missing填充装修情况,用0填充装修面积。

(4)其它确实较少的属性
由于Electrical等属性缺失较少,可以使用众数填充:

3.3.2 测试数据
同理我们可以按照训练集处理方法来处理相同列:
回过头再看一下是否还有缺失值:
可以发现还有一部分仍然有缺失值,但缺失较少,我们可以以其众数填充
这样可以看到,测试集中无缺失值了。
3.4 格式转换
为了使得特征分析顺利进行,首先对字符串型的属性转换到数值型,其中,字符型的属性为:

转换的规则是:对于字符型属性,按照各个类型的属性的不同取值时房价的均值排高低,按此顺序从低往高,给属性的不同取值赋予1,2,3,4……,使得其变成数值型。

经过转换后的属性全部为数值型,这时有利于进行分析。
同时,我们构建非数值型属性—>数值型属性的映射表(mapping table),这样才能将该规律推广到测试集。

以上,我们就基于训练数据构建好了我们的映射表,由于映射表是一个张量类型,无法可视化,但我们可以针对一个属性来看映射表。
然后,我们再来将测试集里面的非数值型数据通过上面的到的映射表映射为数值型。

这样我们就将所有数据转换为了数值型数据了,方面我们以后的计算与分析。
四、特征分析
4.1 房价分析
首先对房价进行分析,画出房价的分布图为:
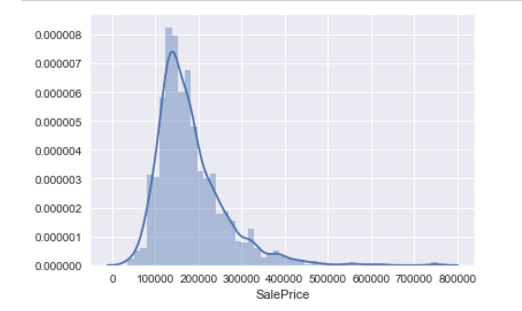
图4
从图中可以看出关于房价分布图有几个特点:
(1)偏离正态分布
(2)有明显的正偏态
(3)有峰值
进一步求得
偏度: 1.882876
峰度: 6.536282

我们可以知道,在数据中房价主要集中在区间[100000,300000]中,而有关小于100000,和大于300000的房价是偏向异常数据,在进一步考虑时,应该适当合理区分这些数据。
4.2 房价属性的关系
在此先分析房价与属性的关系,其中数值型的属性有,字符型的在上面已展示。
在定性前面分析知,面积等属性与房价是有关系的,下面将分析一下它们的关系,部分情况如图所示:




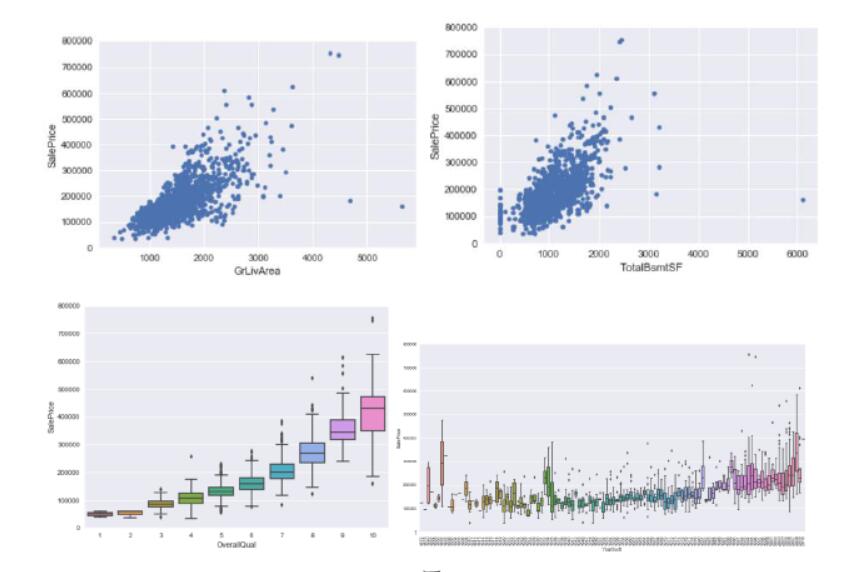
图5
从图中还是很明显地看出, “GrLivArea”和“TotalBsmtSF”似乎与“SalePrice”是线性相关的。这两种关系都是正的,这意味着当一个变量增加时,另一个变量也会增加。 “OverallQual”和“YearBuilt”似乎也与“SalePrice”有关。这种关系似乎在“Overallqual”的情况下更加强烈,在这种情况下,箱型图显示了销售价格是如何随着整体质量而增长的。
相同的情况分析其它属性得到与房价近似正相关关系的属性有:
Foundation、Heating、Electrical、SaleType、2ndFlrSF、SaleCondition、GarageArea、YearRemodAdd、ExterQual、BsmtFullBath、1stFlrSF、TotalBsmtSF、BsmtUnfSF、CentralAir、Neighborhood、GarageCars
4.3 相关性
首先进行对数值型的属性进行相关系数分析,期待发现它们之间的相关性。

