import pandas as pd
import numpy as np
train_data = pd.read_csv('train.csv',index_col = 0)
test_data = pd.read_csv('test.csv',index_col = 0)
train_data.head()
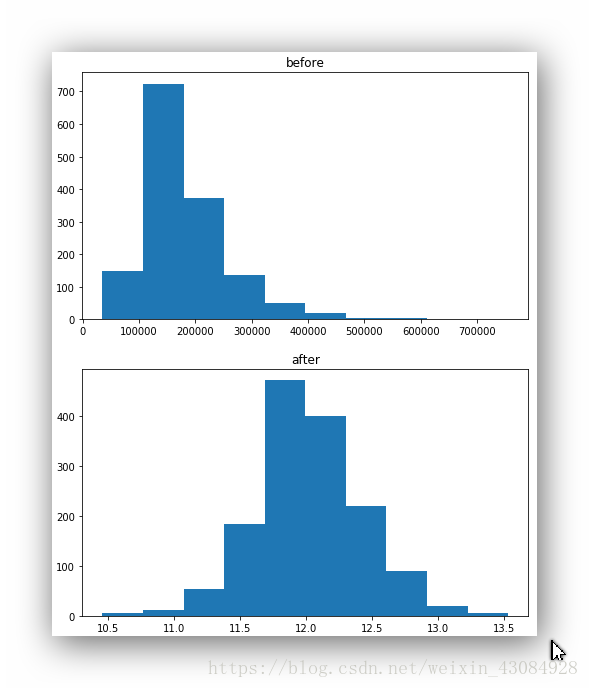
train_y_test = train_data['SalePrice'] #对比数据前后变化
train_y = np.log1p(train_data.pop('SalePrice')) #拿出Y然后进行分布均化
import matplotlib.pyplot as plt
plt.figure(figsize=(8,10))
plt.subplot(211)
plt.hist(train_y_test)
plt.subplot(212)
plt.hist(train_y)
