参考文章:kaggle比赛:房价预测(排名前4%)
1. Baseline
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelBinarizer
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import FeatureUnion
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
train = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")
# RangeIndex: 1460 entries, 0 to 1459
# Data columns (total 81 columns):
1. 特征选择
- 数据有79个特征,我们选出相关系数最高的10个
abs(train.corr()['SalePrice']).sort_values(ascending=False).plot.bar()
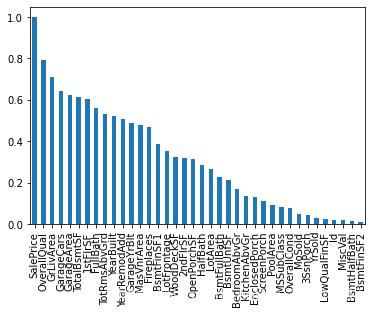
most_10_important = abs(corrmat["SalePrice"]).sort_values(ascending=False)[1:11].index
最相关的特征 ['OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', otalBsmtSF', '1stFlrSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt', 'YearRemodAdd']
2. 异常值剔除
- 部分数据异常,删除
sns.pairplot(x_vars=most_10_important[0:5], y_vars=['SalePrice'], data=train, dropna=True)
sns.pairplot(x_vars=most_10_important[5:], y_vars=['SalePrice'], data=train, dropna=True)
# help(sns.pairplot)
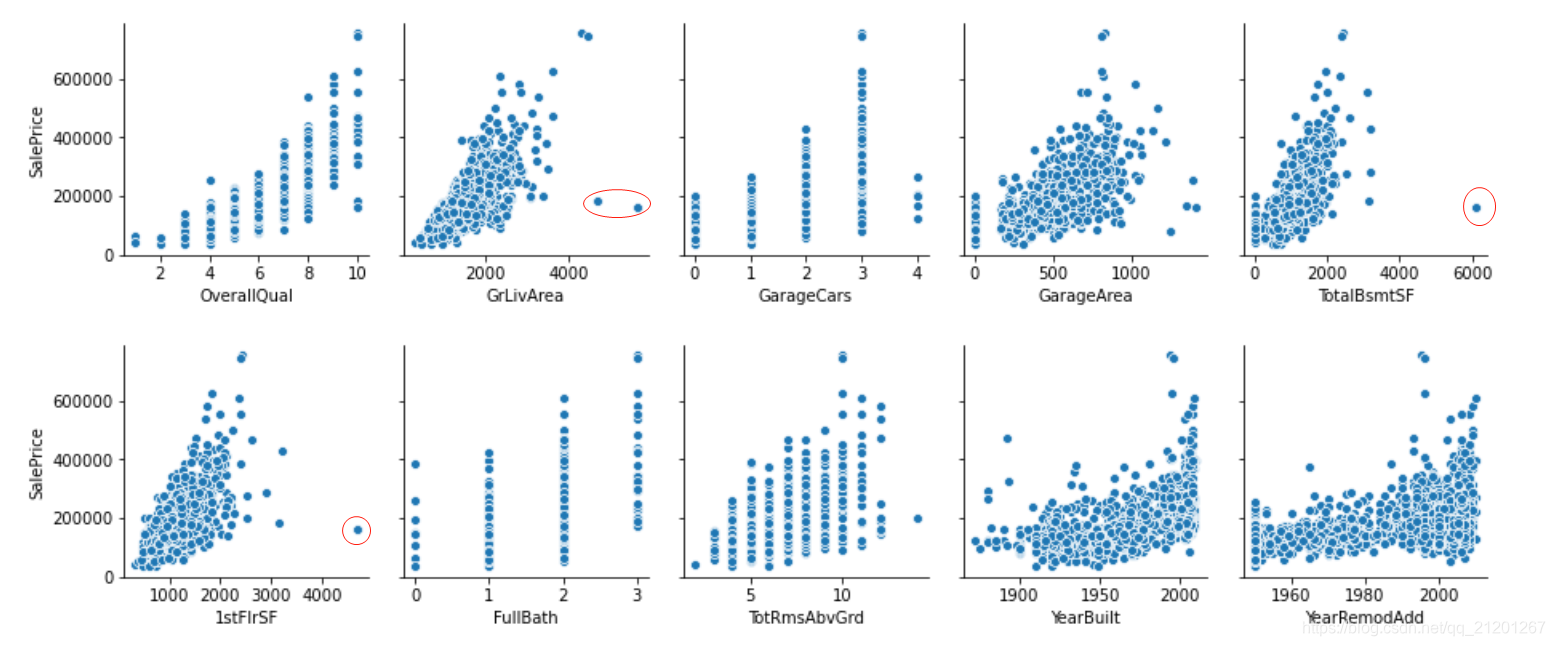
#删除异常值
train = train.drop(train[(train['OverallQual']<5)&(train['SalePrice']>200000)].index)
train = train.drop(train[(train['GrLivArea']>4000)&(train['SalePrice']<300000)].index)
train = train.drop(train[(train['YearBuilt']<1900)&(train['SalePrice']>400000)].index)
train = train.drop(train[(train['TotalBsmtSF']>6000)&(train['SalePrice']<200000)].index)
sns.pairplot(x_vars=most_10_important[0:5], y_vars=['SalePrice'], data=train, dropna=True)
sns.pairplot(x_vars=most_10_important[5:], y_vars=['SalePrice'], data=train, dropna=True)
# help(sns.pairplot)
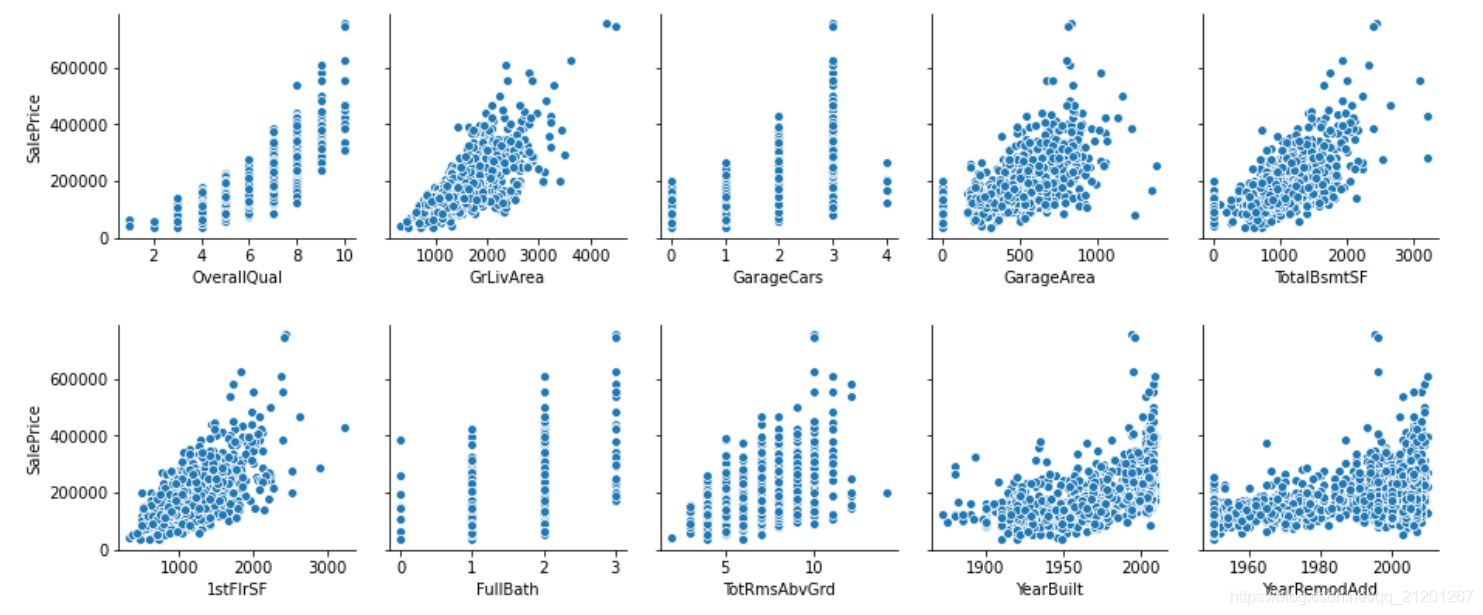
X_train = train[most_10_important]
X_test = test[most_10_important]
