题目:Dueling Network Architectures for Deep Reinforcement Learning
来源:ICML 2016 Best Paper
摘要
在最近几年中,在强化学习中使用深度学习的表示取得了很大的成功。这些应用依然使用了比较传统的架构。比如卷积网络,LSTM或者自动编码器。在本文中,作者提出了一个新的用于model free强化学习的神经网络结构,在dueling network中,作者设计了两个独立的estimator,一个是状态价值函数(state value function),一个是状态依存动作优势函数(state-dependent action adantage function)。这样做的好处是可以在不改变底层强化学习算法的条件下在动作间归纳学习。实验结果显示,这种构架在多种价值相似的动作面前能带来更好的评估策略。这一构架使得我们的强化学习智能体达到了在Atari 2600最先进的结果。
基本思想
文中提到,伴随着强化学习和深度学习的结合,我们在相关领域取得了很多进步,比如DQN等等。但是,最近的研究专注于设计和改善像化学系算法,并没有想到创新一种适合于model free的神经网络架构。这样做可以在不改变强化学习算法的基础上提升其表现。
下面讲state-dependent action adantage function是个什么东西。我们看下图,也是论文中给出的例子:
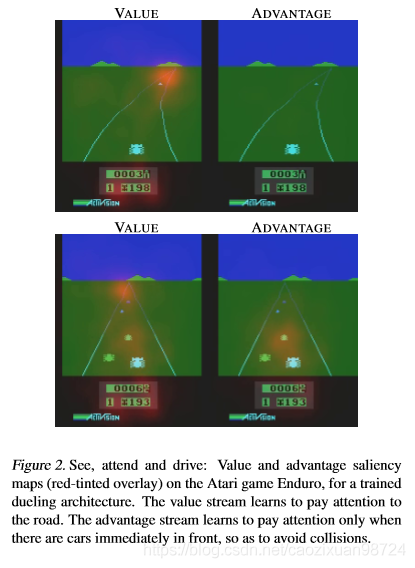
通过这个例子,我们可以看到value function和state-dependent action adantage function关注点是不一样的。value function无论周围车况,其始终关注的是路,而state-dependent action adantage function则有所区别,周围没有车的时候其什么都不关注,有车的时候开始关注周围的车。
从直觉上讲,state-dependent action adantage function关注的是一个动作有没有价值,且不需要学习每个动作对每个状态的影响。在那些动作不会以任何相关方式影响到环境的状态中,这就特别有用。
。。。看不懂了,等看懂了接着写。