在进行数据处理的时候,我们需要把y剔除在外,因为测试集中不存在这一列。预测测试集中的y是我们的工作。使用pop直接取出这一列并对y进行分布均化处理,结束了我们需要返回来,这里用了log1p,最后我们需要用expm1反向处理回来,当然也可以有其他的处理方法
MSSubClass这个特征的值虽然是数字的,可是这些数并不存在大小关系,其实这个特征是个类别变量(有些题会注明),在我们利用pandas载入数据的时候,pandas是会把它当成数值,破坏了特征原有的含义,我们需要将之手动转化为str,在进行虚拟编码处理。
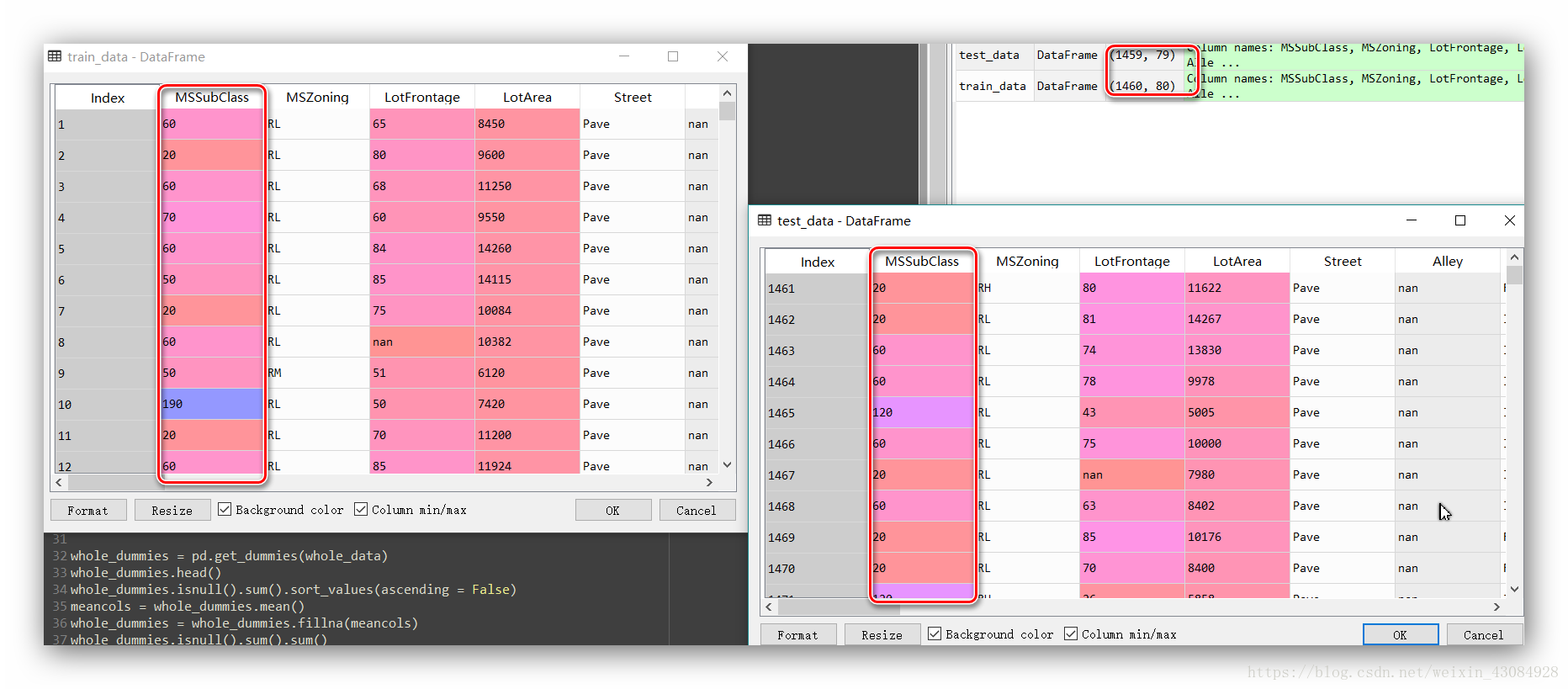
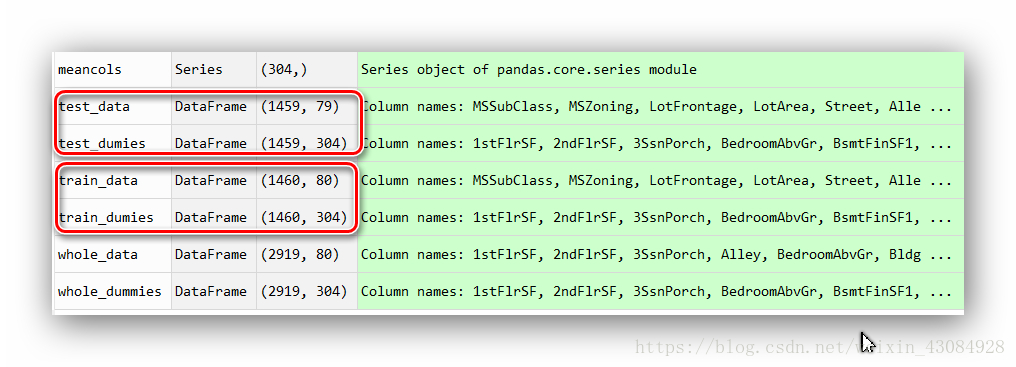
whole_data = pd.concat((train_data,test_data),axis = 0) #剔除y的train跟test的连接 shape:(2919, 80)
whole_data['MSSubClass'].dtypes #int64
whole_data['MSSubClass'] = whole_data['MSSubClass'].astype(str)
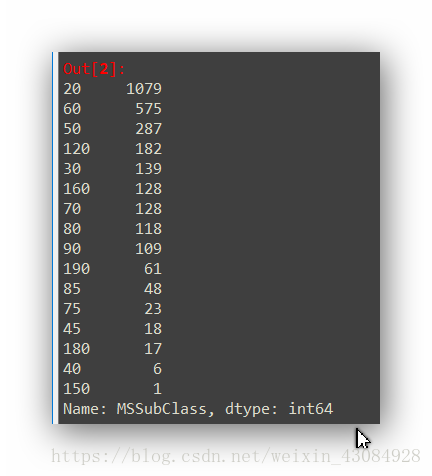