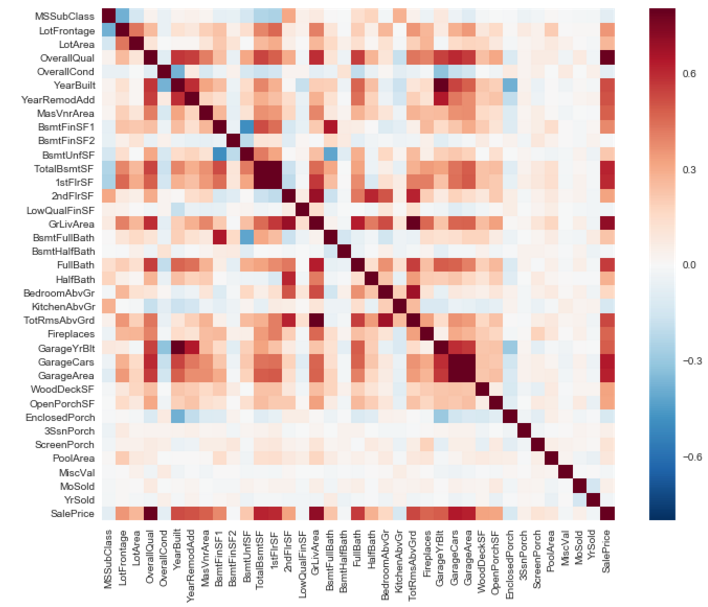
图6
这个热图是快速浏览特征与价格关系的最好方法。(颜色越深,对应的像个特征的相关性越大)
有两个红色的方块引起了我的注意。第一个是“TotalBsmtSF”和“1stFlrSF”变量,第二个是“GarageX”变量。这两种情况都显示了这些变量之间的相关性有多大。实际上,这种相关性是如此强烈,以至于它可以表明多线性的情况。如果我们考虑这些变量,我们可以得出结论,它们给出的信息几乎是相同的,所以多细胞性确实发生了。热图很好地发现了这种情况,在特征选择的主导问题中,像我们这样的问题,它们是必不可少的工具。
另一件引起我注意的事情是“SalePrice”的相关性。我们可以看到我们著名的“GrLivArea”,“TotalBsmtSF”,以及“OverallQual”与其具有很大相关性。但我们也可以看到许多其他的变量的颜色也很深,这些变量应该被考虑进去。这就是我们接下来要做的。
现在有上面热点图选择与SalePrice 相关性最大的9个特征,进一步分析它们的相关性。

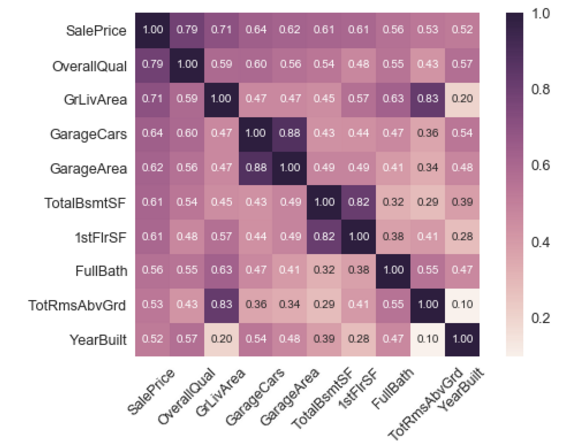
图7
这几个属性之间的信息是否互相包含?或者是,它们之间是否存在线性性?若存在,则可知只需要选取某些属性,就可以代表所有属性,而不必讲所有属性都考虑。

