一、项目背景
项目描述:比赛项目由 Kaggle 举办,要求选手依据爱荷华州房子的质量、面积、街区、壁炉个数等79个变量预测房子的价格。
项目网址:House Prices: Advanced Regression Techniques
二、代码展示
tips:原代码在jupyter notebook上由python编写完成
# Kaggle房价预测项目
# 首先,导入需要用到的包
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn
from scipy import stats
from scipy.stats import norm, skew
# 读取数据集
train = pd.read_csv('E:/房价预测项目/train.csv')
test = pd.read_csv('E:/房价预测项目/test.csv')
1.对数据集进行可视化探索
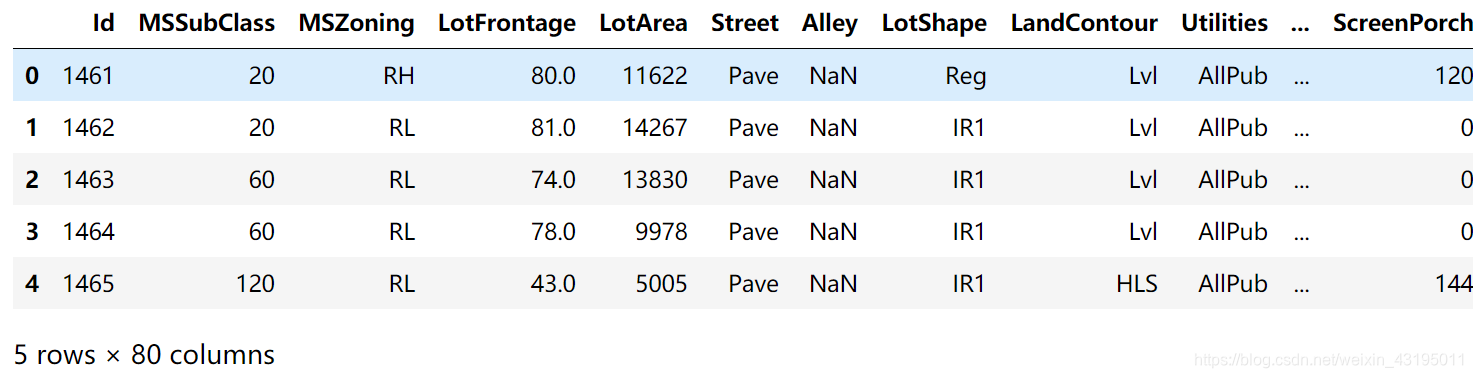
train.head(5)
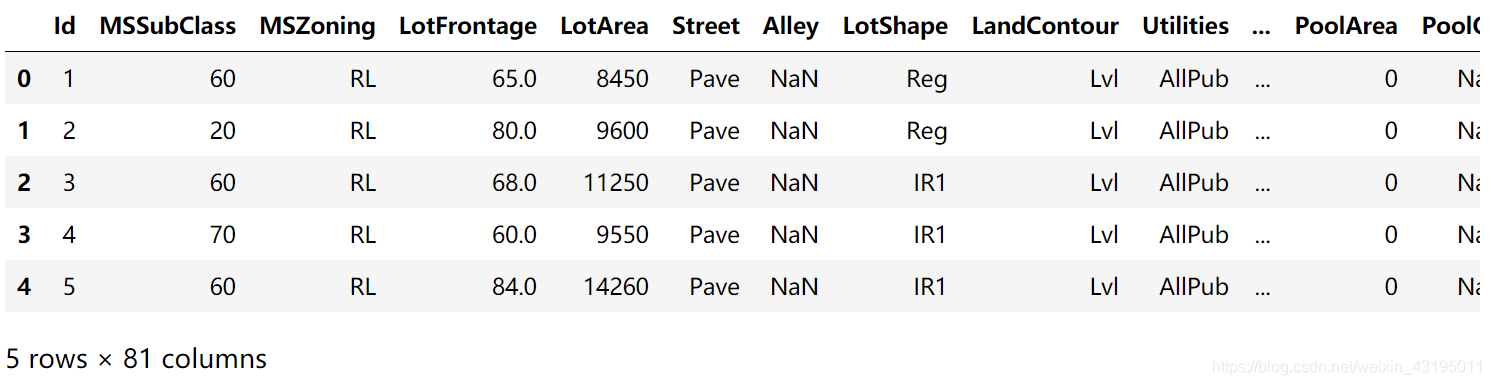
test.head(5)
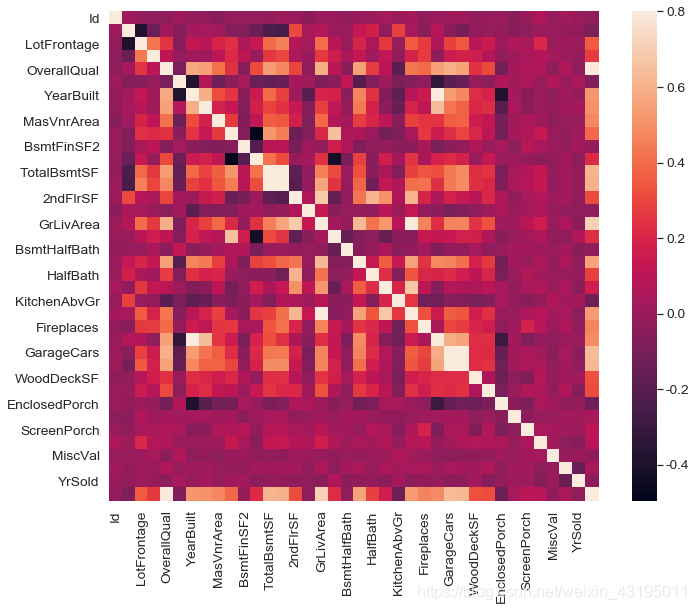
# 对训练集train做相关性探索
corrmat = train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True)
#选出10个与房价相关性最强的变量查看相关性系数
k = 10 #选择变量的个数
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(train[cols].values.T) #
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={
'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
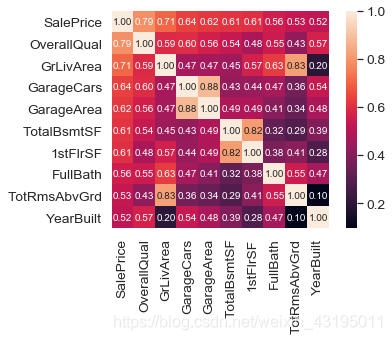
通过上面的热力图,可以得到如下的结论:
1.‘OverallQual’, ‘GrLivArea’ 和 'TotalBsmtSF’与房价的相关性很强,可以后面再深入探索
2.‘GarageCars’(车库能放多少量车) 和 ‘GarageArea’ (车库面积)和房价同样有比较强的相关性,但这两个变量本身的相关性也很强,因为车库面积和车库能放多少车本身就是有强相关性的,可能存在多重共线性问题,可以去掉一个
3.‘TotalBsmtSF’ 和 ‘1stFloor’ 似乎都是代表地下室面积,这里不确定这两个变量含义的区别,不过它们也有很强的相关性,考虑去掉一个
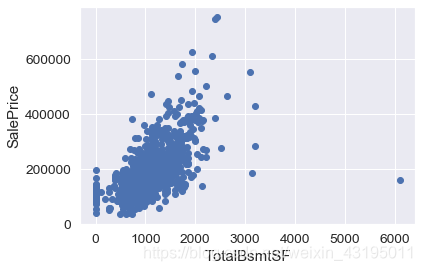
#TotalBsmtSF含义为地下室面积,发现地下室面积与房价似乎有更强的潜在线性关系,同时在右侧似乎也有一个异常值存在
fig, ax = plt.subplots()
ax.scatter(x=train.TotalBsmtSF,y=train.SalePrice)
