论文地址:Network Slimming
论文总结
本文提出了一种channel-level的裁剪方案,可以通过稀疏化尺度因子(BN层的scaling factor)来裁掉“不重要”的channel。
文中的方案为:
- 在训练时,对BN层的scaling factor施加 L 1 L_1 L1正则化,在训练网络的同时得到稀疏化的尺度因子;
- 裁掉低于指定阈值的channel;【(1)设定裁剪的百分比;(2)依据百分比找到所有尺度因子对应的值作为阈值;(3)逐层进行裁剪】
- 对得到的模型进行fine-tune以恢复因裁剪损失的精度。
论文介绍
本文的方法名为network slimming,通过裁剪每一层的channel数,达到模型压缩的目的。本文选择BN层的尺度因子作为裁剪channel的衡量指标。在训练时,对BN层的尺度因子添加 L 1 L_1 L1正则化,达到稀疏化的作用,这样就可以通过BN层的尺度因子趋于0来识别不重要的channel。
一般来说,额外的正则化很少会影响训练出来的模型的性能。
几种不同细粒度的裁剪方法的对比:
- weight-level的稀疏化裁剪,可以有较大的压缩率,但需要特定的硬件和库才能实现性能的提升(加速);
- layer-level的稀疏化裁剪,需要对完整的Layer进行裁剪,其灵活性较差。而且事实上,当网络足够深的时候(大于50层),移除layer才会带来收益;
- channel-level的稀疏化裁剪,是一个折中方案,其具有灵活性,可以适用于任何CNN中。
本文的思路是引入一个尺度因子 γ \gamma γ,对应每个channel,可以与每一个channel的输出相乘。然后联合训练权重和尺度因子,并对尺度因子稀疏正则化。最后prune掉较小的尺度因子及其对应的channel(权重)。训练的损失函数如下,其中加法第一项是正常的网络损失函数,后一项是尺度因子的正则化, γ \gamma γ是尺度因子, λ \lambda λ是惩罚稀疏。

本文中, g ( s ) = ∣ s ∣ g(s)=|s| g(s)=∣s∣,是常见的 L 1 L_1 L1正则化,也可用smooth L 1 L_1 L1代替。
BN层的计算过程如下所示,其中 μ B \mu_B μB和 σ B \sigma_B σB是激活值的均值和方差, γ \gamma γ和 β \beta β是可训练的仿射变换参数(scale和shift)。

本文选择直接使用BN层的 γ \gamma γ作为稀疏化裁剪的尺度因子。对于选择BN层的 γ \gamma γ作为尺度因子的分析如下:
- 如果CNN层之后没有BN层,添加Scale层,则Scale层和Conv层是线性变换。Scale缩小的值,可以在Conv层通过放大权重学习回来,所以是没有意义的;
- 如果Scale层在BN层之前,则会被BN层给归一化掉;
- 若在BN层之后,则每个channel都会有两个连续的Scale factor;
若有一些层是跨layer连接的,比如ResNet和DenseNet,则需要特殊处理,因为一层的输出可能是多个层的输入,不能直接裁剪。本文的处理为在每个block开始的时候添加一个channel select 层,以选择它想使用的channel 子集。即主干网络的channel数不变,只是在每个block里面选择其中的一部分用于计算。
论文实验
BN层的初始化为0.5,而不是其他论文所使用的的1,这是因为作者发现这样能得到更高的精度(但作者没有在ImageNet上实验)。对于VGG, L 1 L_1 L1正则化的惩罚稀疏 λ = 1 0 − 4 \lambda=10^{-4} λ=10−4;对于ResNet, λ = 1 0 − 5 \lambda=10^{-5} λ=10−5;对于DenseNet, λ = 1 0 − 5 \lambda=10^{-5} λ=10−5。
在裁剪的时候,需要决定阈值。文中的阈值通过所有尺度因子由一个百分比所对应的值来决定。
实验结果
在CIFAR和SVHN数据集上的实验结果如下:
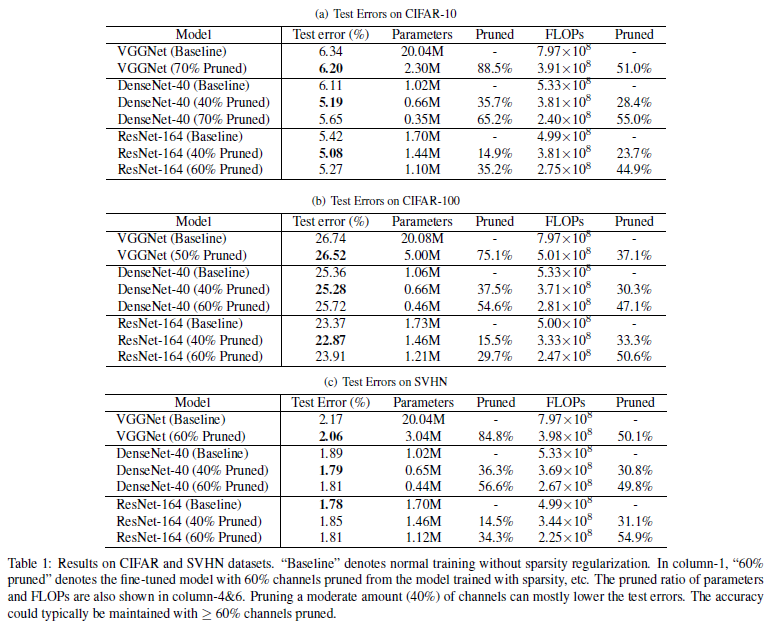
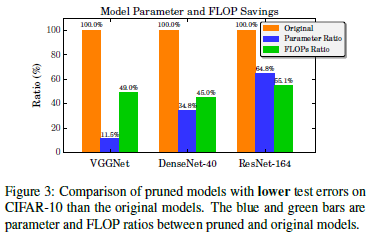
各个模型在CIFAR-10上的裁剪情况如下:对于ResNet104,参数压缩率和FLOPS压缩率都相对不明显。作者猜测是由于bottleneck结构和channel select层导致的。
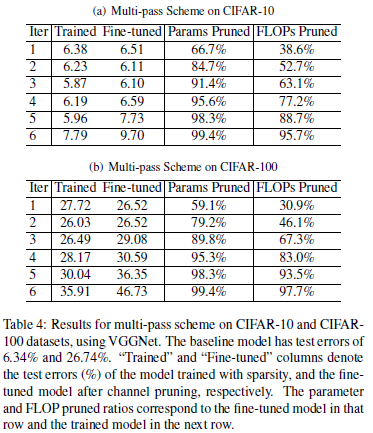
VGGNet在CIFAR-10和CIFAR-100的多阶段压缩方案(一次prune和finetune挽回损失为一个阶段):可以看出,在较小数据集CIFAR-10,直到第5次迭代才出现了较大损失;在较大数据集CIFAR-100,在第三次迭代就出现了较大损失。
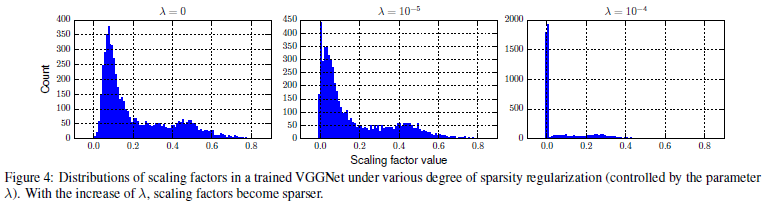
不同惩罚系数 λ \lambda λ所导致的尺度因子分布: