本文是博主基于之前练手Kaggle上泰坦尼克的入门分析而做的个人总结
此案例是读者经过研究多个Kaggle上大神的kernel经验,加上个人的理解,再加入百分之一的运气得到 的结果
此案例的亮点在于特征工程部分,对于变量的处理及属性的构造的姿势值得学习~~~
0 简介
关于这个案例,具体的介绍及简介,见Kaggle官网上的数据,内容很全,唯一一个要必须提到的是,官网上的关于变量的解释均是英文的,作为英文有些坎坷的我来说,通常做Kaggle上的案例时,我都会谨慎的仔细的理解各个变量的意思,尤其在这个案例中 ,让我深深的意识到理解变量的意思及变量间的关系对于整个数据集的分析尤为重要!!!!
这是官网上这个案例的链接地址点击打开链接
1 数据探索
1.1 数据特征分析
1.1.1统计量分析总体分析
train = pd.read_csv("traindata.csv")
test = pd.read_csv("test.csv")
alldata = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'], test.loc[:,'MSSubClass':'SaleCondition']), ignore_index=True)
alldata.shape
explore = train.describe(include = 'all').T
explore['null'] = len(train) - explore['count']
explore.insert(0,'dtype',train.dtypes)
explore.T.to_csv('explore1.csv')
explore = alldata.describe(include = 'all').T
explore['null'] = len(alldata) - explore['count']
explore.insert(0,'dtype',alldata.dtypes)
explore.T.to_csv('explore2.csv')
1.1.2 相关性分析
# 相关图 corrmat = train.corr() plt.subplots(figsize=(12,9)) sns.heatmap(corrmat, vmax=0.9, square=True)
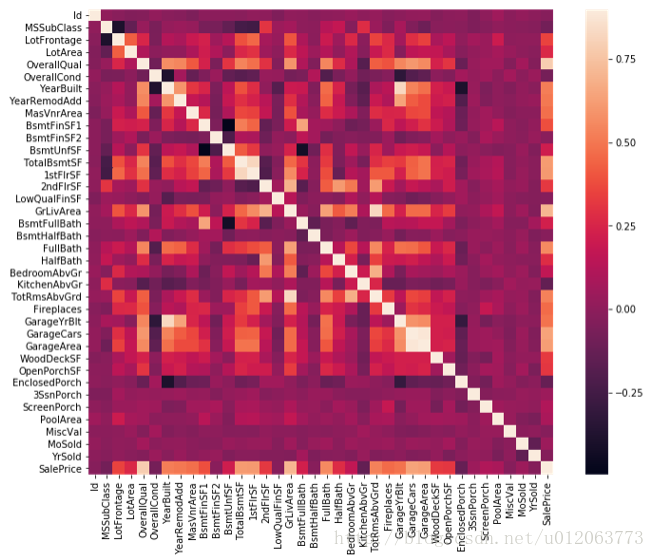
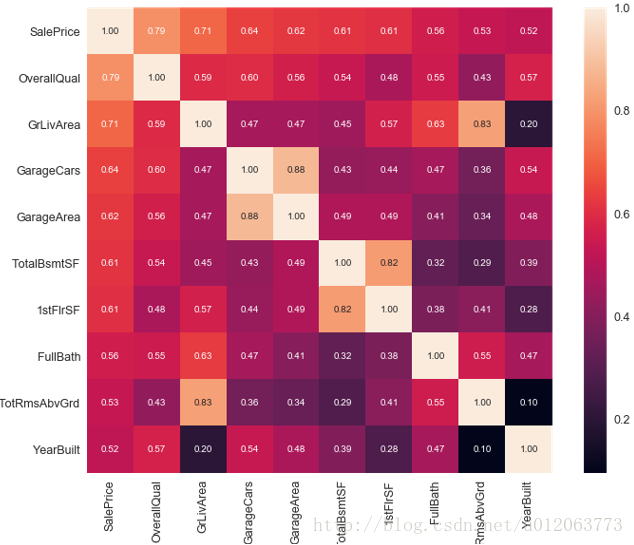
#查看影响最终价格的十个变量
k = 10
plt.figure(figsize=(12,9))
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
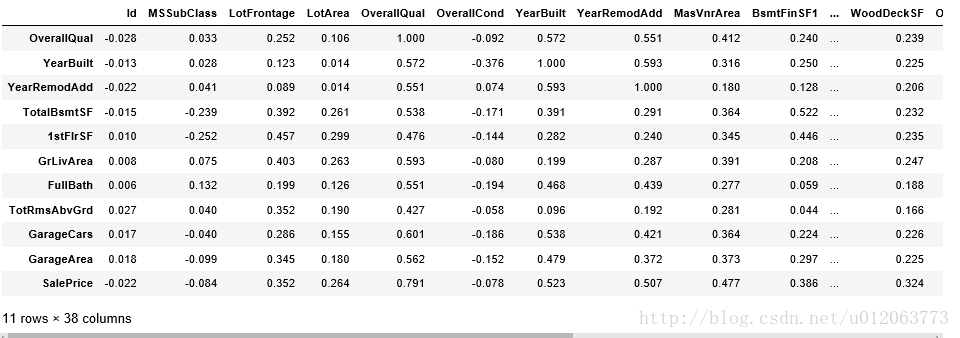
Corr = train.corr() Corr[Corr['SalePrice']>0.5]
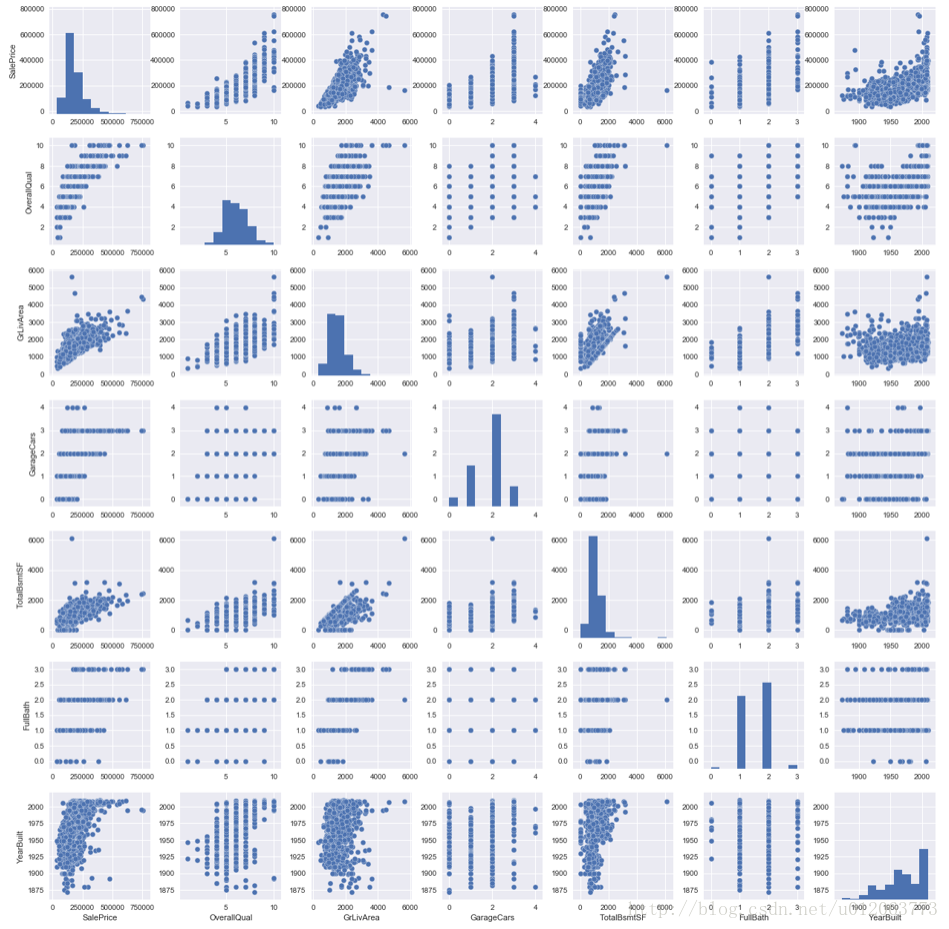
#scatterplot 绘制散点图矩阵注意:多变量作图数据中不能有空值,否则出错 sns.set() cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt'] sns.pairplot(train[cols], size = 2.5) plt.show();
1.1.3 分布分析
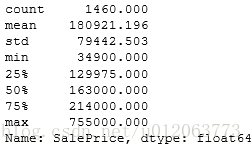
train['SalePrice'].describe()
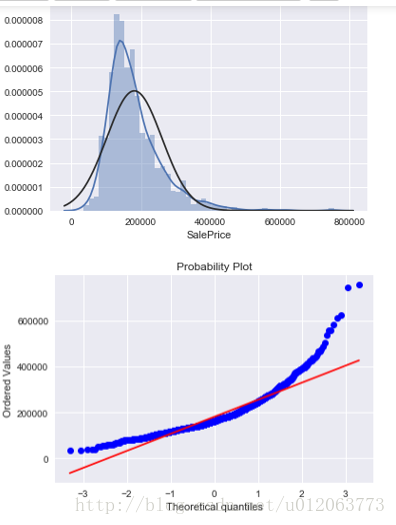
查看是否符合正态分布
#histogram画直方图,且查看数据是否符合正态分布 # 直方图和正态概率图 sns.distplot(train['SalePrice'],fit=norm) fig = plt.figure() res = stats.probplot(train['SalePrice'], plot=plt) ## 由图像可知,图像的非正态分布
print("Skewness: %f" %train['SalePrice'].skew()) #偏度
print("Kurtosis: %f" %train['SalePrice'].kurt()) #峰度
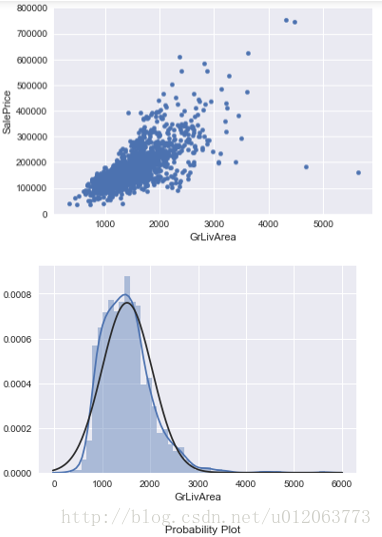
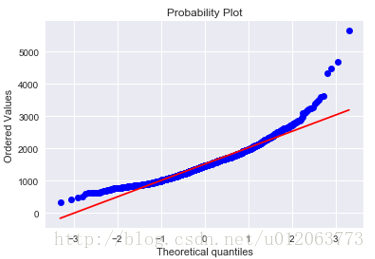
# 研究SalePrice和GrLivArea的关系 data1 = pd.concat([train['SalePrice'], train['GrLivArea']], axis=1) data1.plot.scatter(x='GrLivArea', y='SalePrice', ylim=(0,800000)); # 直方图和正态概率图,查看是否正态分布 fig = plt.figure() sns.distplot(train['GrLivArea'], fit=norm); fig = plt.figure() res = stats.probplot(train['GrLivArea'], plot=plt) ## 由散点图可知,图像的右下角存在两个异常值,建议去除;图像非正态分布
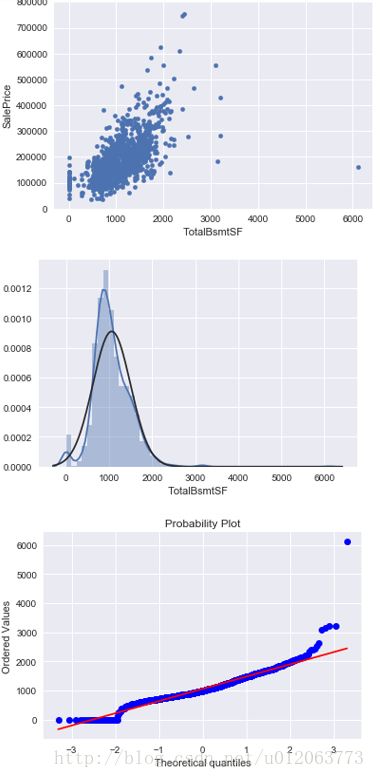
# 研究SalePrice和TotalBsmtSF的关系 data1 = pd.concat([train['SalePrice'], train['TotalBsmtSF']], axis=1) data1.plot.scatter(x='TotalBsmtSF', y='SalePrice', ylim=(0,800000)); # 直方图和正态概率图,查看是否正态分布 fig = plt.figure() sns.distplot(train['TotalBsmtSF'], fit=norm); fig = plt.figure() res = stats.probplot(train['TotalBsmtSF'], plot=plt) ## 由散点图可知,图像的右下角存在1个异常值,建议去除该记录;图像非正态分布
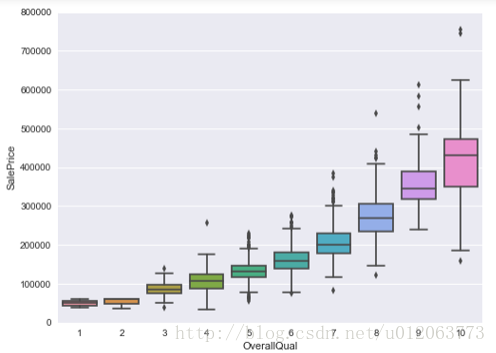
# 研究SalePrice和OverallQual的关系 data2 = pd.concat([train['SalePrice'], train['OverallQual']], axis=1) f, ax = plt.subplots(figsize=(8, 6)) fig = sns.boxplot(x='OverallQual', y="SalePrice", data=data2) fig.axis(ymin=0, ymax=800000);
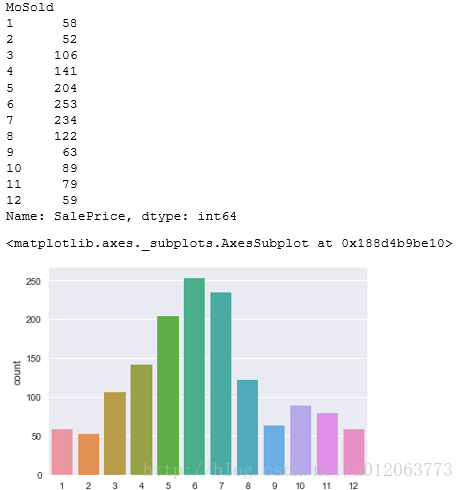
# 查看不同月份的房子的销售量
print(train.groupby('MoSold')['SalePrice'].count())
sns.countplot(x='MoSold',data=train)
1.2 数据质量分析
1.2.1 缺失值
#查看缺失值情况
def missing_values(alldata):
alldata_na = pd.DataFrame(alldata.isnull().sum(), columns={'missingNum'})
alldata_na['missingRatio'] = alldata_na['missingNum']/len(alldata)*100
alldata_na['existNum'] = len(alldata) - alldata_na['missingNum']
alldata_na['train_notna'] = len(train) - train.isnull().sum()
alldata_na['test_notna'] = alldata_na['existNum'] - alldata_na['train_notna']
alldata_na['dtype'] = alldata.dtypes
alldata_na = alldata_na[alldata_na['missingNum']>0].reset_index().sort_values(by=['missingNum','index'],ascending=[False,True])
alldata_na.set_index('index',inplace=True)
return alldata_na
alldata_na = missing_values(alldata)
alldata_na
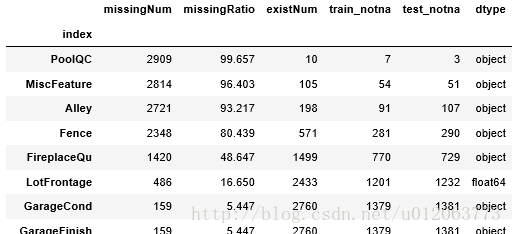
#* 1 *#、对于pool相关空值
# 查看各个poolQC的分布情况
print(alldata['PoolQC'].value_counts())
# PoolArea的均值
poolqc = alldata.groupby('PoolQC')['PoolArea'].mean()
print('不同poolqc的PoolArea的均值',poolqc)
# 查看有PoolArea数据但是没有poolQC的数据
poolqcna = alldata[(alldata['PoolQC'].isnull())& (alldata['PoolArea']!=0)][['PoolQC','PoolArea']]
print('查看有PoolArea数据但是没有poolQC的数据',poolqcna)
# 查看无PoolArea数据但是有poolQC的数据
poolareana = alldata[(alldata['PoolQC'].notnull()) & (alldata['PoolArea']==0)][['PoolQC','PoolArea']]
print('查看无PoolArea数据但是有poolQC的数据',poolareana)
# 查看是否有'PoolQC'不空,PoolArea为空的
print('查看是否有PoolQC不空,PoolArea为空的',alldata[(alldata['PoolQC'].notnull()) & (alldata['PoolArea']==0)][['PoolQC','PoolArea']])
# 由结果可知,PoolQC有三种取值,存在3个值QC为空,Area不为空,以PoolQC进行分组,计算PoolArea的均值,最小距离

#* 2 *#、对于Garage*相关空值
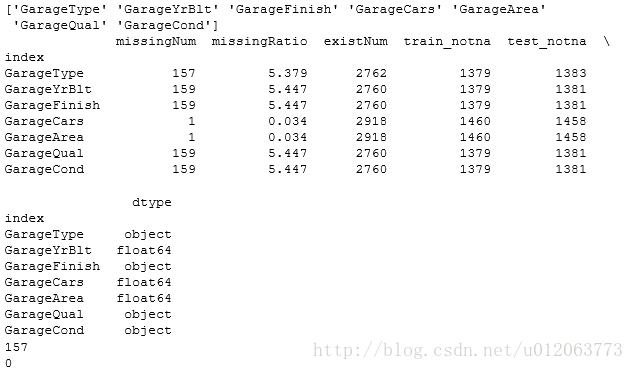
# 找出所有Garage前缀的属性
a = pd.Series(alldata.columns)
GarageList = a[a.str.contains('Garage')].values
print(GarageList)
# -step1 GarageYrBlt 车库建造年份
print(alldata_na.ix[GarageList,:])
# -step2:检查GarageArea、GarageCars均为0的,其他类别列的空值均填充“none”,数值列填“0”
print(len(alldata[(alldata['GarageArea']==0) & (alldata['GarageCars']==0)]))# 157
print(len(alldata[(alldata['GarageArea']!=0) & (alldata['GarageCars'].isnull==True)])) # 0
# 'GarageYrBlt'到后来与年份一起处理,也有空值
#* 3 *#、对于Bsmt*相关空值
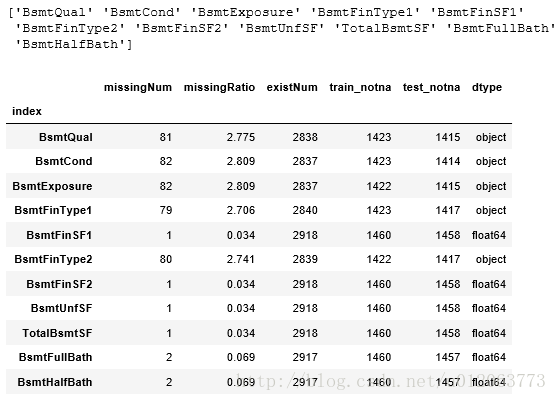
# 找出所有Bsmt前缀的属性
a = pd.Series(alldata.columns)
BsmtList = a[a.str.contains('Bsmt')].values
print(BsmtList)
allBsmtNa = alldata_na.ix[BsmtList,:]
print(allBsmtNa)
condition = (alldata['BsmtExposure'].isnull()) & (alldata['BsmtCond'].notnull()) alldata[condition][BsmtList] # 通过研究发现,BsmtExposure为空时,有三行数据其他值不为空,取众数填充

condition1 = (alldata['BsmtCond'].isnull()) & (alldata['BsmtExposure'].notnull()) print(len(alldata[alldata['BsmtCond']==alldata['BsmtQual']])) alldata[condition1][BsmtList] # 通过研究发现,BsmtCond为空时,有三行数据其他值不为空# 有1265个值的BsmtQual == BsmtCond,所以对应填充

condition2 = (alldata['BsmtQual'].isnull()) & (alldata['BsmtExposure'].notnull()) alldata[condition2][BsmtList] # 通过研究发现,BsmtQual为空时,有两行数据其他值不为空,填充方法与condition1类似

# 其他剩下的字段考虑数值型空值填0,标称型空值填none print(alldata['BsmtFinSF1'].value_counts().head(5))# 空值填0 print(alldata['BsmtFinSF2'].value_counts().head(5))# 空值填0 print(alldata['BsmtFullBath'].value_counts().head(5))# 空值填0 print(alldata['BsmtHalfBath'].value_counts().head(5))# 空值填0 print(alldata['BsmtFinType1'].value_counts().head(5)) # 空值填众数 print(alldata['BsmtFinType2'].value_counts().head(5)) # 空值填众数

#* 4 *#、MasVnrType 砖石类型 MasVnrArea 砖石面积
print(alldata[['MasVnrType', 'MasVnrArea']].isnull().sum())
print(len(alldata[(alldata['MasVnrType'].isnull())& (alldata['MasVnrArea'].isnull())])) # 23
print(len(alldata[(alldata['MasVnrType'].isnull())& (alldata['MasVnrArea'].notnull())]))
print(len(alldata[(alldata['MasVnrType'].notnull())& (alldata['MasVnrArea'].isnull())]))
print(alldata['MasVnrType'].value_counts())
MasVnrM = alldata.groupby('MasVnrType')['MasVnrArea'].median()
print(MasVnrM)
mtypena = alldata[(alldata['MasVnrType'].isnull())& (alldata['MasVnrArea'].notnull())][['MasVnrType','MasVnrArea']]
print(mtypena)
# 由此可知,由一条数据的 MasVnrType 为空而Area不为空,所以,填充方式按照类似poolQC和poolArea的方式,分组填充
# 其他数据中MasVnrType空值填fillna("None"),MasVnrArea空值填fillna(0)

#这部分数据很奇怪,类型为“None"类型,但是Area却大于0,还有等于1的 alldata[(alldata['MasVnrType']=='None')&(alldata['MasVnrArea']!=0)][['MasVnrType','MasVnrArea']]
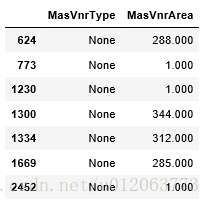
alldata[alldata['MasVnrType']=='None'][['MasVnrArea']]['MasVnrArea'].value_counts()

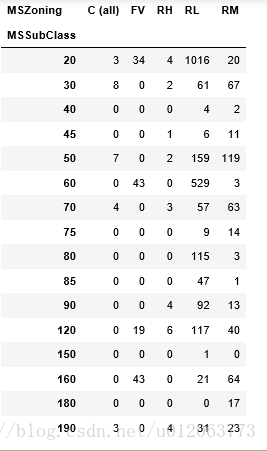
#* 5 *#、 MS**填充MSSubClass 住宅类型MSZoning 分区分类
print(alldata[alldata['MSSubClass'].isnull() | alldata['MSZoning'].isnull()][['MSSubClass','MSZoning']]) pd.crosstab(alldata.MSSubClass, alldata.MSZoning) #通过观察30/70 'RM'和20'RL'的组合较多。对应填充
#* 6 *#、LotFrontage
#考虑到LotFrontage 与街道连接的线性脚与Neighborhood 房屋附近位置 存在一定的关系
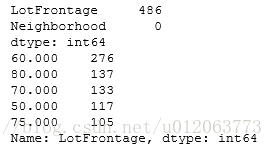
print(alldata[["LotFrontage", "Neighborhood"]].isnull().sum())
print(alldata["LotFrontage"].value_counts().head(5))
# 考虑通过一定的方式来填充
# 例如:
alldata["LotFrontage"] = alldata.groupby("Neighborhood")["LotFrontage"].transform(
lambda x: x.fillna(x.median()))
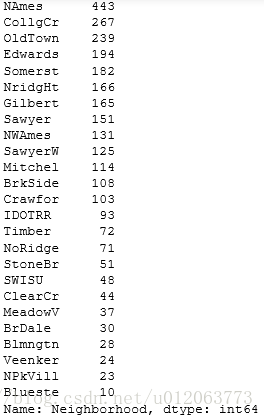
alldata["Neighborhood"].value_counts()
#* 7 *#、其他
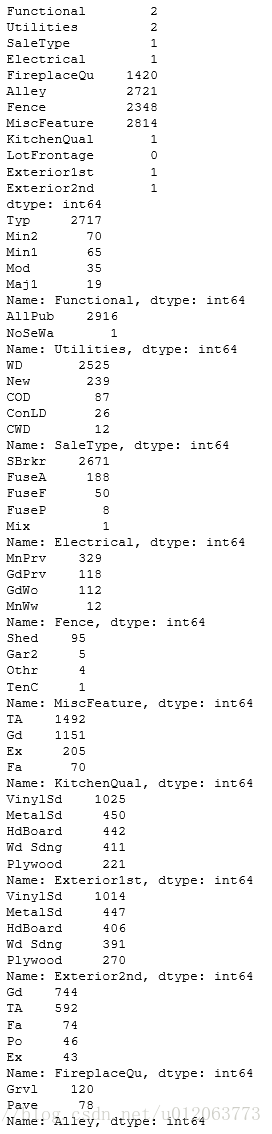
others = ['Functional','Utilities','SaleType','Electrical', "FireplaceQu",'Alley',"Fence", "MiscFeature",\
'KitchenQual',"LotFrontage",'Exterior1st','Exterior2nd']
print(alldata[others].isnull().sum())
print(alldata['Functional'].value_counts().head(5)) # 填众数
print(alldata['Utilities'].value_counts().head(5)) # 填众数
print(alldata['SaleType'].value_counts().head(5)) # 填众数
print(alldata['Electrical'].value_counts().head(5)) # 填众数
print(alldata["Fence"].value_counts()) # 填众数
print(alldata["MiscFeature"].value_counts().head(5)) # 填众数
print(alldata['KitchenQual'].value_counts().head(5)) # 填众数
print(alldata['Exterior1st'].value_counts().head(5)) # 填众数
print(alldata['Exterior2nd'].value_counts().head(5)) # 填众数
print(alldata['FireplaceQu'].value_counts().head(5)) # 填'none'
print(alldata['Alley'].value_counts().head(5)) # 填'none'
1.2.2 异常值
由上述的图像可知,存在异常值,建议去除
1.2.3 重复值
alldata[alldata[alldata.columns].duplicated()==True]# 但是考虑到当前重复值后来不影响应用 所以可以不用删除

2 数据预处理
2.1 数据清洗
2.1.1 缺失值处理
#* 1 *#、对于pool相关空值
poolqcna = alldata[(alldata['PoolQC'].isnull())& (alldata['PoolArea']!=0)][['PoolQC','PoolArea']]
areamean = alldata.groupby('PoolQC')['PoolArea'].mean()
for i in poolqcna.index:
v = alldata.loc[i,['PoolArea']].values
print(type(np.abs(v-areamean)))
alldata.loc[i,['PoolQC']] = np.abs(v-areamean).astype('float64').argmin()
alldata['PoolQC'] = alldata["PoolQC"].fillna("None")