y_train = train['SalePrice']
- 年份数据作为文字变量
X_train['YearBuilt'] = X_train['YearBuilt'].astype(str)
X_train['YearRemodAdd'] = X_train['YearRemodAdd'].astype(str)
X_test['YearBuilt'] = X_test['YearBuilt'].astype(str)
X_test['YearRemodAdd'] = X_test['YearRemodAdd'].astype(str)
def num_cat_splitor(X_train):
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
num_cols = list(set(X_train.columns) - set(object_cols))
return num_cols, object_cols
num_cols, object_cols = num_cat_splitor(X_train)
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_cols)),
('imputer', SimpleImputer(strategy="median")),
('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(object_cols)),
('cat_encoder', OneHotEncoder(sparse=False,handle_unknown='ignore')),
])
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
X_prepared = full_pipeline.fit_transform(X_train)
3. 建模预测
prepare_select_and_predict_pipeline = Pipeline([
('preparation', full_pipeline),
('forst_reg', RandomForestRegressor(random_state=0))
])
param_grid = [{
'preparation__num_pipeline__imputer__strategy': ['mean', 'median', 'most_frequent'],
'forst_reg__n_estimators' : [50,100, 150, 200,250,300,330,350],
'forst_reg__max_features':[45,50, 55, 65]
}]
grid_search_prep = GridSearchCV(prepare_select_and_predict_pipeline, param_grid, cv=7,
scoring='neg_mean_squared_error', verbose=2, n_jobs=-1)
grid_search_prep.fit(X_train,y_train)
grid_search_prep.best_params_
final_model = grid_search_prep.best_estimator_
y_pred_test = final_model.predict(X_test)
result = pd.DataFrame()
result['Id'] = test['Id']
result['SalePrice'] = y_pred_test
result.to_csv('housing_price_10_features.csv',index=False)

得分:19154.16762