这一系统通过学习人类驾驶者的操纵方式来学习驾驶汽车。神经网络通过车上安装的摄像头收集路面情况,随后将图像和驾驶者动作的记录进行配对。研究者们记录了大量不同环境中的驾驶数据:有画线和没有画线的道路;乡间小路和高速公路;一天中不同光照条件下的同一段路,以及不同天气条件下的道路环境。
通过观察,神经网络通过训练在完全没有手动输入编程指令的情况下学会了如何驾驶 BB8。现在这个神经网络已经可以在未遇到过的新环境中成功地驾驶车辆了。
摘要
作为自动驾驶汽车软件堆栈的一部分,英伟达创造了全新神经网络的系统 PilotNet,它通过道路情况的图像调整方向盘的角度。PilotNet 通过人类驾驶者操作的数据和道路图像的配对进行训练。它通过观察人类的行为学习必要的知识。这一方式省去了工程师手动输入规则并预先考虑所有安全驾驶情况的过程。道路测试证明了 PilotNet 可以在多种不同的驾驶环境中让汽车安全驾驶,无论道路上是否有画线。
为了解释 PilotNet 是如何学习和作出决定的,我们开发了一种显示 PilotNet 在作出决策时关注图像中哪些区域的可视化工具。结果显示,PilotNet 的确学会了识别道路上的重要物体。
除了画线、道路边缘和其他车辆以外,PilotNet 还学会了工程师们难以进行预先编程的其他特性,如识别乡间小路的边缘,以及识别非典型类别的车辆。