alldata['PoolArea'] = alldata["PoolArea"].fillna(0)
#* 2 *#、对于Garage*相关空值
alldata[['GarageCond','GarageFinish','GarageQual','GarageType']] = alldata[['GarageCond','GarageFinish','GarageQual','GarageType']].fillna('None')
alldata[['GarageCars','GarageArea']] = alldata[['GarageCars','GarageArea']].fillna(0)
alldata['Electrical'] = alldata['Electrical'].fillna( alldata['Electrical'].mode()[0])
# 注意此处'GarageYrBlt'尚未填充
#* 3 *#、对于Bsmt*相关空值
a = pd.Series(alldata.columns)
BsmtList = a[a.str.contains('Bsmt')].values
condition = (alldata['BsmtExposure'].isnull()) & (alldata['BsmtCond'].notnull()) # 3个
alldata.ix[(condition),'BsmtExposure'] = alldata['BsmtExposure'].mode()[0]
condition1 = (alldata['BsmtCond'].isnull()) & (alldata['BsmtExposure'].notnull()) # 3个
alldata.ix[(condition1),'BsmtCond'] = alldata.ix[(condition1),'BsmtQual']
condition2 = (alldata['BsmtQual'].isnull()) & (alldata['BsmtExposure'].notnull()) # 2个
alldata.ix[(condition2),'BsmtQual'] = alldata.ix[(condition2),'BsmtCond']
# 对于BsmtFinType1和BsmtFinType2
condition3 = (alldata['BsmtFinType1'].notnull()) & (alldata['BsmtFinType2'].isnull())
alldata.ix[condition3,'BsmtFinType2'] = 'Unf'
allBsmtNa = alldata_na.ix[BsmtList,:]
allBsmtNa_obj = allBsmtNa[allBsmtNa['dtype']=='object'].index
allBsmtNa_flo = allBsmtNa[allBsmtNa['dtype']!='object'].index
alldata[allBsmtNa_obj] =alldata[allBsmtNa_obj].fillna('None')
alldata[allBsmtNa_flo] = alldata[allBsmtNa_flo].fillna(0)
#* 4 *#、MasVnr**
MasVnrM = alldata.groupby('MasVnrType')['MasVnrArea'].median()
mtypena = alldata[(alldata['MasVnrType'].isnull())& (alldata['MasVnrArea'].notnull())][['MasVnrType','MasVnrArea']]
for i in mtypena.index:
v = alldata.loc[i,['MasVnrArea']].values
alldata.loc[i,['MasVnrType']] = np.abs(v-MasVnrM).astype('float64').argmin()
alldata['MasVnrType'] = alldata["MasVnrType"].fillna("None")
alldata['MasVnrArea'] = alldata["MasVnrArea"].fillna(0)
#* 5 *#、 MS**
alldata["MSZoning"] = alldata.groupby("MSSubClass")["MSZoning"].transform(lambda x: x.fillna(x.mode()[0]))
#* 6 *#、LotFrontage
使用多项式拟合填充 x = alldata.loc[alldata["LotFrontage"].notnull(), "LotArea"] y = alldata.loc[alldata["LotFrontage"].notnull(), "LotFrontage"] t = (x <= 25000) & (y <= 150) p = np.polyfit(x[t], y[t], 1) alldata.loc[alldata['LotFrontage'].isnull(), 'LotFrontage'] = \ np.polyval(p, alldata.loc[alldata['LotFrontage'].isnull(), 'LotArea'])
#* 7 *#、其他
alldata['KitchenQual'] = alldata['KitchenQual'].fillna(alldata['KitchenQual'].mode()[0]) # 用众数填充
alldata['Exterior1st'] = alldata['Exterior1st'].fillna(alldata['Exterior1st'].mode()[0])
alldata['Exterior2nd'] = alldata['Exterior2nd'].fillna(alldata['Exterior2nd'].mode()[0])
alldata["Functional"] = alldata["Functional"].fillna(alldata['Functional'].mode()[0])
alldata["SaleType"] = alldata["SaleType"].fillna(alldata['SaleType'].mode()[0])
alldata["Utilities"] = alldata["Utilities"].fillna(alldata['Utilities'].mode()[0])
alldata[["Fence", "MiscFeature"]] = alldata[["Fence", "MiscFeature"]].fillna('None')
alldata['FireplaceQu'] = alldata['FireplaceQu'].fillna('None')
alldata['Alley'] = alldata['Alley'].fillna('None')