plt.xlabel('TotalBsmtSF')
plt.ylabel('SalePrice')
plt.show()
# 可以看到有一个异常点在右下方
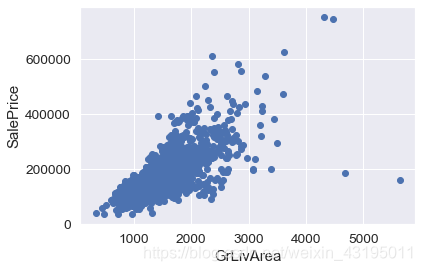
# GrLivArea为居住面积,发现有强相关关系,发现右边有2个异常点
fig, ax = plt.subplots()
ax.scatter(x=train.GrLivArea,y=train.SalePrice)
plt.xlabel('GrLivArea')
plt.ylabel('SalePrice')
plt.show()
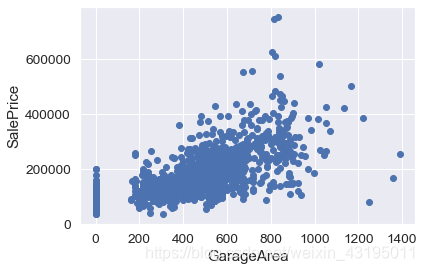
# GarageArea为车库面积,发现有正相关关系
fig, ax = plt.subplots()
ax.scatter(x=train.GarageArea,y=train.SalePrice)
plt.xlabel('GarageArea')
plt.ylabel('SalePrice')
plt.show()
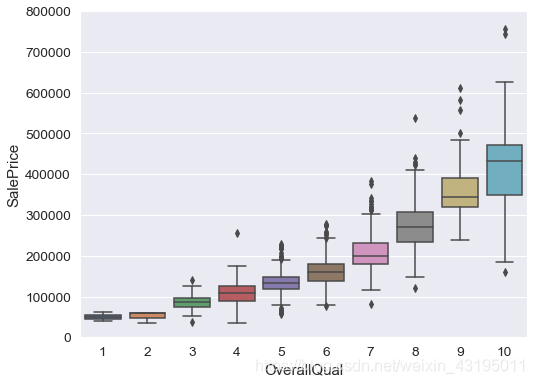
# 房屋质量与房价从经验上应该是强相关,可视化进行验证
var = 'OverallQual'
data = pd.concat([train['SalePrice'], train[var]], axis=1)
f, ax = plt.subplots(figsize=(8, 6))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);
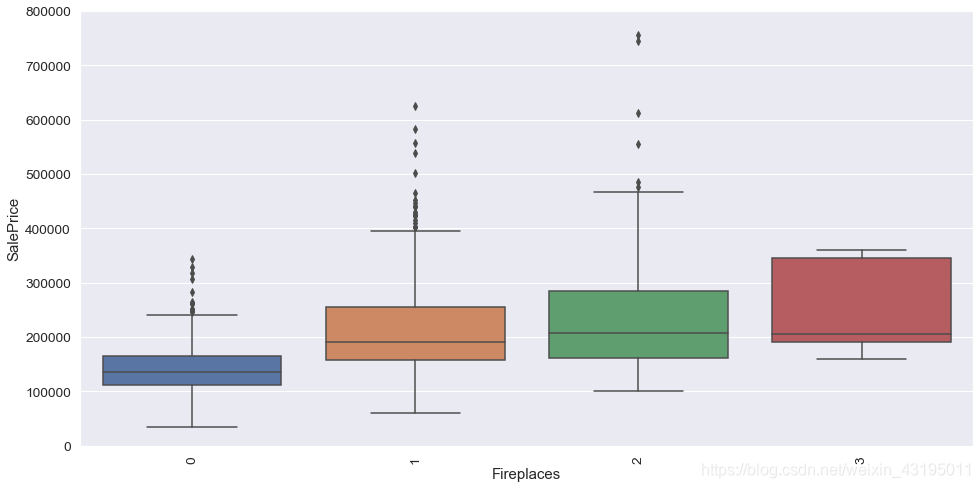
# 可以再看一下壁炉数量和房价的关系,发现壁炉越多,房价越高
var = 'Fireplaces'
data = pd.concat([train['SalePrice'], train[var]], axis=1)
f, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000)
plt.xticks(rotation=90)
2.数据预处理
# 1.首先对train进行处理,删除可视化中出现的异常值
train = train.drop(train[(train['TotalBsmtSF']>5000) & (train['SalePrice']<200000)].index)
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<200000)].index)
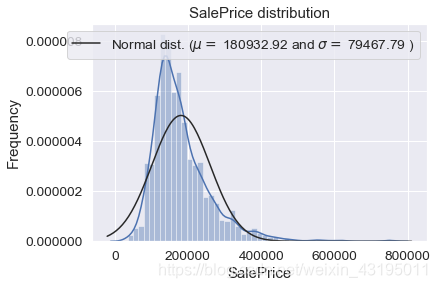
# 作图发现房价的分布是右偏的,根据前提假设需要做相应的转换使其符合正态分布
sns.distplot(train['SalePrice'] , fit=norm);
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
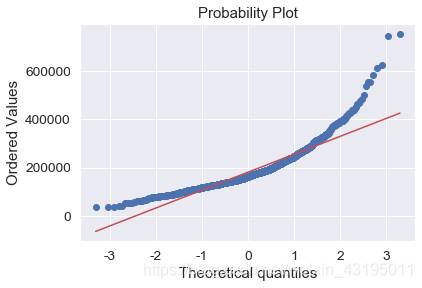