1.Introduction
训练数据是来自数据采集车中的前置摄像机的图像,以及从人类驾驶员记录的时间同步转向角。 PilotNet的动机是消除手编编码规则的需要,而是创建一个通过观察学习的系统。 初步结果令人鼓舞,尽管在不需要人为干预的情况下,需要进行重大改进。 为了深入了解学习系统如何决定要做什么,因此能够进一步改进系统,并建立系统关注安全转向的基本线索的信任,我们开发了一种简单的方法来突出显示图像的那些部分 在确定转向角度方面最为突出。 我们把这些突出的图像部分称为显着对象。 描述我们显着性检测方法的详细报告可以在[3]中找到。
其他作者已经描述了几种发现显着的方法。 其中基于灵敏度的方法[4,5,6],基于去卷积的方法[7,8]或更复杂的方法,如层次相关传播(LRP)[9]。 我们相信我们的方法的简单性,它在我们的测试车的NVIDIA DRIVETM PX 2 AI汽车电脑上的快速执行,以及其几乎像素级别的分辨率,使其特别有利于我们的任务。
1.1 Training the PilotNet Self-Driving System
PilotNet训练数据包含从汽车前置摄像机的视频采集的单个图像,与相应的转向指令(1 / r)配对,其中r是车辆的转弯半径。 训练数据用额外的图像/转向命令对增强,模拟车辆处于不同偏心和偏离方向。 对于增强图像,目标转向命令被适当地调整到将引导车辆返回到车道中心的那个。
一旦网络被训练,它可以用于提供给定新图像的转向命令。
2 PilotNet Network Architecture
PilotNet架构如图1所示。该网络由9层组成,包括标准化层,5个卷积层和3个完全连接的层。输入图像被分割成YUV平面并传递到网络。网络的第一层执行图像归一化。标准化器是硬编码的,在学习过程中没有调整。
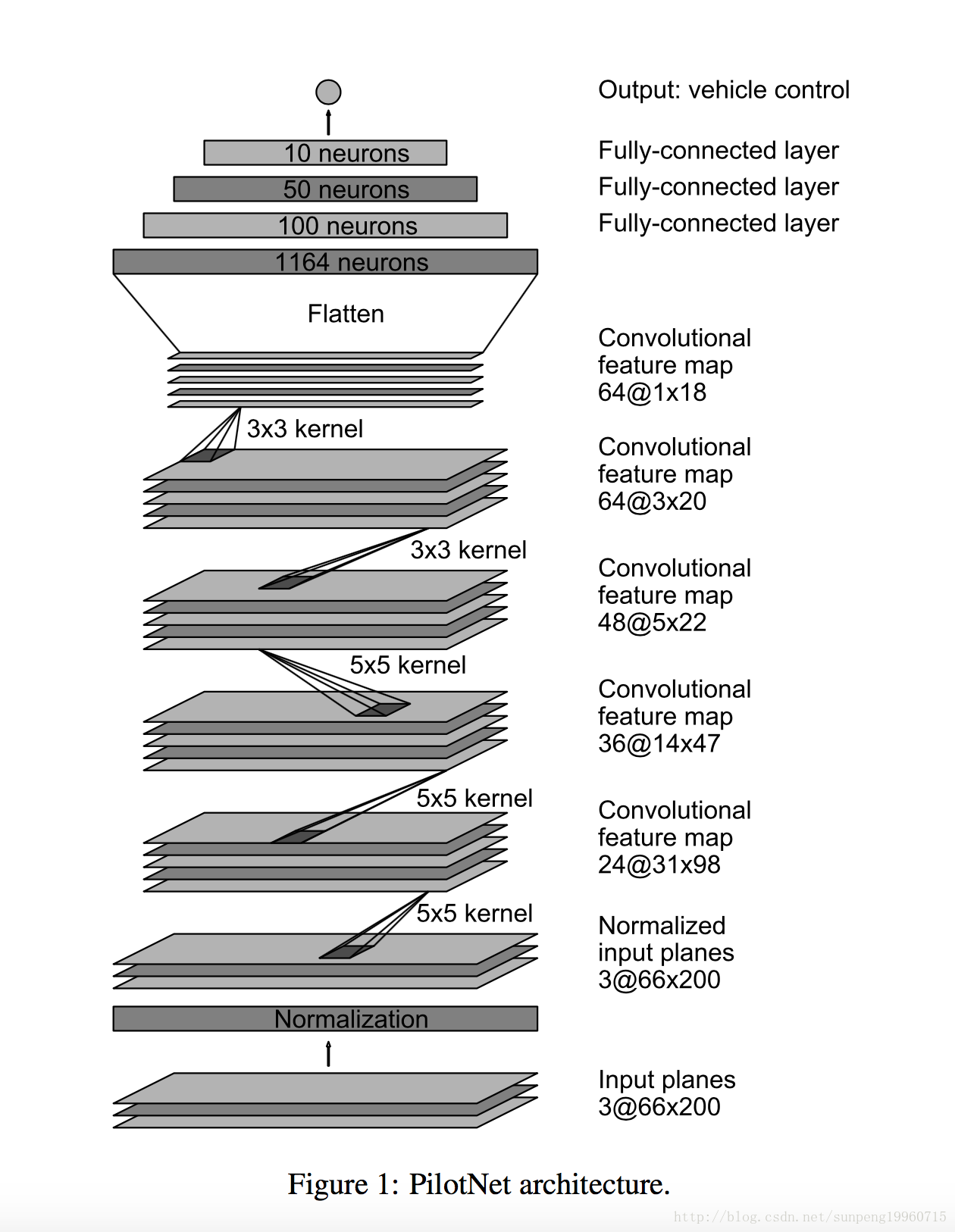
卷积层被设计成执行特征提取,并通过一系列不同层配置的实验经验选择。在最后两个卷积层中,具有2×2步长和5×5核的前三个卷积层和具有3×3核大小的非横向卷积的卷积卷积被采用。
五个卷积层之后是三个完全连接的层,导致作为反转半径的输出控制值。完全连接的层被设计为用作转向的控制器,但是注意到通过端对端的系统训练,网络的哪些部分之间没有硬边界主要作为特征提取器并且用作控制器。
3 Finding the Salient Objects
识别目标物体的中心思想是找到对应于上述功能映射具有最大激活的位置的图像部分。