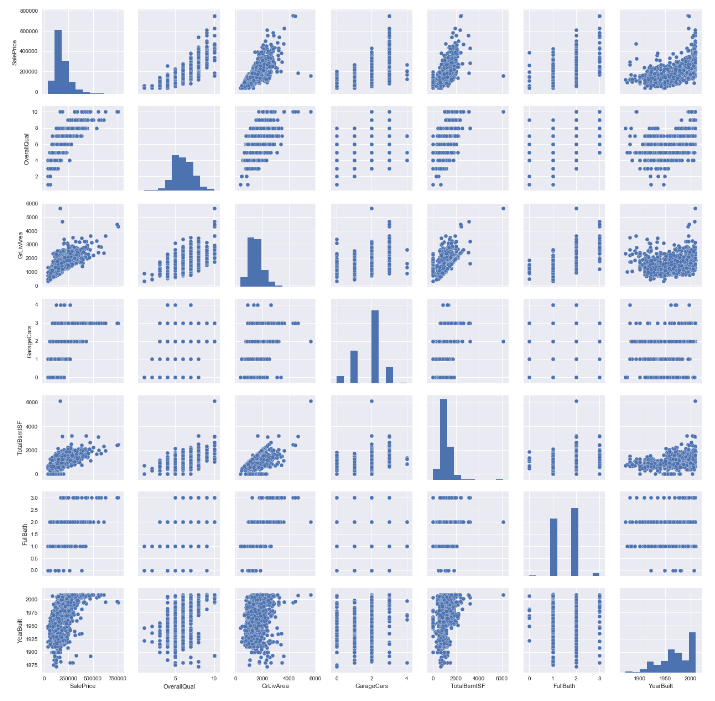
图8
从图中可以看出,确实有些属性之间信息重叠,如GrLivArea 和OverallQual之间就存在正相关性,还有GrLivArea和TotalBsmtSF之间也存在正相关性,OverallQual和TotalBsmtSF存在较弱的正相关性。定性分析可知,地下室面积TotalBsmtSF与居住面积当然有关系,除去没有地下室的极少数房子,其它房子地下室面积大,伴随着房子面积大,反过来也成立。
进一步采用皮尔逊相关分析法对所有属性和房价进行分析:


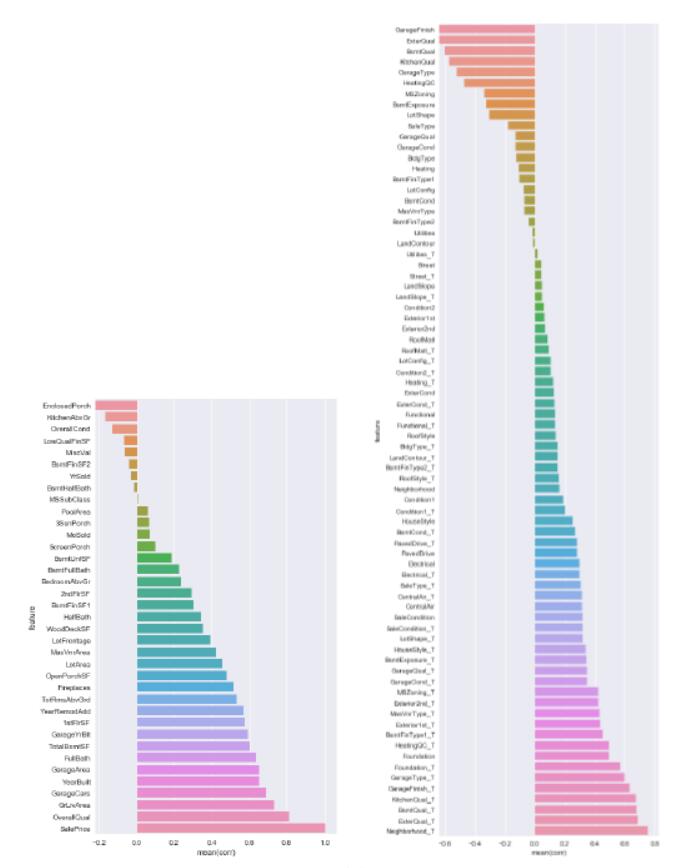
图9
可以清楚地看出与房价高度相关的属性有:
OverallQual、Foundation、Heating、Electrical、SaleType、2ndFlrSF、SaleCondition、GarageArea、YearRemodAdd、YearBuilt、ExterQual、BsmtFullBath、1stFlrSF、TotalBsmtSF、BsmtUnfSF、CentralAir、Neighborhood、GarageCars、GrLivArea
4.4 特征选取
根据以上讨论,去掉部分互相相关性强的属性,选择作为房价分析的特征有:
OverallQual、Foundation、Heating、Electrical、SaleType、2ndFlrSF、SaleCondition、GarageArea、YearRemodAdd、YearBuilt、ExterQual、BsmtFullBath、1stFlrSF、TotalBsmtSF、BsmtUnfSF、CentralAir、Neighborhood、GarageCars、
因为所有属性我们都已经度量化了,所以直接拿来计算。