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()
mu = 180932.92 and sigma = 79467.79
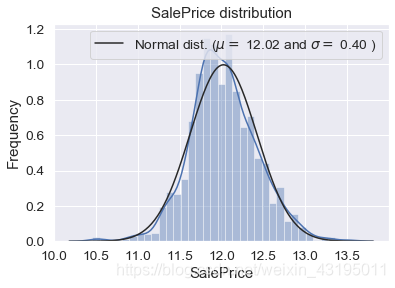
# 这里采用对数变换的方法使其符合正态分布
train["SalePrice"] = np.log(train["SalePrice"])
sns.distplot(train['SalePrice'] , fit=norm);
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
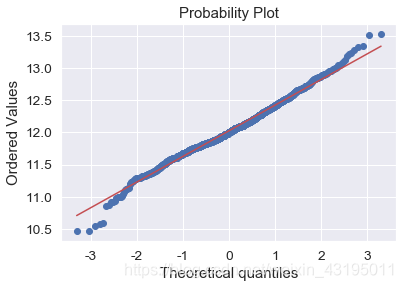
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()
mu = 12.02 and sigma = 0.40
# 2.将train和test联合起来一起进行数据处理
train_id = train['Id']
test_id = test['Id']
ntrain = train.shape[0]
ntest = test.shape[0]
y_train = train.SalePrice.values
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape)) # all_data size is : (2917, 80)
# 由于ID对预测没有作用,删除ID字段
all_data.drop(['Id'], axis=1, inplace=True)
# 查看缺失值比率
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na==0].index).sort_values(ascending=False)[:30]
all_data_na
missing_data = pd.DataFrame({
'missing_data' : all_data_na})
missing_data.head(20)

#将缺失度用图表的方式展示
f, ax = plt.subplots(figsize=(15, 12))
plt.xticks(rotation='90')
sns.barplot(x=all_data_na.index, y=all_data_na)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
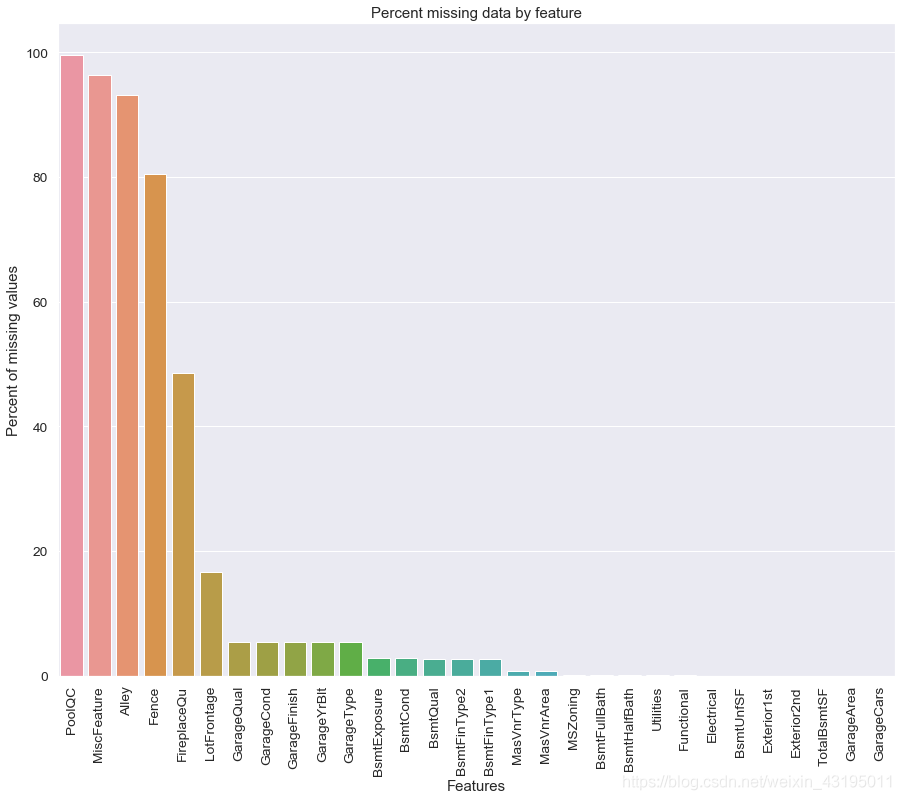
# 对于缺失率在80%以上的特征删除
all_data = all_data.drop('PoolQC', axis=1)
all_data = all_data.drop('MiscFeature', axis=1)
all_data = all_data.drop('Alley', axis=1)
all_data = all_data.drop('Fence', axis=1)
all_data.shape # (2917, 75)