alldata.isnull().sum()[alldata.isnull().sum()>0] #至此, 还有一个属性未填充 # GarageYrBlt 159
year_map = pd.concat(pd.Series('YearGroup' + str(i+1), index=range(1871+i*20,1891+i*20)) for i in range(0, 7))
# 将年份对应映射
alldata.GarageYrBlt = alldata.GarageYrBlt.map(year_map)
alldata['GarageYrBlt']= alldata['GarageYrBlt'].fillna('None')# 必须 离散化之后再对应映射
2.1.2 异常值处理
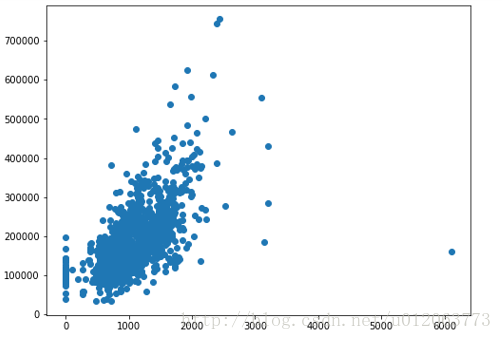
plt.figure(figsize=(8,6)) plt.scatter(train.GrLivArea,train.SalePrice) plt.show() # # 删除掉异常值GrLivArea>4000但是销售价格低于200000的记录 outliers_id = train[(train.GrLivArea>4000) & (train.SalePrice<200000)].index print(outliers_id)
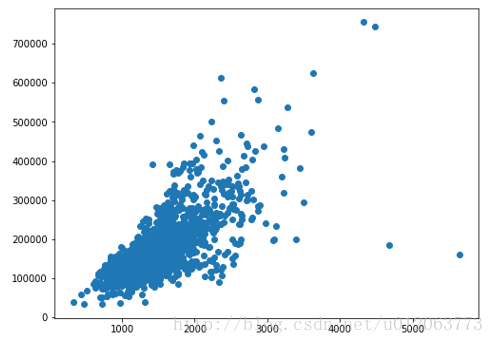
# 删除掉异常值 alldata = alldata.drop(outliers_id) Y = train.SalePrice.drop(outliers_id)
plt.figure(figsize=(8,6)) plt.scatter(train.TotalBsmtSF,train.SalePrice) plt.show()
可以发现 最开始探索的那个位置的异常值已经被删除了
train_now = pd.concat([alldata.iloc[:1458,:],Y], axis=1) test_now = alldata.iloc[1458:,:]
train_now.to_csv('train_afterclean.csv')
test_now.to_csv('test_afterclean.csv')保存数据清洗后的数据,为接下来的操作准备数据集
2.2 数据变换
读取数据清洗后得到的数据
train = pd.read_csv("train_afterclean.csv")
test = pd.read_csv("test_afterclean.csv")
alldata = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'], test.loc[:,'MSSubClass':'SaleCondition']), ignore_index=True)
alldata.shape
(2917, 79)
2.2.1 对于标称型属性
属性构造
(1)对于序列型属性
# 处理序列型标称数据
ordinalList = ['ExterQual', 'ExterCond', 'GarageQual', 'GarageCond','PoolQC',\
'FireplaceQu', 'KitchenQual', 'HeatingQC', 'BsmtQual','BsmtCond']
ordinalmap = {'Ex': 5,'Gd': 4,'TA': 3,'Fa': 2,'Po': 1,'None': 0}
for c in ordinalList:
alldata[c] = alldata[c].map(ordinalmap)
(2)其他类别属性——标签化
alldata['BsmtExposure'] = alldata['BsmtExposure'].map({'None':0, 'No':1, 'Mn':2, 'Av':3, 'Gd':4})
alldata['BsmtFinType1'] = alldata['BsmtFinType1'].map({'None':0, 'Unf':1, 'LwQ':2,'Rec':3, 'BLQ':4, 'ALQ':5, 'GLQ':6})
alldata['BsmtFinType2'] = alldata['BsmtFinType2'].map({'None':0, 'Unf':1, 'LwQ':2,'Rec':3, 'BLQ':4, 'ALQ':5, 'GLQ':6})
alldata['Functional'] = alldata['Functional'].map({'Maj2':1, 'Sev':2, 'Min2':3, 'Min1':4, 'Maj1':5, 'Mod':6, 'Typ':7})
alldata['GarageFinish'] = alldata['GarageFinish'].map({'None':0, 'Unf':1, 'RFn':2, 'Fin':3})
alldata['Fence'] = alldata['Fence'].map({'MnWw':0, 'GdWo':1, 'MnPrv':2, 'GdPrv':3, 'None':4})
(3)部分属性创建二值新属性
MasVnrType_Any = alldata.MasVnrType.replace({'BrkCmn': 1,'BrkFace': 1,'CBlock': 1,'Stone': 1,'None': 0})
MasVnrType_Any.name = 'MasVnrType_Any' #修改该series的列名
SaleCondition_PriceDown = alldata.SaleCondition.replace({'Abnorml': 1,'Alloca': 1,'AdjLand': 1,'Family': 1,'Normal': 0,'Partial': 0})
SaleCondition_PriceDown.name = 'SaleCondition_PriceDown' #修改该series的列名
alldata = alldata.replace({'CentralAir': {'Y': 1,'N': 0}})
alldata = alldata.replace({'PavedDrive': {'Y': 1,'P': 0,'N': 0}})
newer_dwelling = alldata['MSSubClass'].map({20: 1,30: 0,40: 0,45: 0,50: 0,60: 1,70: 0,75: 0,80: 0,85: 0,90: 0,120: 1,150: 0,160: 0,180: 0,190: 0})
newer_dwelling.name= 'newer_dwelling' #修改该series的列名
alldata['MSSubClass'] = alldata['MSSubClass'].apply(str)
