转载。 https://blog.csdn.net/linolzhang/article/details/71075756
一. 问题的提出
Person Re-ID 全称是 Person Re-Identification,又称为 行人重检测 or 行人再识别,直观上可以通过两种思路进行比对,一种是 通过 静态图像(still-image)进行特征比对,另一种是通过视频的时序特征(temporal)进行 Video Re-Id。
不管是采用 图像特征比对的方法 还是 结合时序特征比对的方法,这里面有以下几个问题很大程度上影响作用效果:
1. 目标遮挡(Occlusion)导致部分特征丢失;
2. 不同的 View,Illumination 导致同一目标的特征差异;
3. 不同目标衣服颜色近似、特征近似导致区分度下降;
基于上述三个问题,人们提出了很多解决方案,主要Focus在以下几个方面:
a)提取更适合表征人体的特征,比如 color&LBP,Gabor,HOG3D,CNN等;
b)选择合适的距离度量函数,L2 norm,马氏距离等;
c)通过训练的方法(比如SGD、Adam)进行参数训练,或者空间映射,使得类内距离(intra dist)更小,类间距离(inter dist)更大。
二. 相关工作
根据上面提出的问题,我们知道问题聚焦在两个关键点,一是提取良好的特征,二是 选择合适的距离度量函数。
关于特征选择的方法比较多,上面也提到了,可以 refer 典型方法的目录索引。
2.1 特征提取
颜色空间:RGB、HSV、LAB、XYZ、YCbCr、ELF、ELF16
纹理空间:LBP、Gabor
专用特征:LDFV、ColorInv、SDALP、LOMO
2.2 距离度量
关于距离度量有 LFDA、MFA、LMNN、LADF 等(其他 L1 norm,L2-norm 都是早期的方法,可以不看):
马氏距离:Mahalanobis distance learning for person reidentification
2.3 CNN方法
Pair Wise方法(成对比较): FRNN、Ahmed et al、Siamense
逐对比较方法受对比次数影响,在训练和计算时 Candidate较大时计算量会很大。
Feature 提取:FFN、Multi-Channel Parts-Based CNN
通过CNN提取特征,并结合距离函数的改进,是引入深度学习的一个主流方法(后续我们展开讨论),实际上,CNN特征提取方法通过一系列的权值,实现了关键特征抽取,比如受 Pose、View、Illuminate影响较小的特征,比如通过 将轮廓外的权值置0,就起到了去除背景噪声的效果,当然我们不知道所提取的特征代表了什么,但这并不影响我们对于CNN方法的使用。
2.4 CNN特征简介
CNN For Re-Id的文献比较多:
FPNN
论文全称:DeepReID: Deep Filter Pairing Neural Network for Person Re-Identification Blog
第一篇引入 CNN for Re-ID 的论文,采用 FPNN 网络 (filter paring neural network) 进行训练,通过两个Patch对比来得到 True or False。
Ahmed et al
论文全称:An improved deep learning architecture for person re-identification Blog
