哈深《机器学习》project之kaggle房价预测
一、序
project内容就是kaggle上的一个比赛,据说是个经典的入门级项目,最适合我这种新手。详情链接:
https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
首先在组里的服务器上搭jupyter notebook环境就花了很久,同门以前安过,所以帮我节省了很多时间。(后来自己在VSCode上也整好了,VSCode香啊。但我发现VSCode上运行很慢,并且尝试“RUN ALL ABOVE”时如果上面的cell太多会崩)
一开始成绩是0.115,最后调到0.11475。后来发现大家都是用的排行榜前几名的代码做baseline,我这个成绩就很普通了。
二、基础知识
首次实操数据科学的代码,要学的基础知识很多。
2.1 stacking model
第一次做这种机器学习的东西,很多东西不知道,以下均为我个人查阅资料后的看法:
这个模型是想把不同的模型结合起来,取长补短达到更好的效果。
从别的博客看到两张图像,可以很好地帮助理解这个模型:
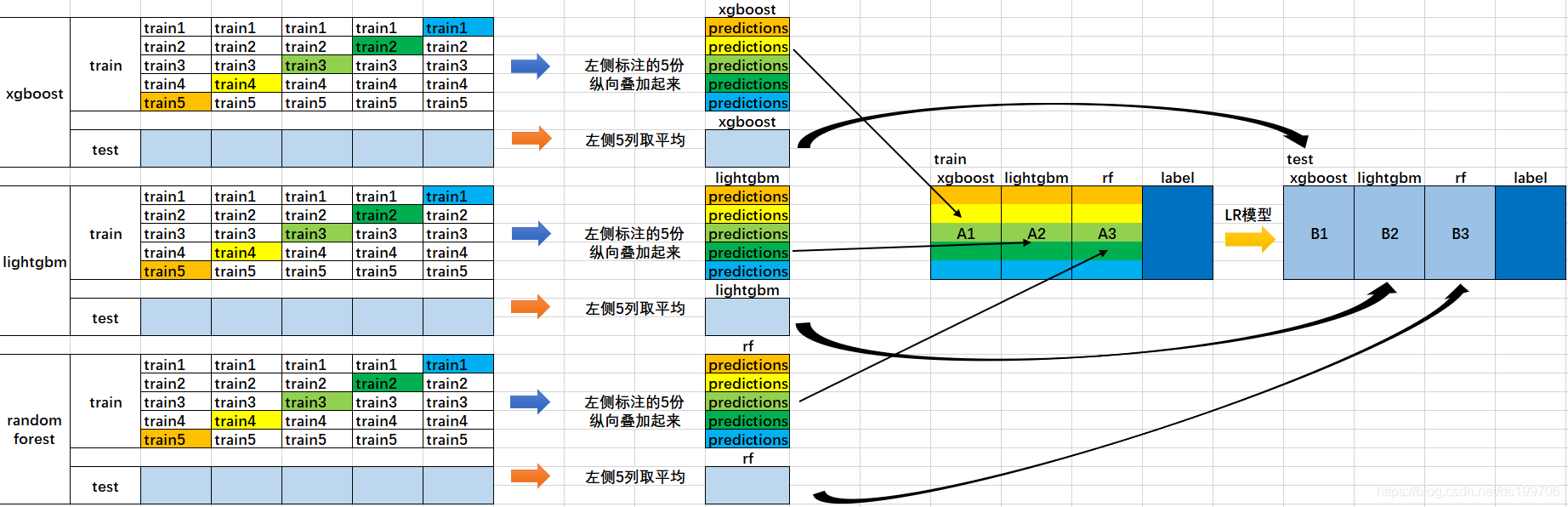

这两个都是两层的例子。第一层就是普通的模型,模型第二层学习的是如何正确结合这些模型的结果。第二层首先就是用其他模型的预测和真实标签作为学习数据,学到如何利用预测结果得到真实标签后就可以用来预测新的数据,只不过被预测的数据也需要先经过预处理:先用第一层的模型预测一遍。
第一层将数据分成五折(fold)训练,应该是为了防止过拟合。
2.2 交叉验证
主要是针对sklearn里的cross_val_score。简单来说也是把数据集分成“折”,假如分成10折,每次拿一折当验证集,验证十次后取结果的平均值当成最终结果,这就是个评估模型的方法。
n_folds = 5
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))例如这里对平均结果计算均方差作为最终的score。
2.3 one-hot编码
比如三个属性“红”、“黄”、“蓝”,如果简单地用sklearn.LabelEncoder()编码成1、2、3,那么这些属性之间就会出现大小关系。因此采用one-hot编码,有多少种属性就有多少位编码,以上编码为001、010、100。
用:独热编码用来解决类别型数据的离散值问题。
不用:将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。
以上引用自 https://www.cnblogs.com/king-lps/p/7846414.html 。
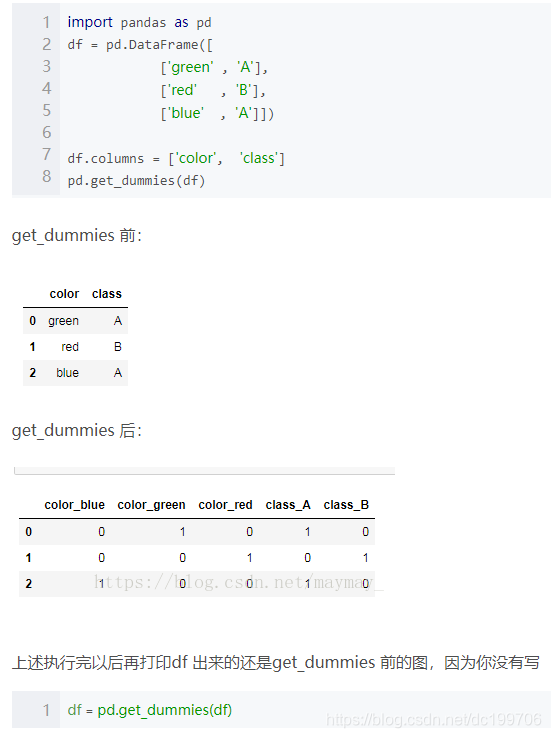