Neighborhood_Good = pd.DataFrame(np.zeros((alldata.shape[0],1)), columns=['Neighborhood_Good']) Neighborhood_Good[alldata.Neighborhood=='NridgHt'] = 1 Neighborhood_Good[alldata.Neighborhood=='Crawfor'] = 1 Neighborhood_Good[alldata.Neighborhood=='StoneBr'] = 1 Neighborhood_Good[alldata.Neighborhood=='Somerst'] = 1 Neighborhood_Good[alldata.Neighborhood=='NoRidge'] = 1 # Neighborhood_Good = (alldata['Neighborhood'].isin(['StoneBr','NoRidge','NridgHt','Timber','Somerst']))*1 #(效果没有上面好) Neighborhood_Good.name='Neighborhood_Good'# 将该变量加入
season = (alldata['MoSold'].isin([5,6,7]))*1 #(@@@@@) season.name='season' alldata['MoSold'] = alldata['MoSold'].apply(str)
(4)对与“质量——Qual”“条件——Cond”属性,构造新属性
# 处理OverallQual:将该属性分成两个子属性,以5为分界线,大于5及小于5的再分别以序列 overall_poor_qu = alldata.OverallQual.copy()# Series类型 overall_poor_qu = 5 - overall_poor_qu overall_poor_qu[overall_poor_qu<0] = 0 overall_poor_qu.name = 'overall_poor_qu' overall_good_qu = alldata.OverallQual.copy() overall_good_qu = overall_good_qu - 5 overall_good_qu[overall_good_qu<0] = 0 overall_good_qu.name = 'overall_good_qu' # 处理OverallCond :将该属性分成两个子属性,以5为分界线,大于5及小于5的再分别以序列 overall_poor_cond = alldata.OverallCond.copy()# Series类型 overall_poor_cond = 5 - overall_poor_cond overall_poor_cond[overall_poor_cond<0] = 0 overall_poor_cond.name = 'overall_poor_cond' overall_good_cond = alldata.OverallCond.copy() overall_good_cond = overall_good_cond - 5 overall_good_cond[overall_good_cond<0] = 0 overall_good_cond.name = 'overall_good_cond' # 处理ExterQual:将该属性分成两个子属性,以3为分界线,大于3及小于3的再分别以序列 exter_poor_qu = alldata.ExterQual.copy() exter_poor_qu[exter_poor_qu<3] = 1 exter_poor_qu[exter_poor_qu>=3] = 0 exter_poor_qu.name = 'exter_poor_qu' exter_good_qu = alldata.ExterQual.copy() exter_good_qu[exter_good_qu<=3] = 0 exter_good_qu[exter_good_qu>3] = 1 exter_good_qu.name = 'exter_good_qu' # 处理ExterCond:将该属性分成两个子属性,以3为分界线,大于3及小于3的再分别以序列 exter_poor_cond = alldata.ExterCond.copy() exter_poor_cond[exter_poor_cond<3] = 1 exter_poor_cond[exter_poor_cond>=3] = 0 exter_poor_cond.name = 'exter_poor_cond' exter_good_cond = alldata.ExterCond.copy() exter_good_cond[exter_good_cond<=3] = 0 exter_good_cond[exter_good_cond>3] = 1 exter_good_cond.name = 'exter_good_cond' # 处理BsmtCond:将该属性分成两个子属性,以3为分界线,大于3及小于3的再分别以序列 bsmt_poor_cond = alldata.BsmtCond.copy() bsmt_poor_cond[bsmt_poor_cond<3] = 1 bsmt_poor_cond[bsmt_poor_cond>=3] = 0 bsmt_poor_cond.name = 'bsmt_poor_cond' bsmt_good_cond = alldata.BsmtCond.copy() bsmt_good_cond[bsmt_good_cond<=3] = 0 bsmt_good_cond[bsmt_good_cond>3] = 1 bsmt_good_cond.name = 'bsmt_good_cond' # 处理GarageQual:将该属性分成两个子属性,以3为分界线,大于3及小于3的再分别以序列 garage_poor_qu = alldata.GarageQual.copy() garage_poor_qu[garage_poor_qu<3] = 1 garage_poor_qu[garage_poor_qu>=3] = 0 garage_poor_qu.name = 'garage_poor_qu' garage_good_qu = alldata.GarageQual.copy() garage_good_qu[garage_good_qu<=3] = 0 garage_good_qu[garage_good_qu>3] = 1 garage_good_qu.name = 'garage_good_qu' # 处理GarageCond:将该属性分成两个子属性,以3为分界线,大于3及小于3的再分别以序列 garage_poor_cond = alldata.GarageCond.copy() garage_poor_cond[garage_poor_cond<3] = 1 garage_poor_cond[garage_poor_cond>=3] = 0 garage_poor_cond.name = 'garage_poor_cond' garage_good_cond = alldata.GarageCond.copy() garage_good_cond[garage_good_cond<=3] = 0 garage_good_cond[garage_good_cond>3] = 1 garage_good_cond.name = 'garage_good_cond' # 处理KitchenQual:将该属性分成两个子属性,以3为分界线,大于3及小于3的再分别以序列 kitchen_poor_qu = alldata.KitchenQual.copy() kitchen_poor_qu[kitchen_poor_qu<3] = 1 kitchen_poor_qu[kitchen_poor_qu>=3] = 0 kitchen_poor_qu.name = 'kitchen_poor_qu' kitchen_good_qu = alldata.KitchenQual.copy() kitchen_good_qu[kitchen_good_qu<=3] = 0 kitchen_good_qu[kitchen_good_qu>3] = 1 kitchen_good_qu.name = 'kitchen_good_qu'
将构造的属性合并
