Abstract.
1.existing methods of semantic segmentation still suffer from two aspects of challenges:
(1)intra-class inconsistency(类内的不一致) (2).inter-class indistinction(类间的模糊不分明)
2.we propose a Discriminative Feature Network ( DFN ) ,
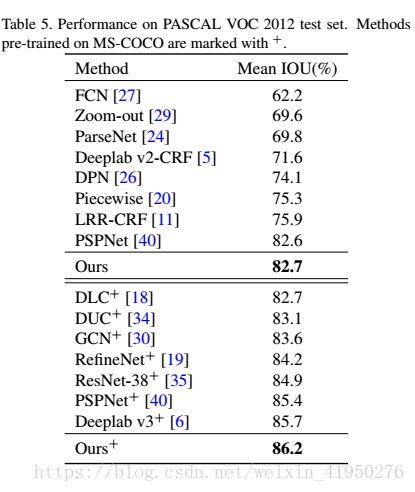
DNF = Smooth Network + Border Network
(1)处理类内的不一致问题:
Smooth Network = Channel Attention Block+global average pooling+RRB
这样可以选取更加具有判别性的特征。
(2)处理类间模糊的问题
Border Network
这样可以使边界的双边特征更加分明
Introduction.
介绍中主要讲了FCN和之前的一些方法,这些方法都有以下两个方面的缺点:1)patches有相同的semantic label,但是appearances是不同的,往往被分割为两个不同的objects。2)两个相邻的patches有不同的semantic labels,但是appearances相同,往往也会被误判为两个相同的objects
examples:

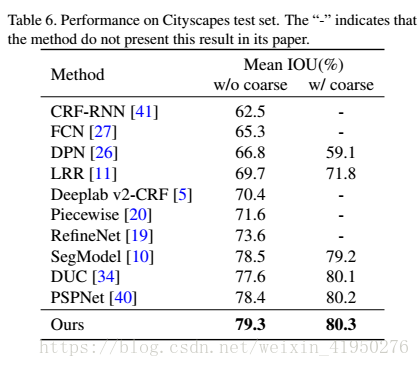
the architecture pf ours:
对于Smooth Network我们需要解决两个问题:
(1)我们需要多个规模的和全局内容的information对于局部和全局的信息进行编码,所以在这个结构中我们采用了U-shape的network去获取多尺度的内容信息,然后用global average pooling去获取全局的信息,作者还采用了Channel Attention Block(CAB)的机制去用high-level features 引导对于lower-level features的选择。
对于Border Network:
(2)Border Network用来去分割两个有相同的appearances但是有不同的semantic labels的patches
Related Work.
Encoder-Decoder
对于FCN内在的对于不同的级别的features进行了编码,有些approches就把他们进行融合对final prediction
达到refine的效果。这些方法最主要的就是考虑如何去恢复spatial information在这里有SegNet,U-net,LRR,RefineNet
SegNet , U-net , LRR , RefinNet :这些之前的方法都没有考虑到global context,而且大部分像这样的方法都是对于相邻部分的特征进行总结,而没有考虑到他们之间的多种多样的representation,这会导致类内不一致的结果
Global Context
global average pooling => Spatial Pyramid pooling => Atrous Spatial Pyamid Pooling
ParseNet PSPNet , Deeplab v3