针对上一篇文章的改进,加入了一个Cross-Input Neighborhood Differences 层,计算特征差异。
Siamense
论文全称:Deep metric learning for person re-identification Blog
该方法采用了 Partition的方法进行分块训练,网络也比较简单,这里我们要说一下,由于人体在运动状态下,部分特征变化比较剧烈,因此分块训练几乎是必须的,后面基于CNN的方法几乎都采用了 Part Model。
DTML
论文全称:Deep transfer metric learning
CVPR 2015 的 paper。
相关的文献实在太多,大家自己看吧,下面就 2016年三篇比较典型的 CVPR 进行展开讨论。
三. 典型方法
1. Person Re-Identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function CVPR 2016
主要贡献:
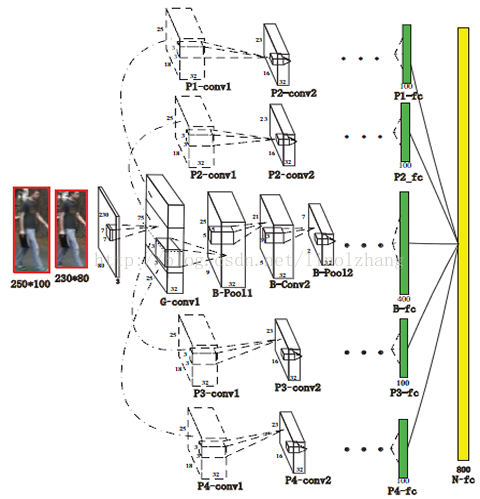
a)Multi-Channel Parts-Based CNN
多通道的 CNN,比较容易理解,一是 Global,通过Crop的全图做CNN;二是 Parts Model,将图像水平分割成多个部分,本文是分割成了4个部分,最后5部分通过全连接形成N维特征。
上面也讲到了,通过图像的水平分割,可以有效提取变化较少的部分特征(比如图像上半部分),CNN训练通过赋予该部分较大的权值,而得到比较好的特征提取提取效果,可以看下网络结构图:
b)Improved Triplet Loss
Triplet 相信都不陌生,在 FaceNet 中提出,通过构造一个 三元组 <I,I+,I-> 进行样本训练,来驱动CNN网络的改进。
其中 I为原样本,I+为正样本,I-为负样本,通过 Triplet 构造的约束满足:
Dist(I, I+) + T1 < Dist(I, I-)
也就是说要确保 类内距离 小于 类间距离,在这个基础上,作者加入了 第二个约束,即类内的距离要小于一个 常量。这样我们就得到了 Total Loss:
其中 dn = Dist(I, I+) - Dist(I, I-) < T1
dp = Dist(I, I+) < T2
β 为Balance参数,用来平衡上面的两个约束条件,当满足约束条件时(dn<T1),max取值为常数,因此在进行 SGD 梯度计算时没有贡献,否则会根据该距离值 沿梯度反方向进行修正。
需要说明一下,作者采用的距离度量函数为 L2-norm,就是传说中的欧式距离,至于改成其他距离度量方式(比如 马氏距离)有没有改进,大家可以尝试。
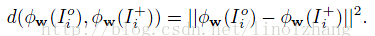
Φ 为基于CNN的特征映射函数,也就是基于权值w的函数。
训练过程
采用随机梯度下降法 (SGD) 进行训练,对上面的 Loss函数求导数,得到:
其中:
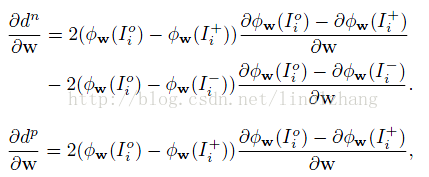
公式都比较简单,搞 CNN 的 SGD 是基本功了,不需要多说,考虑到完整性,还是把过程贴出来,比较清晰:
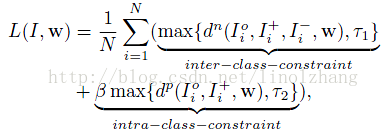
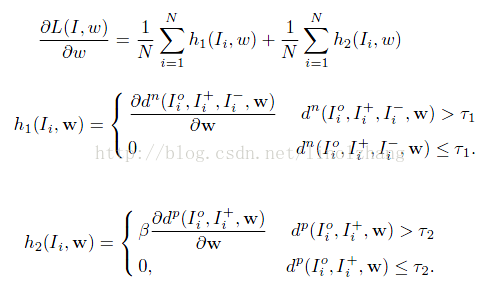

2. An Enhanced Deep Feature Representation for Person Re-identification CVPR 2016