whole_data['MSSubClass'].value_counts() #查看类别分布情况
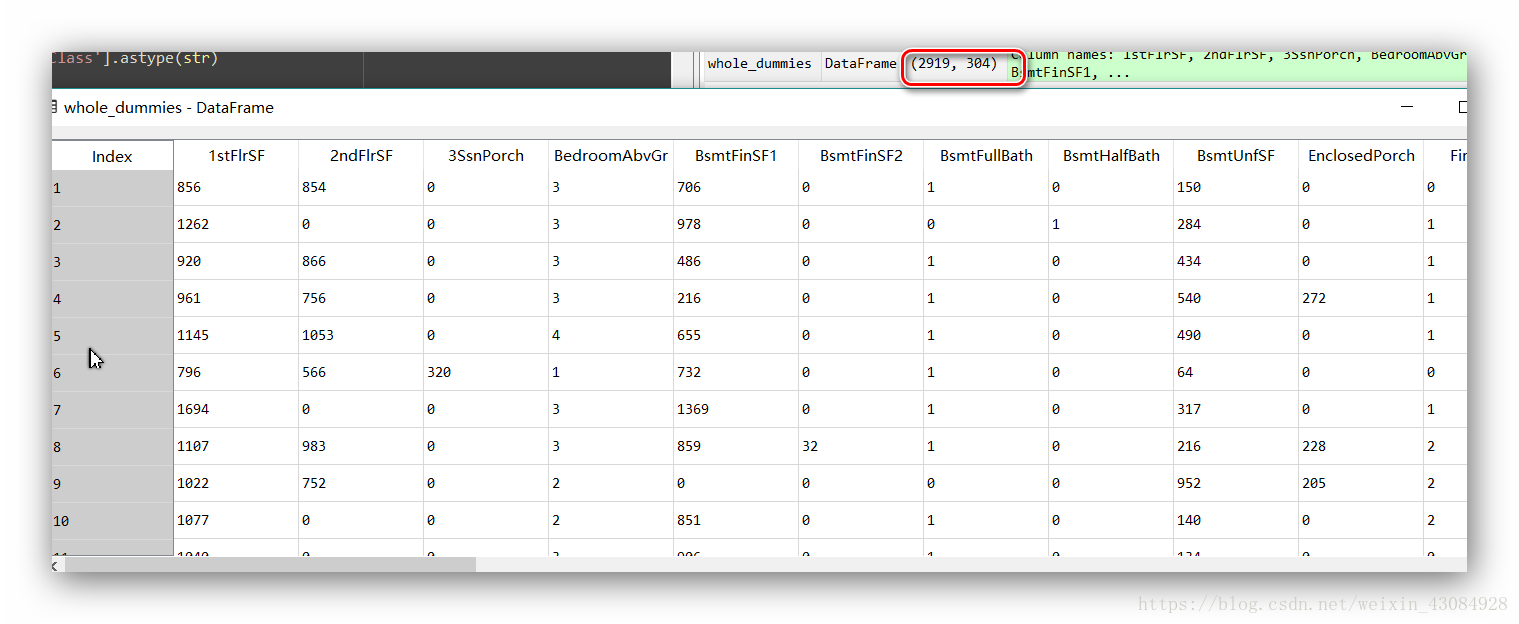
whole_dummies = pd.get_dummies(whole_data)
whole_dummies.head()
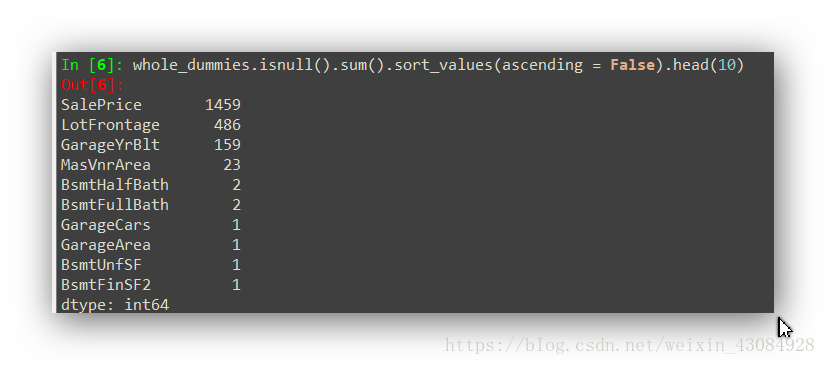
whole_dummies.isnull().sum().sort_values(ascending = False).head(10) #列举出前十个缺省值个数的特征
meancols = whole_dummies.mean() #取每个特征的均值
whole_dummies = whole_dummies.fillna(meancols) #这里我们使用均值填充缺省位置
whole_dummies.isnull().sum().sum() #计数显示是否处理完所有缺省值,0则表示缺省值处理完毕
pandas中get_dummies可以一键one hot处理,感受到pandas强大有木有!
