本文作者提出了一个这样的框架:
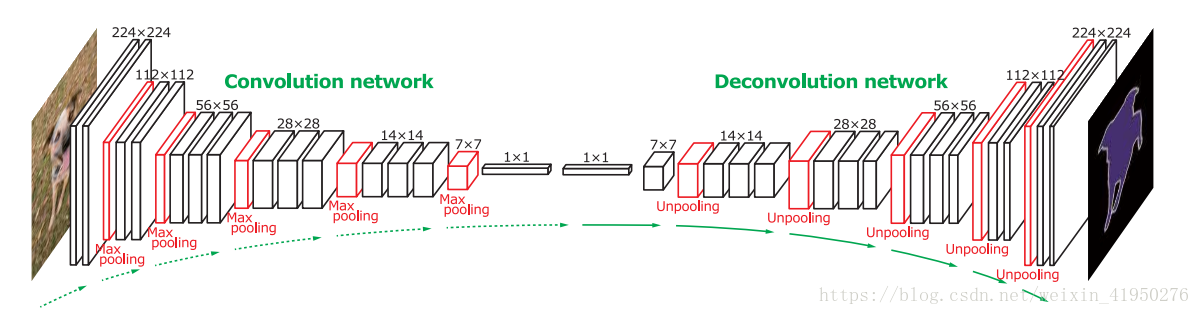
这样的一个框架作者把他命名为EDeconveNet,这个框架有两部分组成一个是 convolution networks 一个是deconvolution network。
本文提出了FCN在图像语义分割的时候主要注重物体的整体轮廓,而忽略了细小的特征,本文正是修正了这一缺点。
在convolution network中我们提取high-level semantic imformation,由于卷积和pooling层的使用,此时虽然会得到语义信息,但是同时也会损失掉localization imformation,这也是卷积网络在semantic segmentation中的一个无法避免的地方,所以CNN非常适用与classification而不能直接应用于senmantic segmentation。但是在本文中提出了一个很好的pooling方法,如下图:
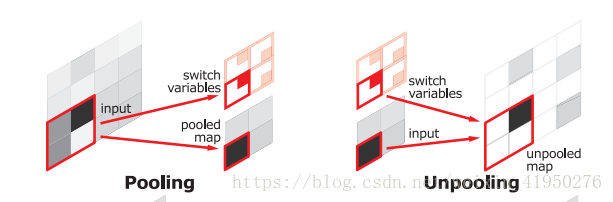
在进行pooling的时候,用一个switch variables进行存储activations的位置信息这样在进行unpooling的时候就可以很好的进行还原,localization imformation的缺失降低到最小。
在decovolution network中主要起的作用就是upsampling。
在training过程中作者也是用了一些小技巧使网络能够在小样本上训练,作者在每一层都加了Batch Normalization的过程,训练分为两步:第一步使用一些比较容易的的训练样本训练网络。比如手工指定proposal的位置,背景不复杂的图片等,在第二步中,为了能够使网络达到instance-wise的效果,作者使用较难的样本对网路进行fine-tune。
Ensemble with FCN
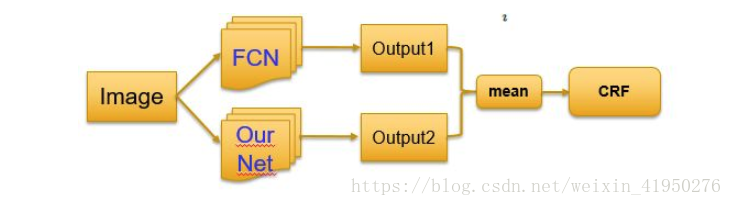
将FCN对于能够很好的获取整体结构,对于EDeconveNet能够很好的获取细节信息,将这两种方法融合得到了最好效果。
Instance-wise Segmentation:
把每张图片截切为很多子图片,每张图片包含一个实例。每张子图片进行输入,得到分割结果,再把这些结果聚合起来,得到整张图片的分个图
注:个人理解这里的子图片是由于你在convolution network中用不同的kernel对原图片进行卷积,不同的卷积核会选取不同的图片上的objects,从而会产生很多子图片。