Sequence to Sequence Learning with NN
《基于神经网络的序列到序列学习》原文google scholar下载。
@author: Ilya Sutskever (Google)and so on
一、总览
DNNs在许多棘手的问题处理上取得了瞩目的成绩。文中提到用一个包含2层隐藏层神经网络给n个n位数字排序的问题。如果有好的学习策略,DNN能够在监督和反向传播算法下训练出很好的参数,解决许多计算上复杂的问题。通常,DNN解决的问题是,算法上容易的而计算上困难的。DNN就是解决这个问题,将计算上看似不易解的问题通过一个设计好的多层神经网络,并按照一定的策略轻松解决。
但是,DNN有一个明显的缺陷:DNN只能处理输入、输出向量维度是定长的情形。对于输入、输出可变长的情况,使用RNN-Recurrent Neural Network更易求解。
对于一个RNN,每一个cell通常是使用LSTM。也有GRU替代,GRU精度上可能不如LSTM,但计算上更加简便,因为他是对LSTM的简化。
这篇论文的模型类似于Encoder-Decoder的模型,Encoder和Decoder的部分采用两个不同的RNN,之所以采用不同的RNN是因为可以以很少的计算代价训练更多的参数。
具体的说,这个Sequence to Sequence的学习中,首先将可变长的Sequence用一个RNN提取出特征向量—定长的,这个特征向量取自飞一个RNN的最后一个LSTM单元。
之后,把这个向量输入另一个RNN(语言模型),如条件语言模型,使用beam search计算出概率最大的句子,得到输出。
本文的创新之处在于,源串作为第一个RNN的输入,其中的每一个单词是逆向输入的。这样做得到了更高的BLEU分数。
虽然本文的模型没有超过当下最好的模型的得分,但其逆向输入的方法提供了新的思路。
二、模型
本文的模型如下:这是一个英语 –> 法语的翻译模型:
源串是CBA,得到输出WXYZ。
数据集:WMT’14 English to French dataset。
使用的词典是英文16万词,法语8万词。词向量已经训练好。未知单词采用UNK。句子结尾为EOS。
![clip_image002[1]](https://images2018.cnblogs.com/blog/1044022/201808/1044022-20180806211708909-7394795.jpg "clip_image002[1]")
三、训练细节
- 使用的是4层LSTM单元,深层的LSTM表现的更好
- 每一层1000个LSTM,也就是说,循环1000次(因为大多数句子30词左右,其实这有点浪费)
- 初始化参数使用服从均匀分布U(-0.8,0.8)随机初始化
- 解码阶段输出层概率采用的是一个很大的softmax,这个占用了绝大多数的计算资源
- 词向量维度是1000维度的
- 学习过程中,使用随机梯度下降,学习率初始0.7,迭代7.5次,前5次固定学习率是0.7,之后每半次迭代学习率减半一次
- 使用mini-batch,每个batch是128个句子
- 为了避免梯度消失和梯度爆炸,限制梯度大小。如果梯度g的二范数||g||大于5,就进行g = 5*g/||g|| 的转换。
- 为了解决上面提到的,LSTM横向1000次是浪费的,但我们可以尽可能让同一mini-batch里的句子长度几乎相同。这样是2倍加速效果的。
- 本文的实验采用8个GPU,其中4个用来处理LSTM的每一层,其余的处理softmax层。
四、实验结果
一方面实验直接对本文的模型以及其他经典模型求BLUE比较,并且对本模型也对不同的超参数做了对比。
另一方面,与统计的机器翻译模型一起使用,通常会比直接使用RNN得分更高。这样做的结果如下:
此外,实验发现,LSTM对长句子表现的更好。
实验还对针对不同句子长度的BLUE得分做了分析:
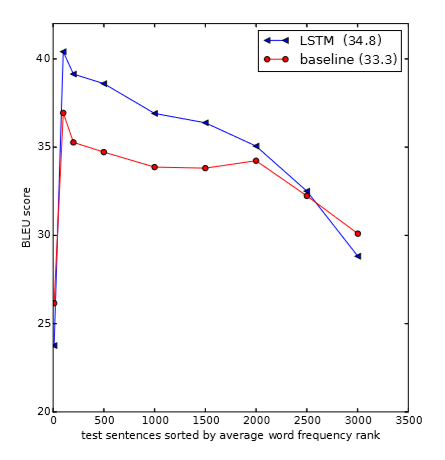
对不同句子的平均词频下的BLEU得到做了分析:
![clip_image003[1]](https://images2018.cnblogs.com/blog/1044022/201808/1044022-20180806211709624-2119189990.png "clip_image003[1]")
![clip_image005[1]](https://images2018.cnblogs.com/blog/1044022/201808/1044022-20180806211711398-340052630.jpg "clip_image005[1]")
![clip_image006[1]](https://images2018.cnblogs.com/blog/1044022/201808/1044022-20180806211712108-1562859705.png "clip_image006[1]")
![clip_image007[1]](https://images2018.cnblogs.com/blog/1044022/201808/1044022-20180806211712719-1505837300.png "clip_image007[1]")
{kind=link}
五、结论
本文得出的结论如下:
- 使用LSTM的RNN MT可以战胜传统的基于统计的MT—>STM。
- 源句子反转输入对于模型提升的帮助很大。这个没有数学解释,但一个通俗的理解是:目标句子与源句子开头的短时联系更加紧密了,在一个就翻译的初期,目标句子开头翻译质量的提升,提高了整体翻译的质量。
六、其他
还有一些人研究其他的机制。
- 编码并不采用RNN,而是使用CNN,这样编码的向量/矩阵改变了语序的问题。
- 有些人致力于将RNN结合到传统的STM中去。
- 有一种注意力机制。这种机制考虑到Encoder可能并不能完全提取源句子的所有信息,所以使用编码成向量+生成注意力向量 -> 在解码的每一步都线性组合出新的条件(源句子信息)。这样做的好处是在解码生成每一个单词的过程中,网络对源句子中不同的单词更加感兴趣,这可以提高翻译质量。