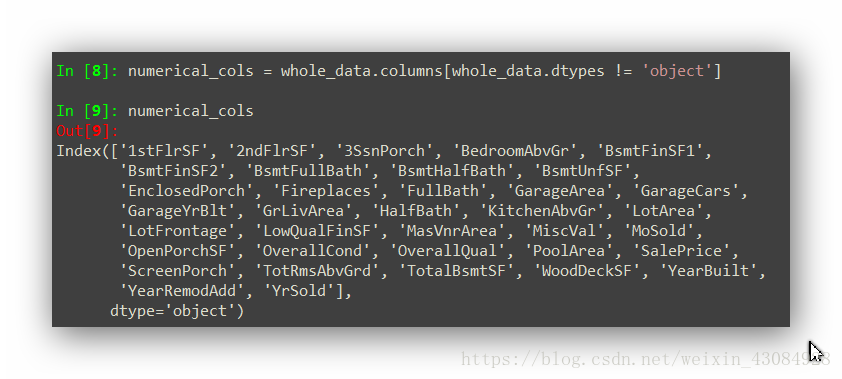
接下来需要对数值类的特征进行处理。首先筛选出数值型特征:
numerical_cols = whole_data.columns[whole_data.dtypes != 'object']
#对数值类特征也进行均化处理
whole_dummies.loc[:,numerical_cols] = np.log1p(whole_dummies.loc[:,numerical_cols])
#再根据索引进行分割成训练集跟测试集,跟没处理前的索引一致
train_dumies = whole_dummies.loc[train_data.index]
test_dumies = whole_dummies.loc[test_data.index]
from sklearn.linear_model import Ridge
ridge = Ridge()
from sklearn.model_selection import GridSearchCV
alphas = np.arange(1,10,0.2)
parameters = [{'alpha' : alphas}]
grid_search = GridSearchCV(estimator = ridge,param_grid = parameters,scoring='mean_squared_error',cv = 10)
result = grid_search.fit(train_dumies,train_y)
best = grid_search.best_score_
best_parameter = grid_search.best_params_
使用网格搜素进行参数调整,这里我逐步缩小alphas进行了3次,得到了alpha为8
#结果
ridge = Ridge(alpha = 8)
因为项进行stacking,做了一个森林模型,同样进行调参
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
max_features = np.arange(5,100,5)
parameter_rfr = [{'max_features':max_features}]
grid_search_rfr = GridSearchCV(estimator = rfr,param_grid = parameter_rfr,scoring = 'mean_squared_error',cv = 10)
grid_search_rfr.fit(train_dumies,train_y)
best_param_rfr = grid_search_rfr.best_params_ #{'max_features': 90}
#结果
rfr = RandomForestRegressor(n_estimators = 300,max_features = 90)
#拟合,预测
ridge.fit(train_dumies,train_y)
rfr.fit(train_dumies,train_y)
y_pre_ridge = np.expm1(ridge.predict(test_dumies))
y_pre_rfr = np.expm1(rfr.predict(test_dumies))
#整合模型,取均值最为最终结果。
y_final = (y_pre_ridge+y_pre_rfr)/2
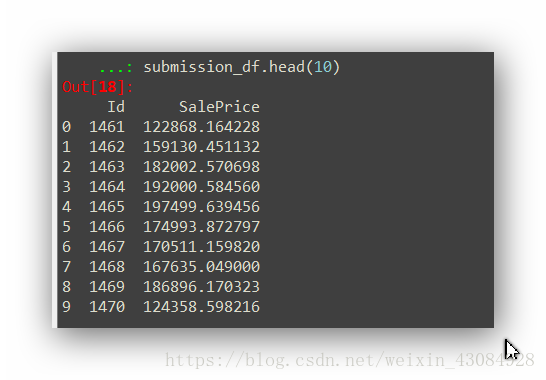
submission_df = pd.DataFrame(data= {'Id' : test_data.index, 'SalePrice': y_final})
submission_df.head(10)
整合文件。