# 对于其他缺失值进行处理, 壁炉为空可能是没有,用none填充
all_data['FireplaceQu'] = all_data['FireplaceQu'].fillna('none')
# LotFrontage代表房屋前街道的长度, 房屋前街道的长度应该和一个街区的房屋相同,可以取同一个街区房屋的街道长度的平均值
all_data['LotFrontage'] = all_data.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 对于Garage类的4个特征,缺失率一致,一起处理,可能是没有车库,用none填充
for c in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[c] = all_data[c].fillna('none')
# 对于garage,同样猜测缺失值缺失的原因可能是因为房屋没有车库,连续型变量用0填充
for c in ( 'GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[c] = all_data[c].fillna(0)
#对于地下室相关的连续变量,缺失同样认为房屋可能是没有地下室,用0填充
for c in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[c] = all_data[c].fillna(0)
#地下室相关离散变量,同理用None填充
for c in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[c] = all_data[c].fillna('None')
# Mas为砖石结构相关变量,缺失值我们同样认为是没有砖石结构,用0和none填补缺失值
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)
#MSZoning代表房屋所处的用地类型,先看下不同取值
all_data.groupby('MSZoning')['MasVnrType'].count().reset_index()
# 由于业务上房屋类型是必须的,一般都有,考虑用众数填充
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
# 由于数据Functional缺失即为Typ,所以进行填充Typ
all_data["Functional"] = all_data["Functional"].fillna("Typ")
# 对于Utilities,观察到除了一个“NoSeWa”和2个NA之外,所有记录都是“AllPub”,对于房价预测用处很小,删除这个特征
all_data.drop(['Utilities'], axis=1, inplace=True)
查看剩余的缺失值:
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na==0].index).sort_values(ascending=False)[:30]
all_data_na
missing_data = pd.DataFrame({