qu_list = pd.concat((overall_poor_qu, overall_good_qu, overall_poor_cond, overall_good_cond, exter_poor_qu,
exter_good_qu, exter_poor_cond, exter_good_cond, bsmt_poor_cond, bsmt_good_cond, garage_poor_qu,
garage_good_qu, garage_poor_cond, garage_good_cond, kitchen_poor_qu, kitchen_good_qu), axis=1)
(5)对与时间相关属性处理
Xremoded = (alldata['YearBuilt']!=alldata['YearRemodAdd'])*1 #(@@@@@) Xrecentremoded = (alldata['YearRemodAdd']>=alldata['YrSold'])*1 #(@@@@@) XnewHouse = (alldata['YearBuilt']>=alldata['YrSold'])*1 #(@@@@@) XHouseAge = 2010 - alldata['YearBuilt'] XTimeSinceSold = 2010 - alldata['YrSold'] XYearSinceRemodel = alldata['YrSold'] - alldata['YearRemodAdd'] Xremoded.name='Xremoded' Xrecentremoded.name='Xrecentremoded' XnewHouse.name='XnewHouse' XTimeSinceSold.name='XTimeSinceSold' XYearSinceRemodel.name='XYearSinceRemodel' XHouseAge.name='XHouseAge' year_list = pd.concat((Xremoded,Xrecentremoded,XnewHouse,XHouseAge,XTimeSinceSold,XYearSinceRemodel),axis=1)
(6)构造新属性'price_category'
此处利用SVM支持向量机构造新属性
class sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0,
shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None,
verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
SVC参数解释
(1)C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,default C = 1.0;
(2)kernel:参数选择有RBF, Linear, Poly, Sigmoid, 默认的是"RBF";
(3)degree:if you choose 'Poly' in param 2, this is effective, degree决定了多项式的最高次幂;
(4)gamma:核函数的系数('Poly', 'RBF' and 'Sigmoid'), 默认是gamma = 1 / n_features;
(5)coef0:核函数中的独立项,'RBF' and 'Poly'有效;
(6)probablity: 可能性估计是否使用(true or false);
(7)shrinking:是否进行启发式;
(8)tol(default = 1e - 3): svm结束标准的精度;
(9)cache_size: 制定训练所需要的内存(以MB为单位);
(10)class_weight: 每个类所占据的权重,不同的类设置不同的惩罚参数C, 缺省的话自适应;
(11)verbose: 跟多线程有关,不大明白啥意思具体;
(12)max_iter: 最大迭代次数,default = 1, if max_iter = -1, no limited;
(13)decision_function_shape : ‘ovo’ 一对一, ‘ovr’ 多对多 or None 无, default=None
(14)random_state :用于概率估计的数据重排时的伪随机数生成器的种子。
ps:7,8,9一般不考虑。
from sklearn.svm import SVC svm = SVC(C=100, gamma=0.0001, kernel='rbf') pc = pd.Series(np.zeros(train.shape[0])) pc[:] = 'pc1' pc[train.SalePrice >= 150000] = 'pc2' pc[train.SalePrice >= 220000] = 'pc3' columns_for_pc = ['Exterior1st', 'Exterior2nd', 'RoofMatl', 'Condition1', 'Condition2', 'BldgType'] X_t = pd.get_dummies(train.loc[:, columns_for_pc], sparse=True) svm.fit(X_t, pc)# 训练 p = train.SalePrice/100000 price_category = pd.DataFrame(np.zeros((alldata.shape[0],1)), columns=['pc']) X_t = pd.get_dummies(alldata.loc[:, columns_for_pc], sparse=True) pc_pred = svm.predict(X_t) # 预测 price_category[pc_pred=='pc2'] = 1 price_category[pc_pred=='pc3'] = 2 price_category.name='price_category'
连续数据离散化
year_map = pd.concat(pd.Series('YearGroup' + str(i+1), index=range(1871+i*20,1891+i*20)) for i in range(0, 7))
