这是卡内基梅隆大学与新加坡南洋理工大学在AAAI上发表的一篇利用memory network来处理序列建模的文章。
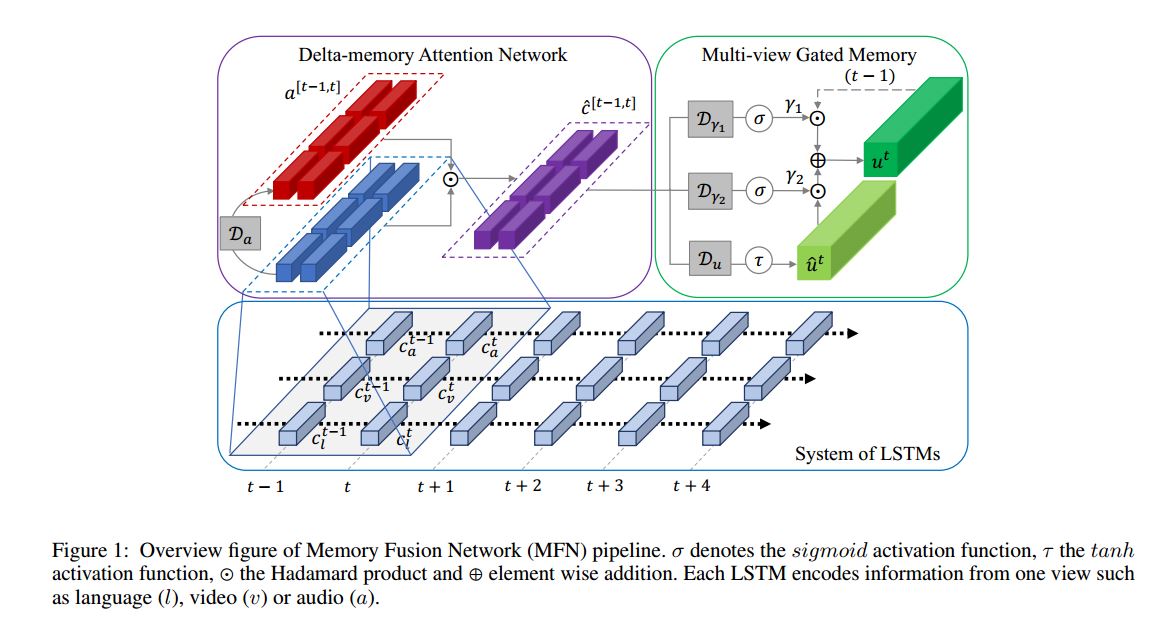
文章中的multi view其实指代可以很广泛,许多地方也叫做multi modal,对于多模态序列学习而言,模态往往存在两种形式的交互(1)模态内关联(view-specific interactions),(2)模态间关联(cross-view interactions),这篇文章提出了Memory Fusion Network(MFN)方法来处理这种多模态序列建模,处于对模态内与模态间的不同处理,本文可将方法划分为三个部分(1)LSTM对各自模态单独建模(2)Delta-memory Attention Network(DMAN)(3)Multi-view Gated Memory,后两者致力于处理模态间的交互。
Input:
比如对语言,视频,音频序列进行建模, ,the input data of the th view is denoted as: ,where is the input dimensionality of th view input .
System of LSTMs:
使用常规的LSTM, 对于每个输入 ,每一个step的memory表示为 ,每个step的output表示为 ,where denotes the dimensionality of th LSTM memory .
Delta-memory Attention Network
Delta顾名思义,考虑了LSTM前后两个step,输入到DMAN的是 与 的memory拼接,其中 , 通过上式来获得attention系数, 是对于时刻 与 的softmax score。
DMAN的输出定义如下
是分配权重之后的memories, 是element product.
Multi-view Gated Memory
(1)首先以上面的
为输入,生成update proposal
。
其中
。
(2)然后引入了两个gate,
:(retain gates)
(update gates),前者主要控制记忆当前状态的信息,后者主要用于控制前面所算update proposal
的更新。
其中 。
(3)所以updated 可以如下得到:
Output
The output of the MFN are the final state of the Multi-view Gated Memory
and the output of each of the
LSTMs.
representing idividual sequence information. denotes vector concatenation.
实验
主要是三个任务:Sentiment Analysis, Emotion Recognition, Speaker Traits Analysis
其数据类型是演讲者的视频,其中包含字幕,视频帧与音频,根据词的发声来划分文本,视频与音频,这样能够保证彼此的对齐,最后Language view特征:T*300, Visual view 特征 T*35, Acoustic view特征 T*74,本文在多个数据集上超越了state of the art 结果,并且进行自身ablation实验,分析其方法部件的有效性。
思考
与我以前常接触的跨模态不同的是,这儿等于是在时间维度上将多个模态(文本,图像,音频)非常严丝合缝地对齐(因为数据是根据同一段视频中,提取不同的view信息),因为LSTM天然的时间建模特性,作者所提出的Delta Memory Network就比较顺利成章地引入,但是如果是其它跨模态问题,比如Image caption, Cross-modal retrieval, visual question answering,不同模态之间虽然彼此联系,但是不存在时间维度上片段一一对齐,不知道这个框架是否能迁移过来,或者如何进行改造?
原始论文链接:Memory Fusion Network for Multi-view Sequential Learning
Github复现:MFN_keras
Github开源(作者目前还没公布源码):MFN