选取与价格的斯格尔曼相关系数较高的几个(spr>0.5)。
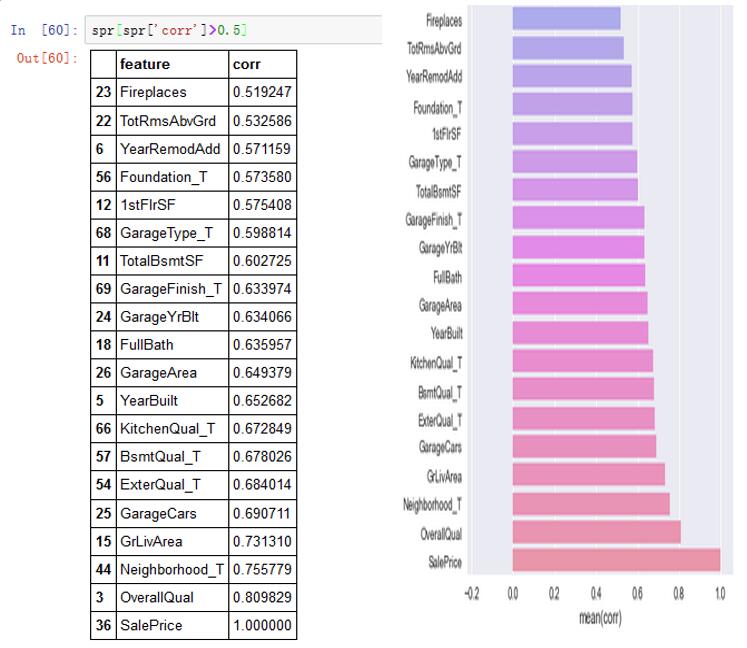
图10
可知选取与价格的斯格尔曼相关系数大于0.5的有:
Fireplaces、YearRemodAdd、1stFlrSF、TotalBsmtSF、BsmtUnfSF、CentralAir、Neighborhood、Foundation、GarageArea、YearBuilt、GarageCars、BsmtFullBath、OverallQual、ExterQual、SaleType等这些
五、回归和提交
5.1 评分标准
评分标准是均方根误差(RMSE),即是:
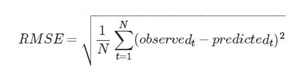
5.2 利用斯格尔曼系数较高的特征
在此,选取斯格尔曼系数较高的,相关性较高的特征:

利用线性回归、AdaBoost回归,剩余树回归和随机提升回归来预测,得到对应的结果,上传到kaggle:
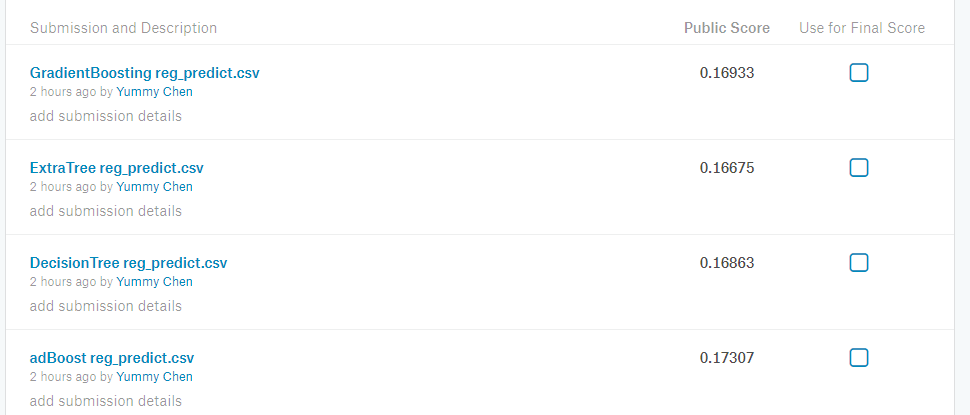
图11
由图中可见到,GradientBoosting Reression 的效果最好。
提交结果为:0.16933
排名:2000+
5.3 全部特征回归
5.3.1 交叉验证
在此,使用已经预处理后的全部特征进行回归。
首先,回归的方法有:
(1)k近邻回归;
(2)逻辑回归;
(3)朴素贝叶斯;
(4)决策树回归;
(5)随机深林回归;
(6)支持向量机回归;
(7)线性回归;
(8)AdaBoost回归;
(9)剩余树回归;
(10)随机提升回归。
为了解这些回归方法的优劣势,分别使用他们进行预测。
首先,使用k近邻回归、逻辑回归、朴素贝叶斯、决策树回归、随机深林回归、支持向量机回归对训练集进行交叉验证回归预测:
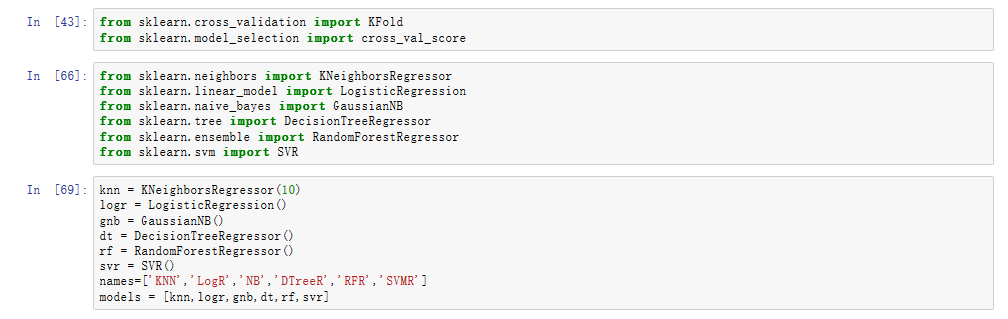
分别进行五折交叉:
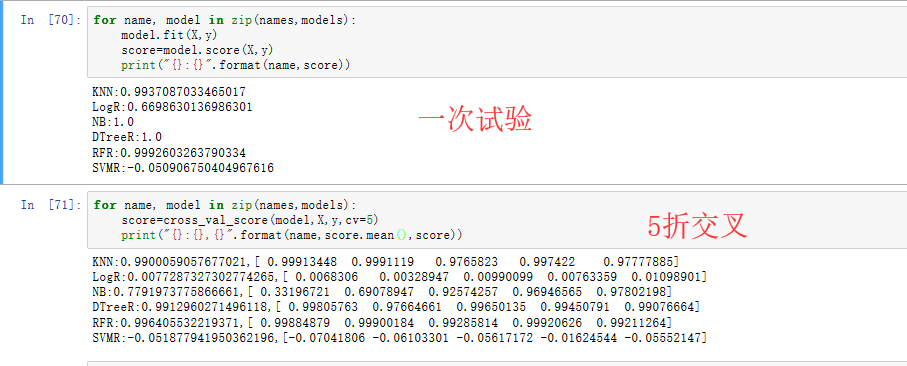
可以看到决策树回归(正确率:0.9912)和随机深林回归(正确率:0.99640)效果较好。
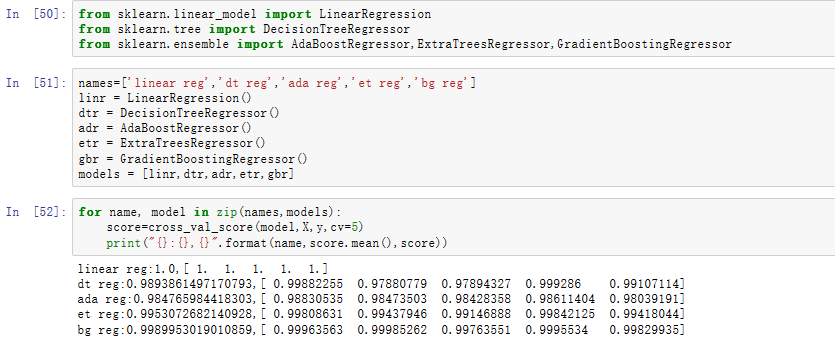
由图中可见,从训练集结果上看来效果都挺不错。其中,效果最好的是梯度提升回归(正确率:0.99899),其次是剩余树回归(正确率:0.99530)。
5.3.2 回归预测
综合上述的10种回归方法,在交叉验证中发现效果较好的有:线性回归、决策树回归、AdaBoost回归、剩余树回归、随机提升回归。