'missing_data' : all_data_na})
missing_data
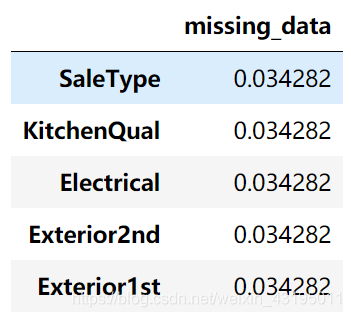
# 填充剩余的缺失值
for i in missing_data.index:
print(all_data[i].head()) #未展示
for i in ( 'SaleType', 'KitchenQual', 'Electrical', 'Exterior2nd','Exterior1st'):
all_data[i] = all_data[i].fillna(all_data[i].mode()[0])
# 查看缺失值的比率,发现已经处理完毕,all_data里已经没有缺失值
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na==0].index).sort_values(ascending=False)[:30]
all_data_na
missing_data = pd.DataFrame({
'missing_data' : all_data_na})
missing_data

3.特征工程
特征工程可以说是最重要的步骤了,机器学习大佬吴恩达说过:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”
# 对于一些数值型特征,数值并不表示大小,将其值转换为字符型
all_data['MSSubClass'] = all_data['MSSubClass'].apply(str)
all_data['OverallCond'] = all_data['OverallCond'].astype(str)
all_data['YrSold'] = all_data['YrSold'].astype(str)
all_data['MoSold'] = all_data['MoSold'].astype(str)
创造一些特征:
# 将地下室面积、1楼面积、2楼面积相加得到总面积特征
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']
# 由前面的可视化将房子建造时间做一个划分,以1990进行划分,1990前为0,1990后为1
all_data['YearBuilt_cut'] = all_data['YearBuilt'].apply(lambda x: 1 if x>1990 else 0)
all_data['Total_sqr_footage'] = (all_data['BsmtFinSF1'] + all_data['BsmtFinSF2'] +
all_data['1stFlrSF'] + all_data['2ndFlrSF'])
all_data['Total_Bathrooms'] = (all_data['FullBath'] + (0.5 * all_data['HalfBath']) +
all_data['BsmtFullBath'] + (0.5 * all_data['BsmtHalfBath']))
all_data.shape # (2917, 79)