# 将年份对应映射
# alldata.GarageYrBlt = alldata.GarageYrBlt.map(year_map) # 在数据填充时已经完成该转换了(因为必须先转化后再填充,否则会出错(可以想想到底为什么呢?))
alldata.YearBuilt = alldata.YearBuilt.map(year_map)
alldata.YearRemodAdd = alldata.YearRemodAdd.map(year_map)
2.2.2 处理数值型属性
# 简单函数 规范化 按照比例缩放
numeric_feats = alldata.dtypes[alldata.dtypes != "object"].index
t = alldata[numeric_feats].quantile(.75) # 取四分之三分位
use_75_scater = t[t != 0].index
alldata[use_75_scater] = alldata[use_75_scater]/alldata[use_75_scater].quantile(.75)
# 标准化数据使符合正态分布
from scipy.special import boxcox1p
t = ['LotFrontage', 'LotArea', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF',
'1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF',
'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal']
# alldata.loc[:, t] = np.log1p(alldata.loc[:, t])
train["SalePrice"] = np.log1p(train["SalePrice"]) # 对于SalePrice 采用log1p较好---np.expm1(clf1.predict(X_test))
lam = 0.15 # 100 * (1-lam)% confidence
for feat in t:
alldata[feat] = boxcox1p(alldata[feat], lam) # 对于其他属性,采用boxcox1p较好
# 将标称型变量二值化
X = pd.get_dummies(alldata)
X = X.fillna(X.mean())
X = X.drop('Condition2_PosN', axis=1)
X = X.drop('MSZoning_C (all)', axis=1)
X = X.drop('MSSubClass_160', axis=1)
X= pd.concat((X, newer_dwelling, season, year_list ,qu_list,MasVnrType_Any, \
price_category,SaleCondition_PriceDown,Neighborhood_Good), axis=1)#SaleCondition_PriceDown,Neighborhood_Good已经加入
# 创建新属性
from itertools import product, chain
# chain(iter1, iter2, ..., iterN):
# 给出一组迭代器(iter1, iter2, ..., iterN),此函数创建一个新迭代器来将所有的迭代器链接起来,
# 返回的迭代器从iter1开始生成项,知道iter1被用完,然后从iter2生成项,这一过程会持续到iterN中所有的项都被用完。
def poly(X):
areas = ['LotArea', 'TotalBsmtSF', 'GrLivArea', 'GarageArea', 'BsmtUnfSF'] # 5个
t = chain(qu_list.axes[1].get_values(),year_list.axes[1].get_values(),ordinalList,
['MasVnrType_Any']) #,'Neighborhood_Good','SaleCondition_PriceDown'
for a, t in product(areas, t):
x = X.loc[:, [a, t]].prod(1) # 返回各维数组的乘积
x.name = a + '_' + t
yield x# 带有 yield 的函数在 Python 中被称之为 generator(生成器)
# 一个带有 yield 的函数就是一个 generator,它和普通函数不同,生成一个 generator 看起来像函数调用,
# 但不会执行任何函数代码,直到对其调用 next()(在 for 循环中会自动调用 next())才开始执行。
# 虽然执行流程仍按函数的流程执行,但每执行到一个 yield 语句就会中断,并返回一个迭代值,
# 下次执行时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,
# 每次中断都会通过 yield 返回当前的迭代值。
XP = pd.concat(poly(X), axis=1) # (2917, 155) X = pd.concat((X, XP), axis=1) # (2917, 466) X_train = X[:train.shape[0]] X_test = X[train.shape[0]:]
print(X_train.shape)#(1458, 460)
Y= train.SalePrice train_now = pd.concat([X_train,Y], axis=1) test_now = X_test
将处理后的结果进行保存,用于接下来构建模型
train_now.to_csv('train_afterchange.csv')
test_now.to_csv('test_afterchange.csv')
3 模型构建
导入需要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cross_validation import cross_val_score
from sklearn.metrics import make_scorer, mean_squared_error
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
from operator import itemgetter
import itertools
warnings.filterwarnings('ignore')
%matplotlib inline
pd.set_option('display.float_format',lambda x:'{:.3f}'.format(x))
import xgboost as xgb
备注:对于如何导入xgboost包,请参考点击打开链接
读取数据变换后的数据来建模
train = pd.read_csv("train_afterchange.csv")
test = pd.read_csv("test_afterchange.csv")
alldata = pd.concat((train.iloc[:,1:-1], test.iloc[:,1:]), ignore_index=True)
alldata.shape
(2917, 460)
X_train = train.iloc[:,1:-1] y = train.iloc[:,-1] X_test = test.iloc[:,1:]
# 定义验证函数
def rmse_cv(model):
rmse= np.sqrt(-cross_val_score(model, X_train, y, scoring="neg_mean_squared_error", cv = 5))
return(rmse)
#LASSO MODEL
clf1 = LassoCV(alphas = [1, 0.1, 0.001, 0.0005,0.0003,0.0002, 5e-4])
clf1.fit(X_train, y)
lasso_preds = np.expm1(clf1.predict(X_test)) # exp(x) - 1 <---->log1p(x)==log(1+x)
score1 = rmse_cv(clf1)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score1.mean(), score1.std()))
Lasso score: 0.1142 (0.0058)
#ELASTIC NET
clf2 = ElasticNet(alpha=0.0005, l1_ratio=0.9)
clf2.fit(X_train, y)
elas_preds = np.expm1(clf2.predict(X_test))
score2 = rmse_cv(clf2)
print("\nElasticNet score: {:.4f} ({:.4f})\n".format(score2.mean(), score2.std()))
ElasticNet score: 0.1128 (0.0060)
#XGBOOST
#XGBOOST
clf3=xgb.XGBRegressor(colsample_bytree=0.4,
gamma=0.045,
learning_rate=0.07,
max_depth=20,
min_child_weight=1.5,
n_estimators=300,
reg_alpha=0.65,
reg_lambda=0.45,
subsample=0.95)
clf3.fit(X_train, y.values)
xgb_preds = np.expm1(clf3.predict(X_test))
score3 = rmse_cv(clf3)
print("\nxgb score: {:.4f} ({:.4f})\n".format(score3.mean(), score3.std()))
xgb score: 0.1252 (0.0049)
模型融合:
final_result = 0.7*lasso_preds + 0.15*xgb_preds+0.15*elas_preds #0.11327
solution = pd.DataFrame({"id":test.index+1461, "SalePrice":final_result}, columns=['id', 'SalePrice'])
solution.to_csv("result011621.csv", index = False) #
也曾进行过以下组合尝试,但最终效果不够优越
# final_result1 = 0.7*lasso_preds + 0.25*xgb_preds+0.05*elas_preds # final_result1 = 0.7*lasso_preds + 0.1*xgb_preds+0.2*elas_preds # final_result1 = 0.7*lasso_preds + 0.1*xgb_preds+0.2*elas_preds # final_result1 = 0.7*lasso_preds + 0.1*xgb_preds+0.2*elas_preds最终取得的kaggle分数是0.11327,排名进了1%