摘要&introduction
大多数现有的基于深度神经网络(DNN)的方法采用两阶段学习框架:第一个学习阶段是为每个模态生成单独的表示,第二个学习阶段是利用跨模态相关学习跨模态公共表示。
现有方法有三个局限性:
1)在第一个学习阶段,只建模了模态内相关性,忽略了模态间相关性。
2)在第二个学习阶段,他们只采用单一损失正则化的浅层网络,而忽略了模态内与模态间的内在联系,因此不能有效地利用并平衡它们以提高泛化性能。
3)仅考虑原始实例,忽略其patches提供的互补细粒度线索。
本文贡献:
1)跨模态相关性的利用:在第一个学习阶段,模态间相关可以为模态内部提供丰富的互补上下文,以便更好的学习单独表示。因此,我们采用多级联合优化,同时最大化模态内和模态间相关。这可以从跨模态相关中获取重要线索,从而促进共同表达的学习。
2)多任务学习:在第二个学习阶段,设计多任务学习策略,以自适应地平衡模态内语义类别约束和模态间成对相似性约束。并充分利用其内在相关性使它们相互促进。
3)多粒度融合:采用多粒度建模,融合粗粒度的实例和细粒度的patches,使跨模态相关性更精确。因为不同模态的patches之间的细粒度相关可以提供比原始实例更精确和互补的跨模态相关。
相关工作
Traditional Cross-modal Retrieval Methods:CCA,CFA ......
DNN-Based Cross-modal Retrieval Methods:
- 多模式深度信念网络(Multimodal DBN)(The Multimodal Deep Belief Network (Multimodal DBN) [13] is proposed to learn common representation for the data of different modalities. In the first learning stage for separate representation, it adopts a two-layer DBN for each modality to model the distribution of original features, where Gaussian Restricted Boltzmann Machine (RBM) is adopted for image instances, while Replicated Softmax model [31] is used for text instances. Then in the second learning stage, multimodal DBN applies a joint RBM on top of the two separate DBNs and combines them by modeling the joint distribution of data with different modalities to get common representation.)用于学习不同模态数据的共同表示。
- 双模自动编码器(双模AE)(The Bimodal Autoencoders (Bimodal AE) [15] proposed by Ngiam et al. is based on deep autoencoder network, which is actually an extension of RBM for modeling multiple modalities. It has two subnetworks to learn separate representation in the first learning stage, and then the two subnetworks are linked at the shared joint layer to generate common representation in the second learning stage. Bimodal AE reconstructs different modalities such as image and text jointly by minimizing the reconstruction error between the original feature and reconstructed representation. Bimodal AE can learn high-order correlation between multiple modalities and preserve the reconstruction information at the same time.)
- 对应自编码器(Correspondence Autoencoder,简称Corr-AE)(Correspondence Autoencoder (Corr-AE) [10] first adopts DBN to generate separate representation in the first learning stage. And then in the second learning stage, it jointly models the correlation and reconstruction information with two subnetworks linked at the code layer, which minimizes a combination of representation learning error within each modality and correlation learning error between different modalities. Corr-AE, which only reconstructs the input itself, has two similar structures for extension: Corr-Cross-AE and Corr-Full-AE. Corr-Cross-AE attempts to reconstruct the input from different modalities, while Corr-Full-AE can reconstruct both the input itself and the input of different modalities.)
- Cross-media Multiple Deep Networks (CMDN) (our previous conference paper [11]) jointly models the complementary intra-modality and inter-modality correlation between different modalities in the first learning stage. It should be noted that two independent networks are adopted in the first learning stage of CMDN. Specifically, Stacked Autoencoder (SAE) [32] is used to model intra-modality correlation, while the Multimodal DBN is used to capture inter-modality correlation. In the second learning stage, a hierarchical learning strategy is adopted to learn the cross-modal correlation with a two-level network, and common representation is learned by a stacked network based on Bimodal AE.
CCL APPROACH

