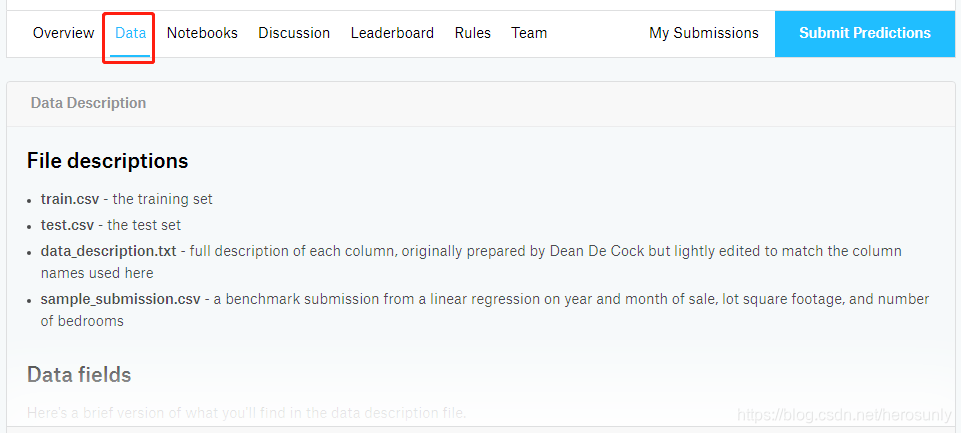
比赛链接为:https://www.kaggle.com/c/house-prices-advanced-regression-techniques。
练习的技能为:
- Creative feature engineering(特征工程)
- Advanced regression techniques like random forest and gradient boosting(高级回归技术,例如随机森林和梯度提升树)
1. 数据描述
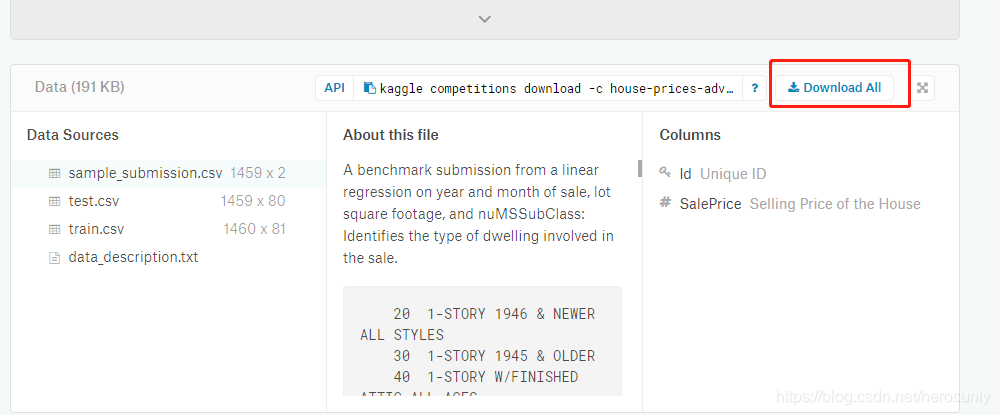
下载数据的方式如下:
3. 解决问题的思路
- 数据中是否包括字符串或者缺失值?如何把它们变成数值类型?
- 特征工程(为什么要进行特征选择,参数太多,一来计算量增加,二来容易造成过拟合现象。
- 算法的选择。
3.1 pandas_profiling
安装方法为:pip install pandas_profiling。
但在import pandas_profiling后,可能会出现ImportError: cannot import name ‘register_matplotlib_converters’。此时pip install --upgrade pandas就会消除该错误。
import pandas_profiling as ppf
import pandas as pd
import numpy as np
ppf.ProfileReport(train)
但可能会出现IOPub data rate exceeded的错误,如下所示:
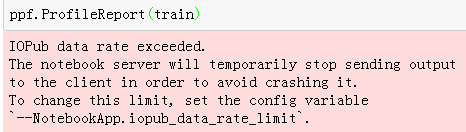
解决方法可参考:https://www.cnblogs.com/mehome/p/10567674.html,需要注意的是设置以后不光需要重启kernel,需要把jupyter notebook的启动程序关闭再进行重启。
3.2 facets
Facets分为两个组件,分别是overview和driver。前者可以对比训练集和测试集的特征分布比较。
4. 数据清洗
数据清洗指的是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗具体包括:
- 解决缺失值:平均值、众数、最大值、最小值或更为复杂的概率估计代替缺失值。
- 去重:相同的记录合并为一条记录。
- 解决错误值:用统计分析的方法识别可能的错误或异常值,如偏差分析、识别不遵守分布或者回归的值,也可以用简单规则库(常识性规则、业务特定规则等)。检查数据值,或使用不同属性间的约束、外部的数据来检测和清理数据。
- 解决数据的不一致性:比如数据是类别型或者次序型(这不是数字化嘛,解释感觉有点牵强啊)。
4.1 显示缺失值的情况
import pandas as pd
train = pd.read_csv(r'train.csv')
test = pd.read_csv(r'test.csv')
miss = full.isnull().sum() #得到Series
miss[miss > 0].sort_values(ascending = False) #Seires中进行条件选择
5.代码
train.drop(train[(train["GrLivArea"]>4000)&(train["SalePrice"]<300000)].index,inplace=True)#pandas 里面的条件索引
full = pd.concat([train,test],ignore_index=True)