论文下载:https://arxiv.org/pdf/1604.07807.pdf
主要贡献:
a)基于ELF 扩展了新的组合特征 ELF16;
使用color histogram features(颜色直方图特征:RGB,HSV,YCbCr,Lab 和 YIQ)和 texture feature(纹理特征:multi-scale and multi-orientation Gabor features),这个特征更具有区分性和紧凑性。
这是一个实实在在的组合特征,啥都用,反正就搞一大堆,这点上来说,我对该做法持谨慎态度。
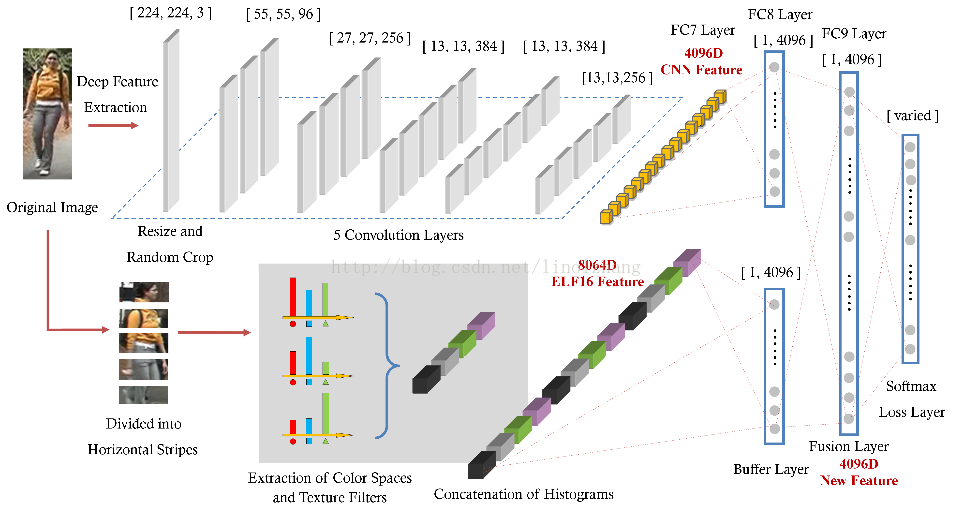
b)将上面的手选特征与CNN结合,提出 Fusion Feature Net(FFN);
作者是想通过 手动特征(Hand-crafted)与CNN提取特征互补,实现比 单纯的 CNN 或者 单纯的 手动特征 更高的目标区分度。
Fusion 框架实现特征融合,将CNN特征和手动特征映射到统一的特征空间。为了使 CNN 特征与手动特征互补。
作者认为:使用反向传播,整个CNN的参数均会受到 Hand-crafted 的影响。
网络结构图很清晰,上面的CNN网络采用了 Global 的特征卷积(生成 4096D Feature),下面的 Hand-crafted 组合 ELF16(生成4096D Feature),然后通过一个全连接的 Fusion Layer实现这两部分的特征融合,最后通过 Softmax 进行逻辑回归。
针对 组合特征 x [ELF16, CNN],Fusion Layer 按照公式(2)计算,其中 h 为激活函数(ReLU),同时采用了Dropout(ratio=0.5)。
根据反向传播算法,第 l 层的参数在新的一次迭代之后被写为:
作者通过 Softmax 计算Loss,对于一个单个的输入向量 x 和最后一层的一个单个的输出节点 j ,计算 Cross-entropy(交叉熵) :
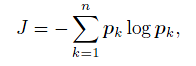
最后一层的输出节点大小不固定,与训练数据有关。
通过实验,作者发现,Fusion后的特征提取效果要比(ELF16+CNN-FC7)要好,原因在于Buffer Layer & Fusion Layer的整合作用,对特征权值自动调优。
【Metric Learning Methods】
度量学习也可以理解为子空间映射,对于样本距离的衡量有重要意义。
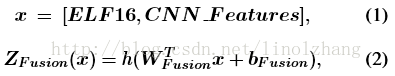
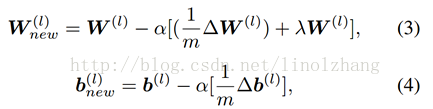
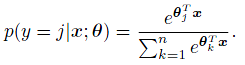
3. Top-push Video-based Person Re-identification CVPR 2016
论文下载: https://arxiv.org/pdf/1604.08683.pdf
主要贡献:
a)引入Pooling Color&LBP,HOG3D进行时序特征描述,非作者原创;
HOG3D比较早了,在行为识别中用的比较多,可以参考:
http://lear.inrialpes.fr/people/klaeser/research_hog3db)通过对 文献【15】- 点击下载 扩展,提出 TDL方法,即 Top-push distance learning model;