fig3注释:CCL一共有两个学习阶段:
第一个学习阶段:同时建模模态内和模态间相关性来学习单独的表示,它们并行地整合原始实例及其patches
第二个学习阶段:采用多任务学习策略来自适应地平衡模态内和模态间相关性,从而得到更精确的共同表示。
如图3所示,CCL同时在两个学习阶段对模态内和模态间相关性进行建模,并采用粗粒度实例和细粒度patches,以学习更精确的模态间相关性。
第一个学习阶段:Multi-grained Fusion With Joint Optimization
构建一个多路径网络,旨在并行地从原始实例以及每个模态的patches中获得单独的表示,并通过联合优化捕获模态和模态间的相关性。
1)使用原始实例进行粗粒度学习:采用双路径网络结构对图像和文本实例进行建模。
首先,两种类型的深度信念网络(DBN)[37]用于模拟每种模态特征的分布,采用高斯受限玻尔兹曼机(RBM)[38]对图像实例进行建模。文本实例采用Replicated Softmax模型[31]。 定义每个DBN的概率函数如下:
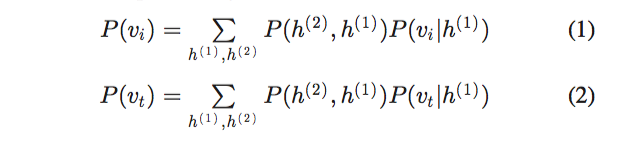
,
是DBN的两个隐层,
,
是图片文本输入,DBN的输出可以保留具有高级语义信息的每个模态的原始特征,其被表示为
,
。
然后,通过,
的联合优化同时建模模态内和模态间相关性,最小化下列损失函数,以共同优化重建学习误差和相关学习误差。(最小化的损失函数=图片输入和重建误差+文本输入和重建误差+图片和文本的距离)

,
:图片和文本重建的表达
(4)式中的:代表重建学习错误的损失,其目的在于最小化每种模态的输入和重建表示之间的L2距离。
(5)式中的:代表相关学习损失,最小化不同模态实例之间的L2距离。
因此,对于不同模态的原始实例,我们可以得到具有模态内和模态间相关性的粗粒度表示 。
2)使用patches进行细粒度学习:
首先将原始实例分成几个patches。采用选择性搜索提取候选区域,可以在图像实例中找到包含丰富细粒度信息的视觉对象。对于文本,根据其不同形式进行分割。
与原始实例类似,构建双路径网络结构,采用两种类型DBN提取图片文本patches的特征。对于一个实例的多个patches,平均融合其从DBN获得的特征,表示为,
。
然后,在代码层链接双路径网络,并最小化以下损失函数,以联合优化模态内和模态间相关性:
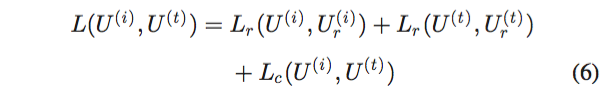
:重建学习损失
:关联学习损失
得到了具有模态内和模态间相关性的粗粒度表示 。
3)多粒度融合:
对于每个模态,采用联合RBM,融合从原始实例 和他们patches
获得的粗粒度和细粒度表示。
联合分布定义为:
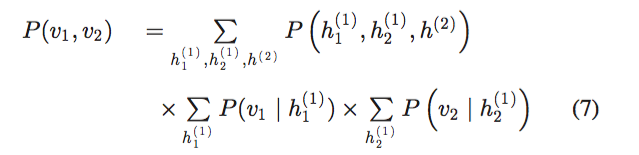
,
表示为
,
。该联合分布为图像的单独表示。
也可以用,
来生成文本的单独表示。
所获得的图像和文本的单独表示被表示为:,
。其包含每个模态原始实例、patches的内在联系和丰富的补充信息。
第二个学习阶段:多任务跨模态相关性学习
如图三右侧所示,为了生成公共表示,提出了一种多任务学习框架,用于将模态内语义类别约束和模态间成对相似性约束建模为两个损失分支。前者旨在提高高级公共空间中的语义判别能力,而后者可以捕捉不同模态之间的内在相关性,从而导致跨模态数据的更准确的共同表示。
对于模态间成对相似性约束,大多数现有的工作仅关注具有相似约束的成对相关,但忽略了语义上不相似的约束。因此,我们模拟不同模态之间具有对比损失的成对相似和不相似约束,其具有以下考虑:具有相同标签的图像和文本实例应该是相似的并且它们之间的距离应该最小化,相反地,图像和具有不同标签的文本实例应该是不同的,并且它们的距离应该最大化。 具体而言,小批数据构造邻接图G = (V, E),其中顶点V代表文本或图像实例,E是根据标签构造的两个模态数据之间的相似矩阵,定义如下:

因此,图像和文本对之间的对比损失被定义为对成对相似和不相似约束进行建模,如下:
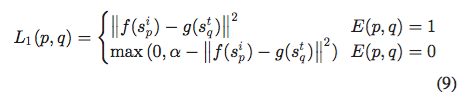
s是图片和文本的 separate representation(第一阶段学习 separate representations,第二阶段学习 common representations )
f(.)、g(.)表示在第二阶段多任务网络中的图像和文本路径的非线性映射。每个路径由三个全连接层组成,旨在将图片和文本的 separate representation 转变为最终的 common representation 。设margin=,对于正相关的图像文本对,计算(9)式
的导数:

对于不相关的图像文本对,计算的导数为:
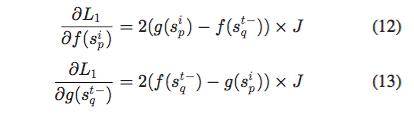
如果 ![]() 即max( ... )=0,则J=0,否则J=1。
即max( ... )=0,则J=0,否则J=1。
因此,可以应用反向传播来通过网络更新参数。
对于模态内语义类别约束,采用分类过程来利用每个模态内的内在语义信息,其可以将每个模态的数据分类为n个类别中的一个。 因此,我们将模态内语义类别约束呈现为n路softmax层,其中n是类别的数量。 交叉熵损失最小化如下:

:目标概率分布。
:预测概率分布
通过最小化上述损失函数,可以大大增强共同表示的语义辨别能力。
最后,从多任务学习网络中最后一个全连接层的输出可以获得精确的共同表达:,
。可以自适应地平衡模态内语义类别约束和模态间成对相似性约束,并进一步使它们相互促进。
为了执行跨模态检索,首先根据输入的原始实例和patches,从上述网络结构中提取每个图像和文本的公共表示。然后可以应用传统的距离度量来测量不同形式的实例之间的相似性,例如余弦距离,
EXPERIMENTS
数据集:
Wikipedia dataset、NUS-WIDE dataset、NUS-WIDE-10K dataset、Pascal Sentence dataset、Flickr-30K dataset、MS-COCO dataset
patch分割:
对于图片:选择性搜索生成数千个候选,若候选重合度大于百分之70,去掉小的候选区域,最后自动选择十个最大的补丁,这些补丁拥有更高的概率包含 具有丰富细粒度信息的 视觉对象。
对于文本:不同数据集采用不同的文本分割方法,Wikipedia的文本是包含多个段落的文章,按段分,每个段落包含相关内容。对于Pascal Sentence, Flickr-30K and MS-COCO datasets,文本实例由五个句子组成,将每个句子视为patch。对于NUS-WIDE及其子集NUS-WIDE-10K,文本实例是独立的标签,而不是句子或段落。将标签按字母顺序排列,并将每个文本实例划分为4个patches以保证通用性。小于四个标签的文本实例,每个标签作为一个patch。
特征提取:
对于每个数据集,为原始实例和patches提取相同维度、相同类型的特征。
网络细节:
第一阶段:
四个两层DBN,分别建模原始实例和他们patches的文本、图像特征,图像DBN第一层是2048维,第二层是1024维,文本DBN两层都是1024维。两层DBN之后,同一个实例的patches被平均融合到一个向量。
对于原始实例上的模态内和模态间相关性建模,双路径网络具有三个层,在顶部代码层处链接1,024个维度以进行联合优化,这对于补丁是相同的。(the two-pathway network has three layers with 1,024 dimensions linked at the top code layer for joint optimization, which is the same for patches)
最后使用联合RBM,分别融合图片/文本的原始实例和他们的patches。联合RBM的输出维数为2,048。在联合RBM的顶部,使用三层前馈网络进行softmax的进一步优化,每层的维数为1,024。
上述网络是用deepnet实现的。
第二阶段:
采用多任务学习策略,网络是由Caffe实现的三层全连接网络。以Wikipedia为例,三个全连接层均为1024维。网络对于模态内和模态间学习任务采用不同的损失函数,但损失分支上的全连接层均为1024维。由于不同数据集输入的维数不同,DBN第一层的维数根据不同的输入维度进行调整,而其他参数,如每层的维数,则保持不变。