Attention Module
注意力机制指的是把那些值得关心的部分赋予高的权重,给他最大的注意力,对一幅图中最重要的patch给予最大的关注。
Semantic Boundary Detection
语义边界识别中的大部分的方法是直接把不同的level的features串联起来去提取boundary
Method
在Smooth Network中我们采用ResNet作为基本的model,在low stage中感受野的size比较小只能encode spatial information,而对于语义的连续性比较差;但是在high stage他有很强的语义连续性,因为他有很大的 感受野,但是prediction在spatial上会很模糊。于是我们结合了low stage和high stage的特点去达到更加好的效果。
在现在流行的语义分割的结构中,这里主要有两种风格:
(1)‘Backbone-Style’ 典型的approches如,PSPNet,Deeplab v3;这种类型的方法主要是用‘Pyramid pooling module’和’Atrous spatial Ptramid Pooling module‘注入不同尺度的信息去提高网络的连续性
(2)'Encoder-Decoder-style'典型的方法如,RefinNet ,Global Convolutional Network;这种方法主要利用在不同stage的内在的多种尺度的context,但是它缺乏global context,在global context中含有很强的连续性。
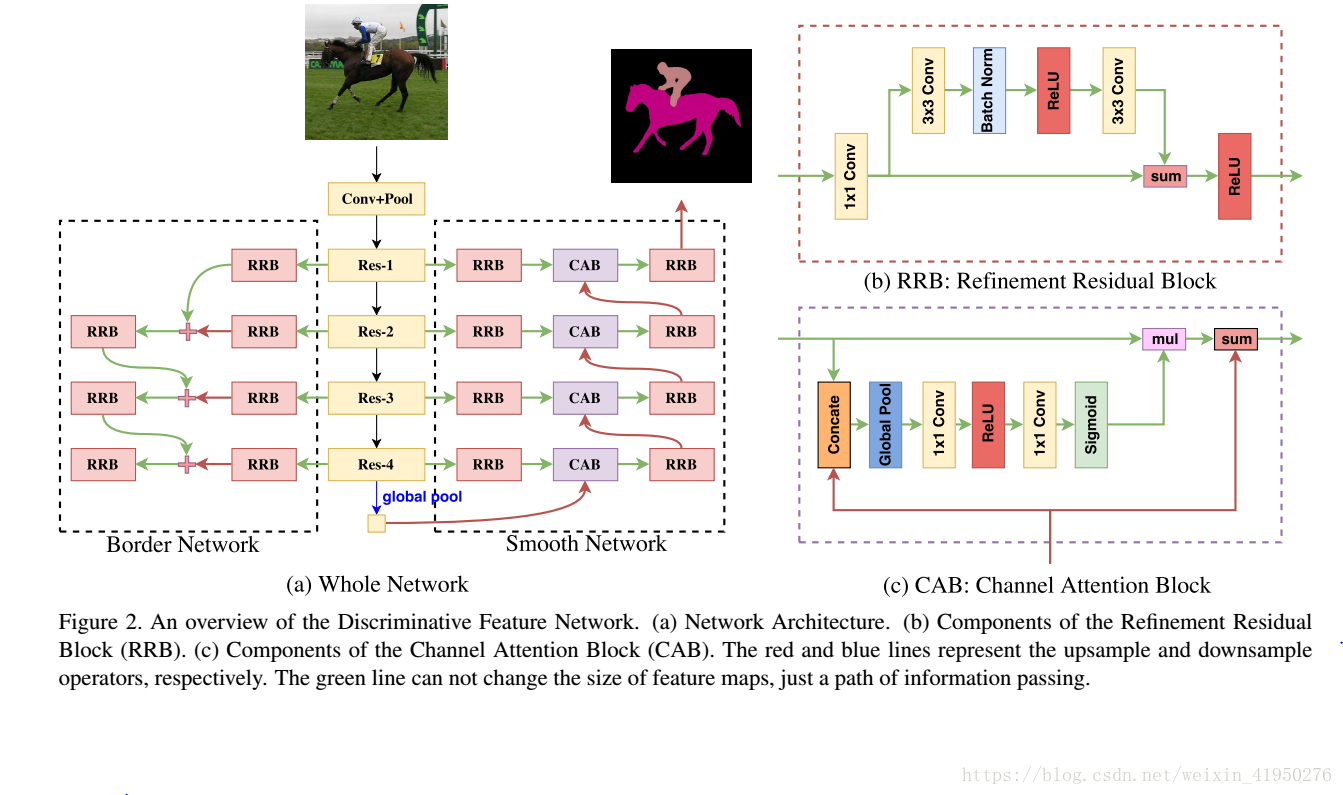
我们用了global average pooling layer把U型结构变为了V型结构,而且给网络注入了很强的一致性。其次我们设计了一个Channel Attention Block,它把相邻的部分结合起来计算得出一个channel attention vector,而这个 channel attention vector 可以攒去具有辨别力的特征。
Channel attention block
architecture:
主要就是从low stage到high stage对于discrimination有不同的能力,应我们采用channel attention block去调整不同channels的权值,给予那些鉴别能力好的大权重,而鉴别能力差的小权重。
Refinement residual block
主要用来去refine feature map,这个模块同时也可以增强每个stage的识别能力。
Border network
作者使用Border network去增加类间的特征区别,在section3.1中作者就说过low stage features有很详细的信息,而high stage features有更高度的语义信息,于是作者设计了一个自下而上的Border Network,用它来获取更清晰的边界信息

Stage-wise refinement :
Smooth Network 使用了一种自上而下的方式,将high stage的信息传递到low-stage 去保证inter-class consistency;而Border Network使用了一种自下而上的方式,用low stage的edge information去改善semantic boundary