# 将all_data分开为训练集与测试集两部分,查看新特征与房价的相关性
new_train = all_data[:ntrain]
new_test = all_data[ntrain:]
new_train['SalePrice'] = y_train
# 画图查看新的总面积特征和房价的线性相关性,发现有强相关性,是一个比较好的新特征
fig, ax = plt.subplots()
ax.scatter(x=new_train['TotalSF'], y=new_train['SalePrice'])
plt.xlabel('TotalSF', fontsize=12)
plt.ylabel('SalePrice', fontsize=12)
# 发现有右下角有两个异常点,考虑删除
new_train = new_train.drop(new_train[(new_train['TotalSF']>7000) & (new_train['SalePrice']<200000)].index)
plt.show()

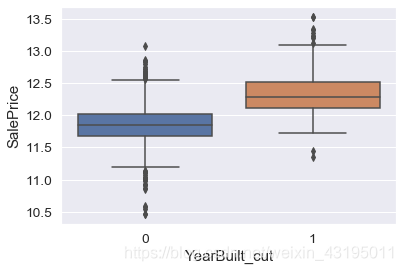
# 观察建筑年限不同导致的房价差异
yearb = 'YearBuilt_cut'
data = pd.concat([new_train['SalePrice'], new_train[yearb]], axis=1)
fig, ax = plt.subplots()
f = sns.boxplot(x=yearb, y='SalePrice', data=data)
# 发现房价在建筑年限上有较大的分布差异
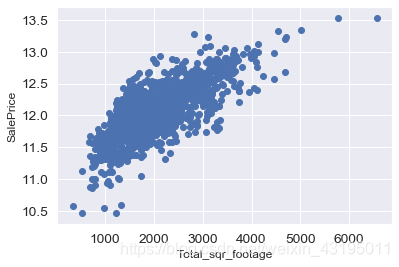
# 查看Total_sqr_footage与房价的相关性
fig, ax = plt.subplots()
ax.scatter(x=new_train['Total_sqr_footage'], y=new_train['SalePrice'])
plt.xlabel('Total_sqr_footage', fontsize=12)
plt.ylabel('SalePrice', fontsize=12)
plt.show()
# 发现有强相关性
# 查看Total_Bathrooms与房价的相关性
bath_num = 'Total_Bathrooms'
data = pd.concat([new_train['SalePrice'], new_train[bath_num]], axis=1)
fig, ax = plt.subplots()
f = sns.boxplot(x=bath_num, y='SalePrice', data=data)

# 观察到Total_Bathrooms等于5或6时都只有一行,且对应房价较为异常,删除这两个值
new_train.loc[:, 'Total_Bathrooms'].value_counts()
new_train = new_train.drop(new_train[new_train['Total_Bathrooms'] >= 5.0].index)
