文章目录
1 摘要
针对单纯的FCN网络存在忽略小物体、分解大物体的问题,当时通常地做法是使用CRF做后处理进行对分割结果进行调整。而本文提出了DeconvNet,该网络可以拆解成反卷积层和反池化层,可以很好地解决上面FCN出现的问题并完成语义分割任务。作者最后发现DeconvNet和FCN能够非常兼容地进行合并,因此作者最后将FCN和DeconvNet结合能产生更好地效果。
2 亮点
2.1 解码器结构
解码器结构由反卷积层和反池化层组成。
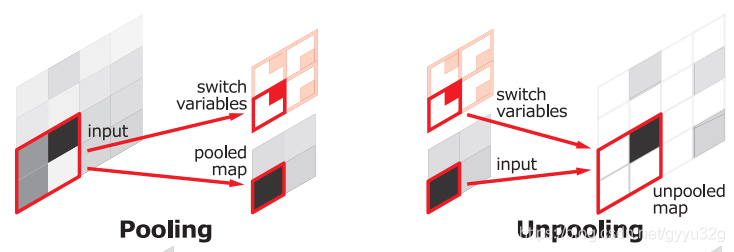
2.1.1 反池化层
反池化层就是通过在前面池化的过程中记录最大池化的位置,然后在反池化的过程中,利用小图的值去填充到之前记录的位置,其它地方使用0填充,这样能大致恢复图片的模样。由于池化时只记录了最大值地位置,这样做可以大量地节省了内存。
2.1.2 反卷积层
由于使用反池化得到的特征图像通常是稀疏的(填充了很多0),这时候就接反卷积层能够将稀疏的特征信息变得稠密,反卷积的过程可以参考下图:
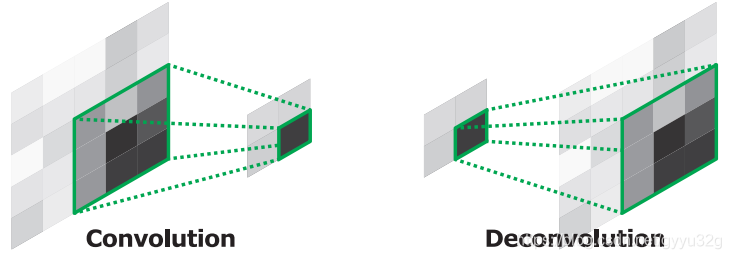
反卷积可以通过一个小特征图上采样还原成大图或者同样大小但是稠密的特征图。
2.1.3 反池化和反卷积结合
解码器使用反池化和反卷积进行结合,可以使图像由稀疏图一步步变得稠密。如下图:
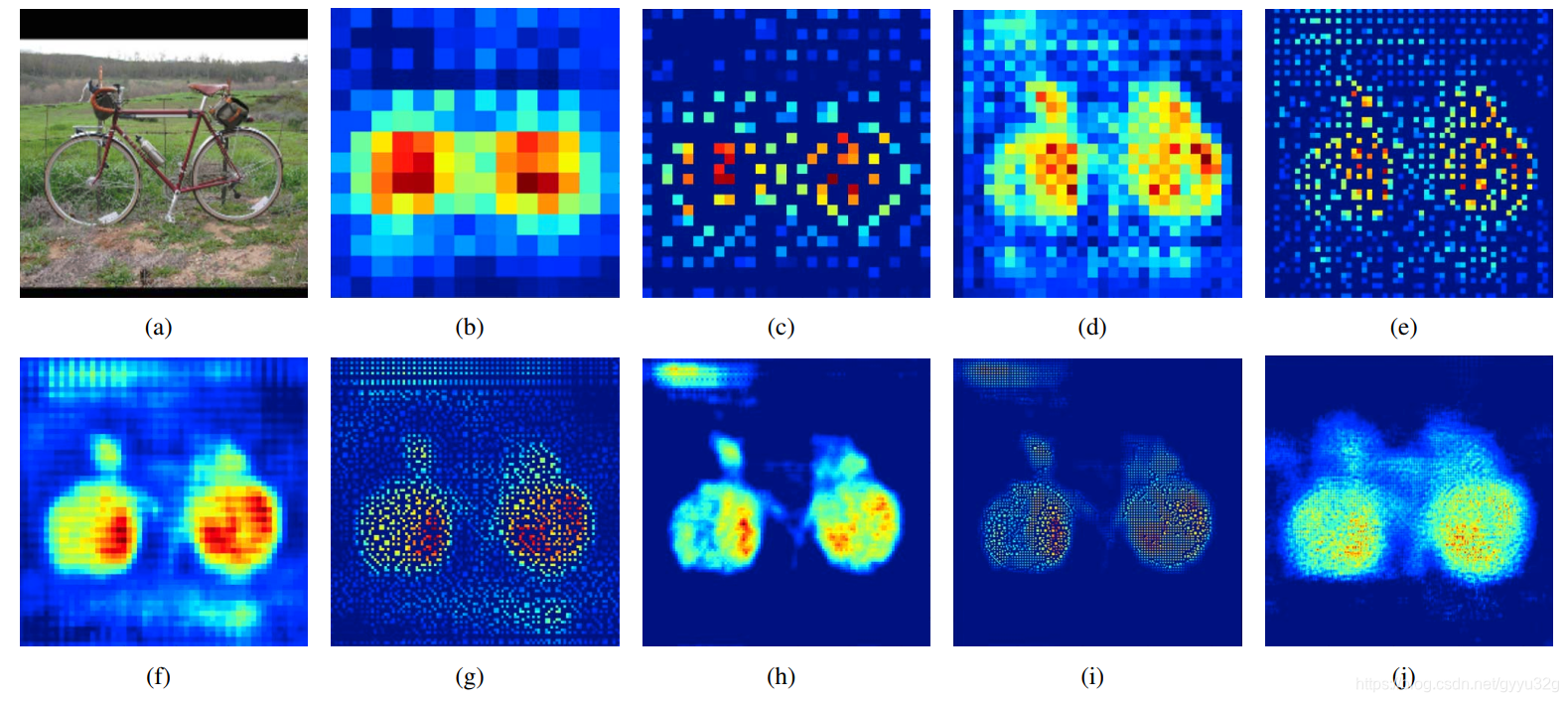
(a)为原始图像,经过编码器进行特征提取以后得到的(b)是14x14的图像,经过一个上池化得到28x28的(c),可见(c)是很稀疏的。然后经过3个反卷积得到(d),这里使用反卷积的大小并没有改变,(d)依然是28x28;经过上池化得到(e)56x56,接三个反卷积得到(f);经过上池化得到(g)112x112,接两个反卷积得到(h);经过上池化得到(i)224x224,接两个反卷积得到(j);可见(j)已经是一个稠密的特征图了,就是通过一层层池化+反卷积使稀疏特征图变得稠密。
2.2 网络整体结构
作者提出单纯使用FCN,FCN网络存在两个问题:
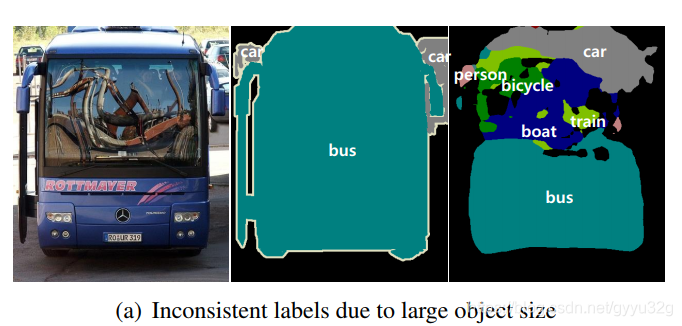
① 由于FCN的感受野是固定的,所以不适合分割不同尺度的图像,如有时候目标尺寸过大而感受野不够大,则会出现将大目标分解成许多小目标的问题,如下图:
② 由于解码器阶段使用的反卷积太过于简单,虽然使用了跳跃结构进行了特征的融合,但是还是有很多细节无法恢复。如果目标的尺寸过小如下图,感受野则会忽略了目标。

所以作者才提出的DeconvNet,而DeconvNet关键部分在于解码器部分,其总体结构如下图:
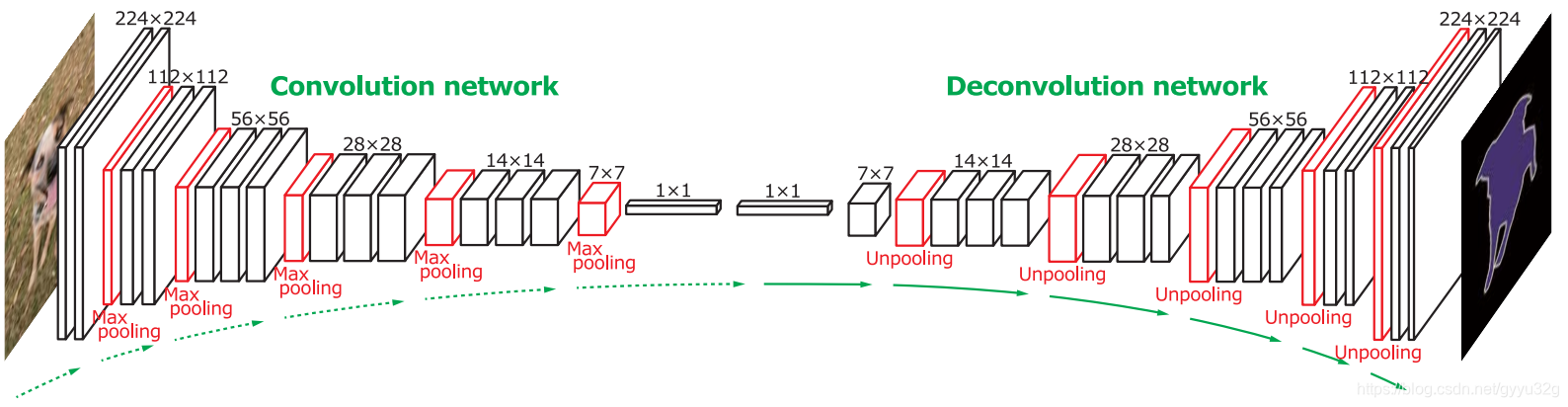