将这几种回归方法应用于测试集上:
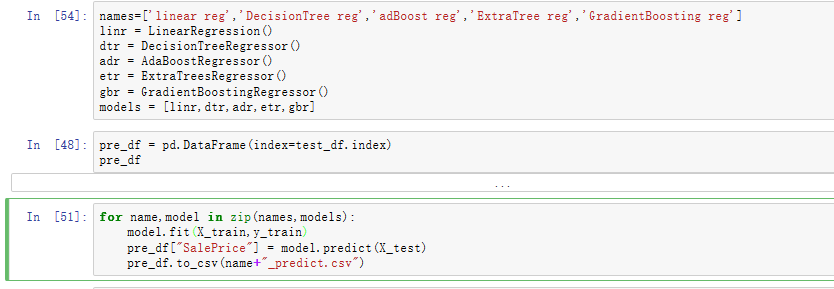
求解得回归结果,两个剩余树和梯度提升效果较好,提交到kaggle上:
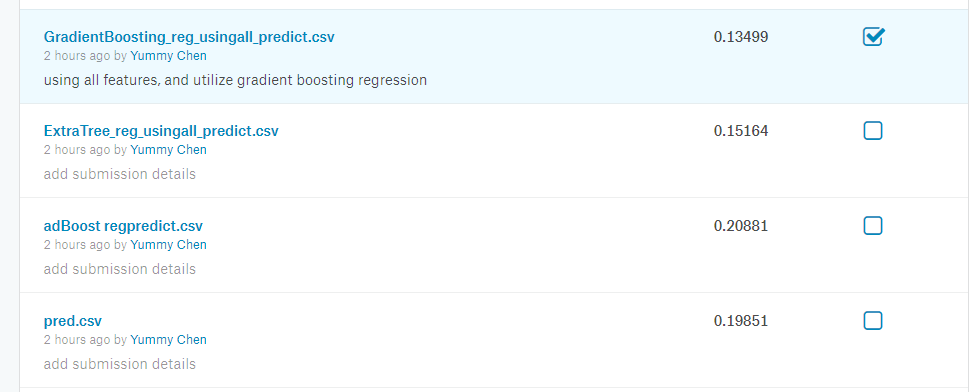
图12
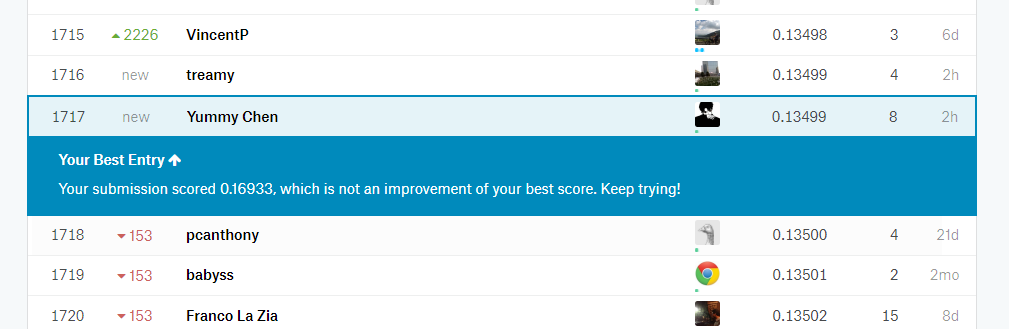
图13
其中,梯度上升回归法的效果最好,最佳得分为:
提交结果为:0.13499
排名:1717/4919(前35%)。
六、总结与展望
(1)房价预测这个题目看似简单,实质上很有难度,主要是属性很多,而且缺失值也很多,数据预处理有难度。
(2)本文进行数据预处理考虑还简单,可以继续考虑属性间的线性关系程度,以及属性间合并,或属性分拆等。
(3)对于结果,我们还是满意的,经过一番尝试后,排名为45%。若要继续提升,一个方向是将数据集继续分类,分为三类或更多。
七、参考文献
[1]周志华.机器学习[M].北京:清华大学出版社,2016.
[2]Peter Harrington.机器学习实战[M].北京:人民邮电出版社,2013.
[3]韩家炜等.数据挖掘概念与技术[M].北京:机械工业出版社,2012.
[4] House Prices: Advanced Regression Techniques,
https://blog.csdn.net/ns2250225/article/details/72626155
[5] Kaggle房价预测:数据预处理——练习,
https://blog.csdn.net/qilixuening/article/details/75153131