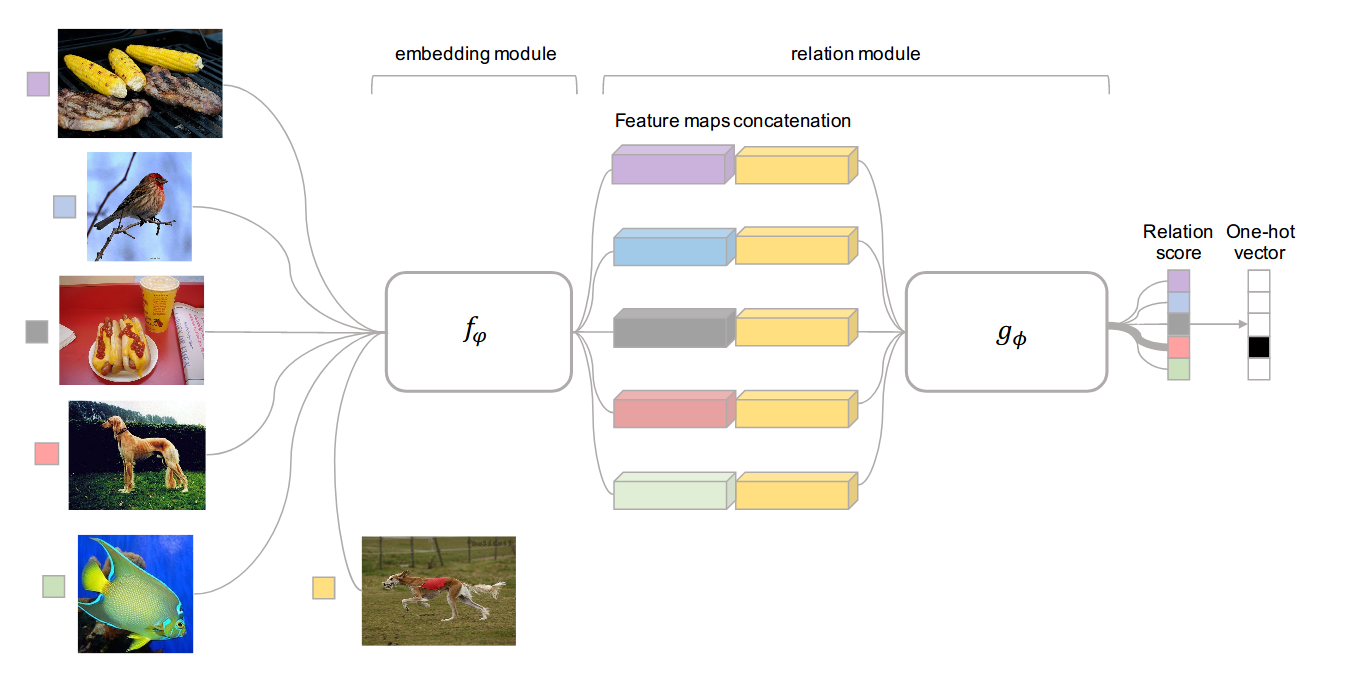
主要原理,如下:

其中,g表示关系深度网络,C表示concatenate,f表示特征提取网络(branch)
训练中每个episode/mini-batch包含样本数量=N*C
其中C是类型数量,N = sample images + query images
论文中区分了sample images和query images,我认为没有必要,训练时无差别对待它们,能获得更多的样本组合。
结构示意图如下,其中sample的feature是K个样本feature的均值。
主要原理,如下:
其中,g表示关系深度网络,C表示concatenate,f表示特征提取网络(branch)
训练中每个episode/mini-batch包含样本数量=N*C
其中C是类型数量,N = sample images + query images
论文中区分了sample images和query images,我认为没有必要,训练时无差别对待它们,能获得更多的样本组合。
结构示意图如下,其中sample的feature是K个样本feature的均值。