# 将new_train与new_test重新组合成all_data进行数据的统一处理
ntrain = new_train.shape[0]
ntest = new_test.shape[0]
y_train = new_train.SalePrice.values
all_data = pd.concat((new_train, new_test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape)) # all_data size is : (2915, 78)
对特征进行编码:
# 对有序性离散变量使用label encoder 进行编码
from sklearn.preprocessing import LabelEncoder
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
for c in cols:
lbe = LabelEncoder()
lbe.fit(list(all_data[c].values))
all_data[c] = lbe.transform(list(all_data[c].values))
print(all_data.shape) # (2915, 78)
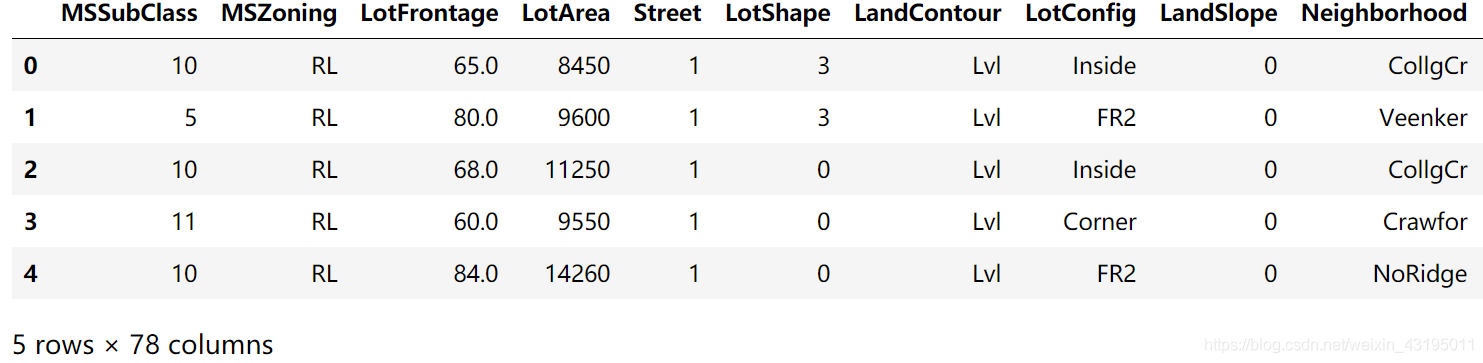
all_data.head(5)
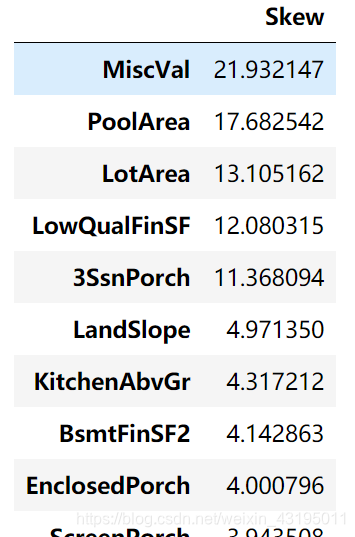
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
# 查看所有数字特征的偏度
skewed_feats = all_data[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({
'Skew' :skewed_feats})
skewness.head(10)
# 查看有多少特征的偏度不符合要求,并进行转换
skewness = skewness[abs(skewness) > 0.75]
print("有{}个特征需要转换 ".format(skewness.shape[0]))
# 有59个特征需要转换
from scipy.special import boxcox1p
skewed_features = skewness.index
lam = 0.15
for feat in skewed_features:
#all_data[feat] += 1
all_data[feat] = boxcox1p(all_data[feat], lam)
# 将无序型离散变量转化为哑变量(one-hot编码)
all_data = pd.get_dummies(all_data)
为了避免多重共线性问题,删除皮尔森系数大于0.9的特征:
shreshold = 0.9
corr_all_data = all_data.corr().abs()
# 取矩阵的上三角部分,判断系数大于0.9的并删除
data_up = corr_all_data.where(np.triu(np.ones(corr_all_data.shape), k=1).astype(np.bool))