上图截自 https://blog.csdn.net/maymay_/article/details/80198468 。
2.4 box-cox变换
将左偏或右偏的分布函数尽可能变换成正态分布。
2.5 岭回归、Lasso回归和ElasticNet回归
https://www.biaodianfu.com/ridge-lasso-elasticnet.html
这篇文章写的很好。
2.6 GradientBoosting
https://www.cnblogs.com/xiaodi914/p/5496989.html
三、数据预处理
关于GriLivArea,baseline是把4000以上的都drop掉了,我改成了4500以上的都drop掉。因为有两个虽然在4000以上,但是价格趋势是合理的,另外两个4500以上的就不是很合理,面积特别大但价格却特别低,因此去掉。
此外还做了点别的什么数据处理,现在都忘得差不多了,主要是一些无用特征的舍弃和关键特征的组合。
啊对还有最重要的缺失值处理,大致上是做中位数、众数、0(null)或者drop处理。
四、模型选择
用上文提到的STACKING,lasso做meta model,ElasticNet、GBoost、KRR做base model。这个结果得到是0.115。然后试了一下最简单的平均,发现效果反而更好了达到了0.11475。哈哈机器学习就是这么玄学。然后就一直采用这个结果了。
五、折腾
出来结果后我实际上又折腾了很久,主要是做进一步的数据处理。尝试了很多的数据处理方法,但最终效果都没有提升。反而因此忽视了加强模型的训练。最终得分高的同学其实都是因为用了很多的base model,数据处理全都大同小异,看不出什么差别。我想玩花的结果偷鸡不成反蚀把米。
六、总结
总结一下,这个比赛确实很简单,对新人很友好。我当初选这门课也是抱着看一看、体验一下的想法,从这个角度来看,虽然最后成绩不一定好,但是我的目的算是达到了。事实上,我一开始也就是抱着体验一下这个过程的心理做下去的。
通过这门课的学习和这次project的经历,算是对机器学习有了个更清晰的认识,对数据科学算是有了一个朦胧的印象。一些经典的机器学习算法也自不必说,这门课是为数不多我上课比较认真听的课,所以接收效果还算不错。
但也要反思,最后的盲目调参属实是在浪费时间,不过这也确实是我的性格,有时候就是很犟2333。
最重要的是也消除了我在机器学习实践上的不自信感,只要明白了自己要干什么,用python属实是好实现(笑)。
另外也再次确认了本人不适合、也不喜欢搞机器学习。
七、源代码
https://github.com/DDDCai/Kaggle-House-Price-Regression