TDL方法是一种空间映射,目的在于 减小类内(intra)距离,增加类间(inter)距离,提高目标的可区分度。
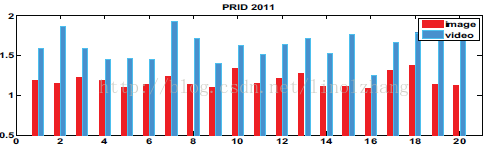
基于 Video 的方法相较于 Still-image 的方法目标相似度更高,按照作者的说法是 除了Appearance之外,Motion也很相似,作者给出了基于PRID数据集的对比:
其中比率Ratio值 为 类内距离 / 类间距离(dW/dB),可以看到,基于Video的方法类间区分度更低,So 必须需要一种空间映射方法来做处理,将类内距离缩小,类间距离放大,从而从微小的差异中挖掘出有价值的判别方法。
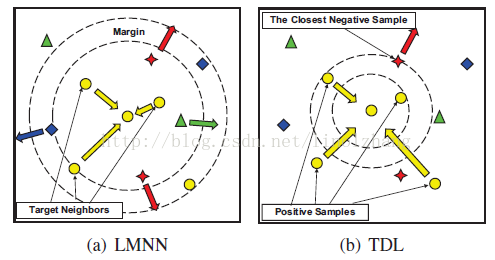
TDL与 LMNN 方法类似,拉近正样本之间的距离,对错分的负样本数据进行惩罚,区别在于 TDL 强调对Top-Rank的样本处理,即 仅处理距离最小的负样本,如下图b:
来看公式:
上面公式 描述了距离,其中 ρ 表示 正样本距离 与 负样本距离的 最小间隔,也就是上图(b)的同心圆的半径。
下面公式 定义了 Loss Function,当 D(x,x+)+ρ 小于 D(x,x-) 时,符合判别公式,Loss值<0,因此 该子项 max(Loss,0)=0
结合正样本类内距离约束 D(xi, xj),我们得到最终公式:
其中 α 为 Balance参数,与 Triplet里的 β 一致,整体公式与 Triplet也很像,找到感觉了吧?
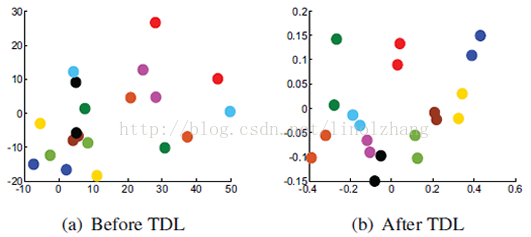
通过映射得到的映射后的距离关系图(基于PRID 2011数据集),貌似效果很好:
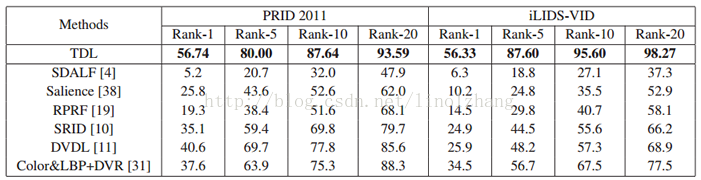
接下来是优化算法,采用了马氏距离度量,作者将 距离转换为矩阵的迹(Trace),D(x,y) = tr(M Xi,j),训练过程采用 随机梯度下降法(SGD),这段就不细说了,大家自己看吧。数据集实验结果:
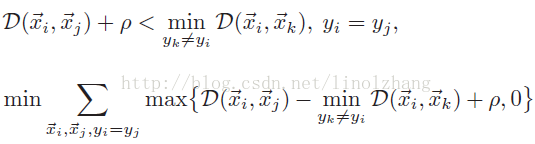
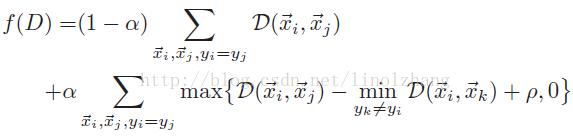
四. 参考数据集
数据集
CUHK01/02/03
PRID2011
VIPeR
i-LIDS
iLIDS-VID
内容
CUHK01 校园 2 views
CUHK02 户外 5 views
CUHK03 户外 5 views
相机:2
有200person两个镜头出现
相机:2
光线、姿态变化较大
机场到达厅
non-
overlapping
300人600个视频,
i-LIDS为其采样
大小
01 – 971 person(160*60)
02 – 1816 person(160*60)
多数有负重(背包行李)
03 – 1467 (vary Res)
A:385 person
B:749 person
Res:128*64
632 person
Res:128*48
479 image
119 person
Res:128*64
300 person
不固定尺寸
完整数据集参考: Person Re-identification Datasets (包含说明及下载地址)
--------------------- 本文来自 jk英菲尼迪 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/jialibang/article/details/82842448?utm_source=copy