编码器就是VGG16的改进(将全连接层改成全卷积层),解码器部分就是由上池化和反卷积不断地对编码器提取的特征图进行放大并使特征稠密。可以说编码器作用在于提取特征,解码器作用在于将小尺寸的特征图放大,但是放大的时候需要精调使得特征图的结果看起来不那么稀疏。
3 部分效果
3.1 FCN和DeconvNet的对比

从上图可以看到,Deconvolution Network能够将图像分割得更加细致。
3.2 各个网络效果对比
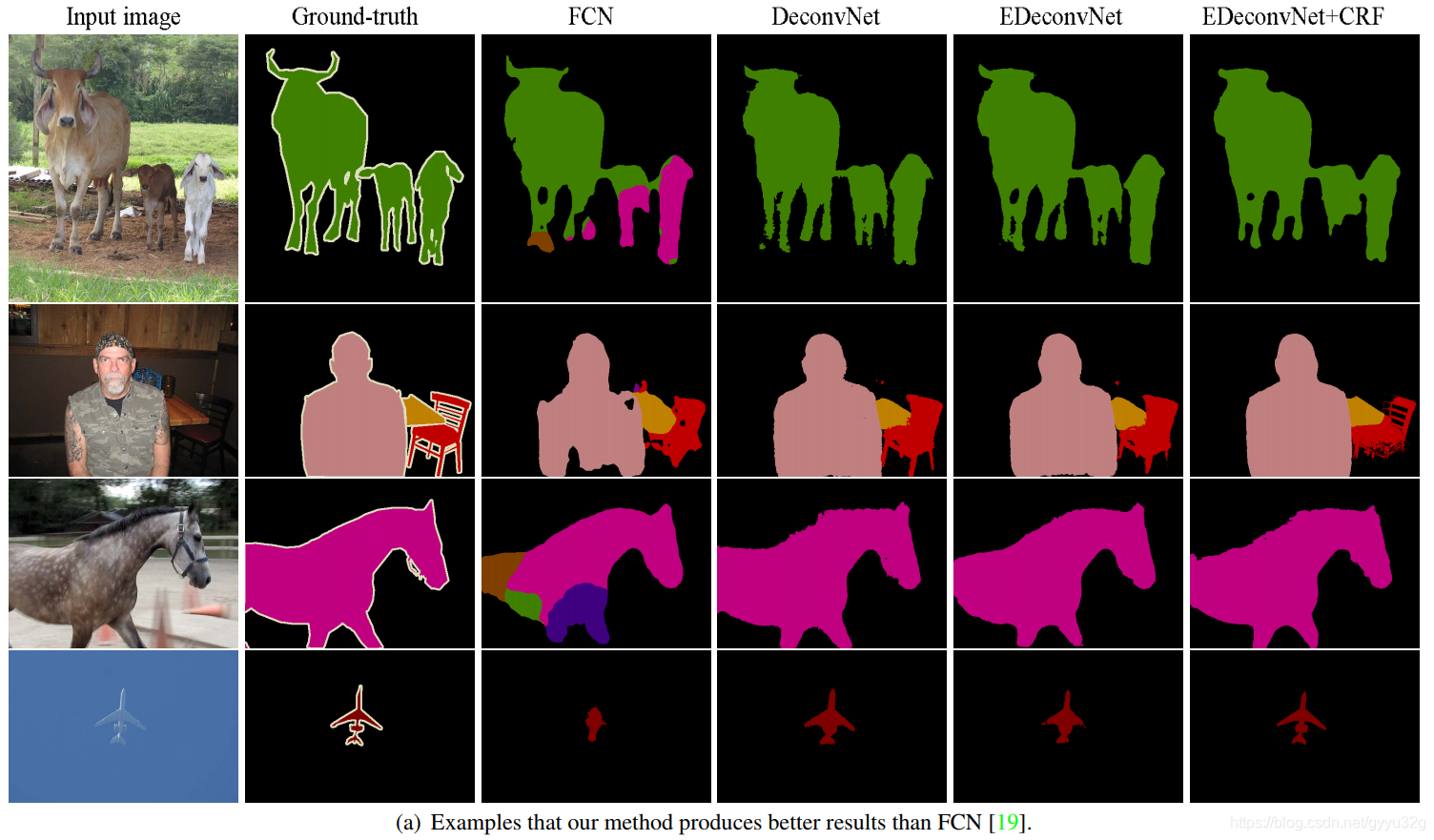
FCN、DeconvNet、EDeconvNet(FCN和DeconvNet方法结合)、EDeconvNet+CRF(使用CRF做后处理),可见,FCN和DeconvNet非常兼容,在DeconvNet上使用FCN方法能取得更好的效果,如果加上CRF做后处理,效果更佳。
4 结论
本文提出的DeconvNet在一定程度解决了FCN进行图像分割时的同一感受野带来的一些问题,而且,作者发现本文的方法和FCN又非常兼容,二者能够相辅相成,使得准确率更高。
5 参考文献
(1)Learning Deconvolution Network for Semantic Segmentation
(2)论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