drop_col = [ column for column in data_up.columns if any(data_up[column] > 0.9)]
all_data = all_data.drop(columns=drop_col)
all_data.shape # (2915, 207)
# 将训练集与测试集分开,用于建模与测试
train = all_data[:ntrain]
test = all_data[ntrain:]
train.head()
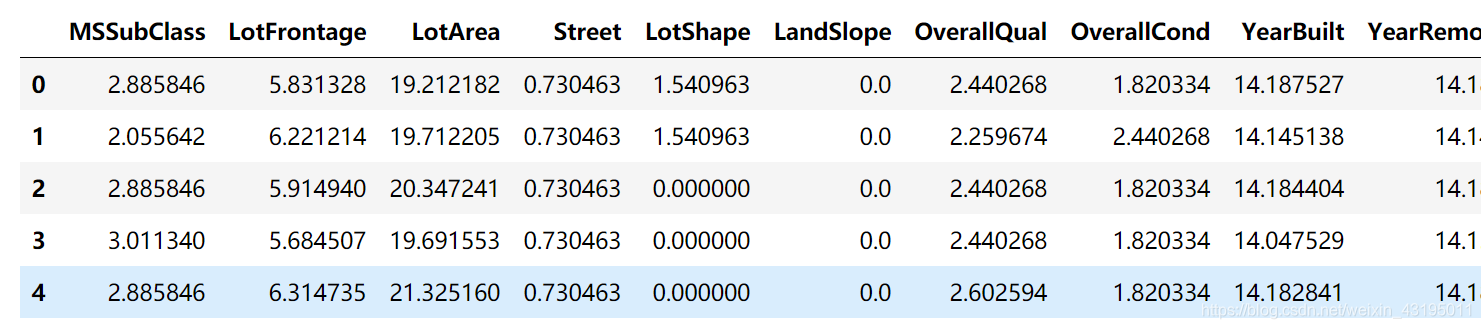
四、建模与预测
采用岭回归-Ridge Regression模型进行建模与预测
(还可以尝试使用其他模型进行对比,如随机森林)
# 导入模型相关的库
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
def rmse_cv(model):
rmse= np.sqrt(-cross_val_score(model, train, y_train, scoring="neg_mean_squared_error", cv = 5))
return(rmse)
#导入ridge模型
model_ridge = Ridge()
# 对超参数取值进行猜测和验证
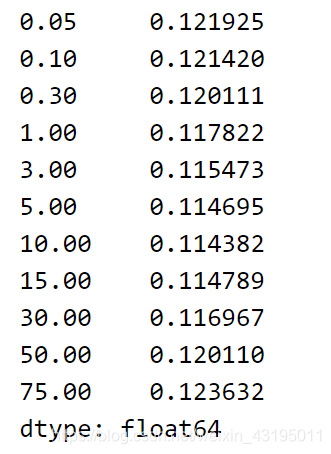
alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean() for alpha in alphas]
# 画图查看不同超参数的模型的分数
cv_ridge = pd.Series(cv_ridge, index = alphas)
cv_ridge.plot(title = "Validation - Just Do It")
plt.xlabel("alpha")
plt.ylabel("rmse")
cv_ridge
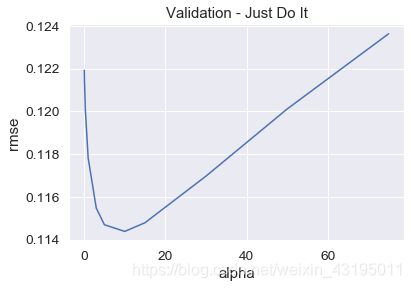
# alpha参数用我们之前验证过的10,然后用训练集对模型进行训练
clf = Ridge(alpha=10)
clf.fit(train,y_train)
# 输出 Ridge(alpha=10, copy_X=True, fit_intercept=True, max_iter=None, normalize=False,random_state=None, solver='auto', tol=0.001)
# 对测试集进行预测,并导出结果
predict = clf.predict(test)
test_pre = pd.DataFrame()
test_pre['ID'] = test_id
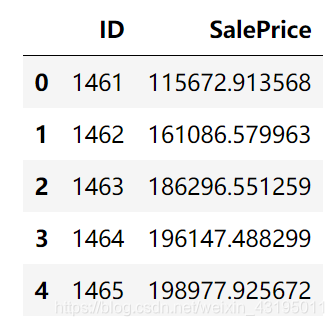
test_pre['SalePrice'] = np.exp(predict)
test_pre.to_csv('submission.csv', index=False)
test_pre.head()