使用以下算法,较高级别maps的激活成为下级激活的面具( become masks):
1.在每个层中,对特征图的激活进行平均。
2.最顶层平均的map缩放到和它下面的layer map一样的大小。up-scaling使用反卷积完成。用于反卷积的参数(卷积核大小和步长)与用于生成map的卷积层相同。反卷积的权重设置为1.0,偏差设置为0.0。
3.然后将来自较高level的高尺度平均map与来自下面的层的平均映射相乘(两者现在都是相同的大小)。结果是一个中间掩码( intermediate mask)。
4.按照步骤2所述的相同方式,将中间掩模放大到下面图层的大小。
5.再次乘以高层次的中间地图,从下一层的平均地图再次乘以(现在两者都是相同的大小)。因此获得了新的中间掩模。
重复上述步骤4和5,直到达到输入。将输入图像大小的最后一个掩码归一化到从0.0到1.0的范围,并成为最终的可视化掩码。
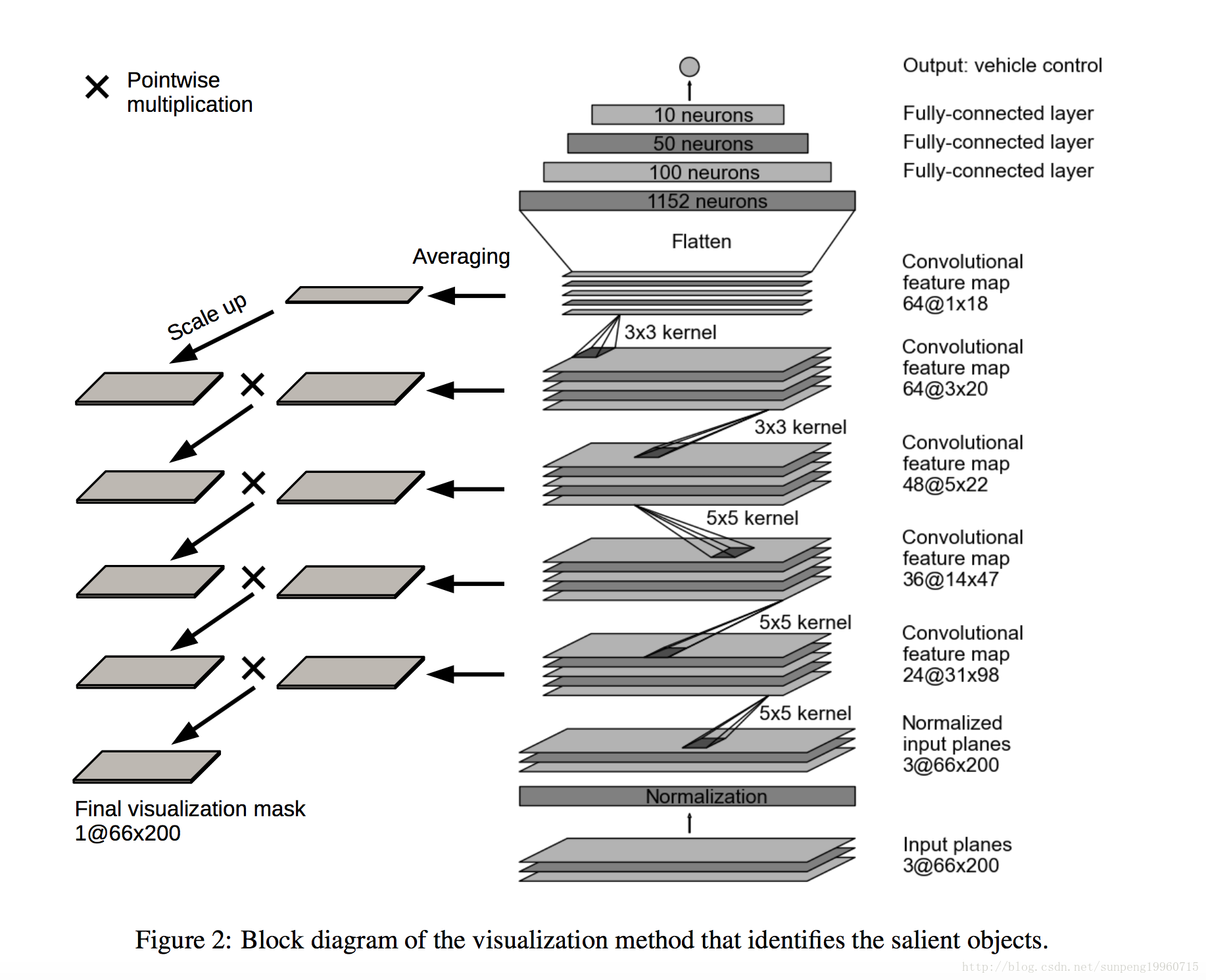
算法框图如图2所示。这些区域标识目标对象。
可视化掩模覆盖在输入图像上,以突出显示原始相机图像中的像素,以说明目标的对象。
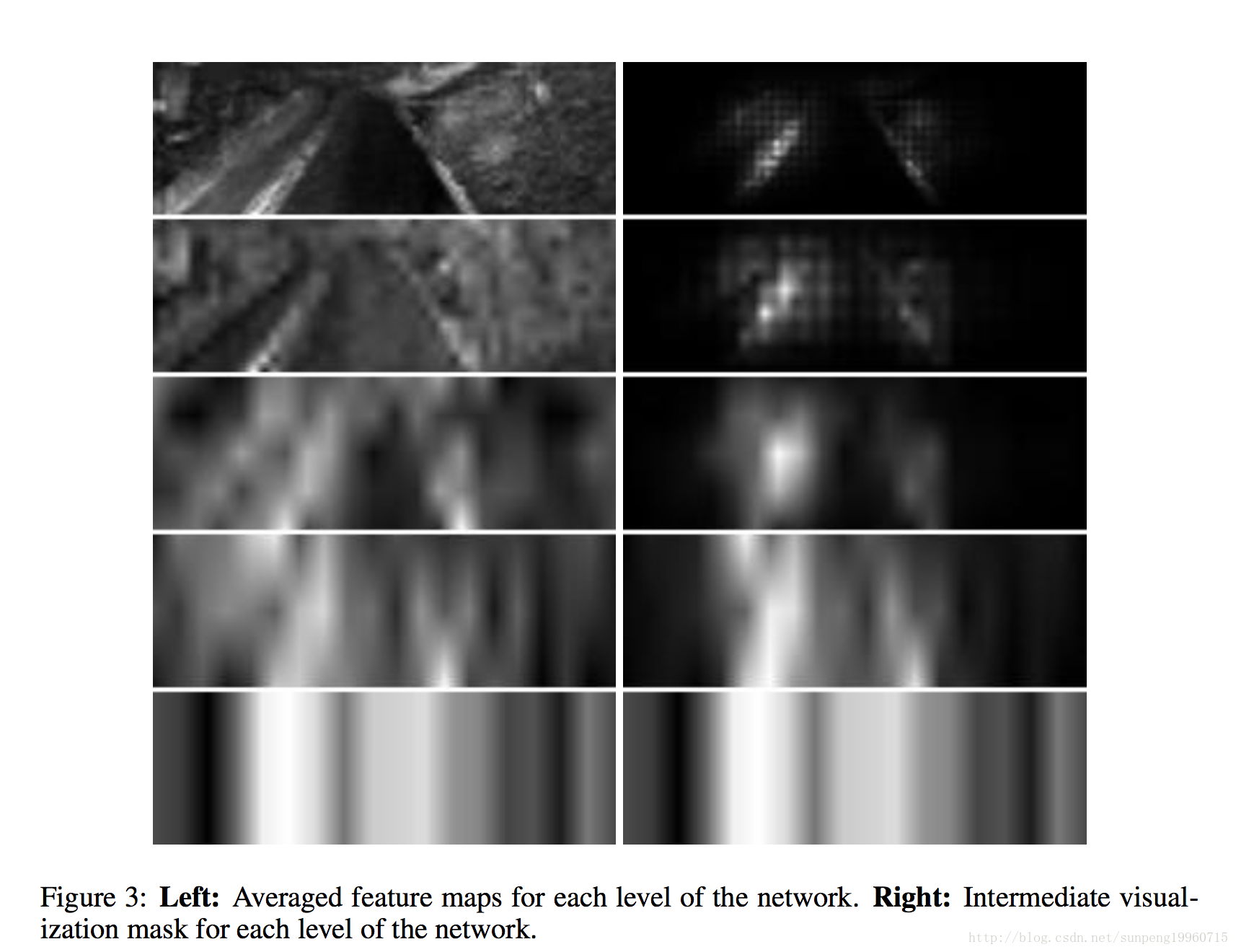
结果各种输入图像示于图4。
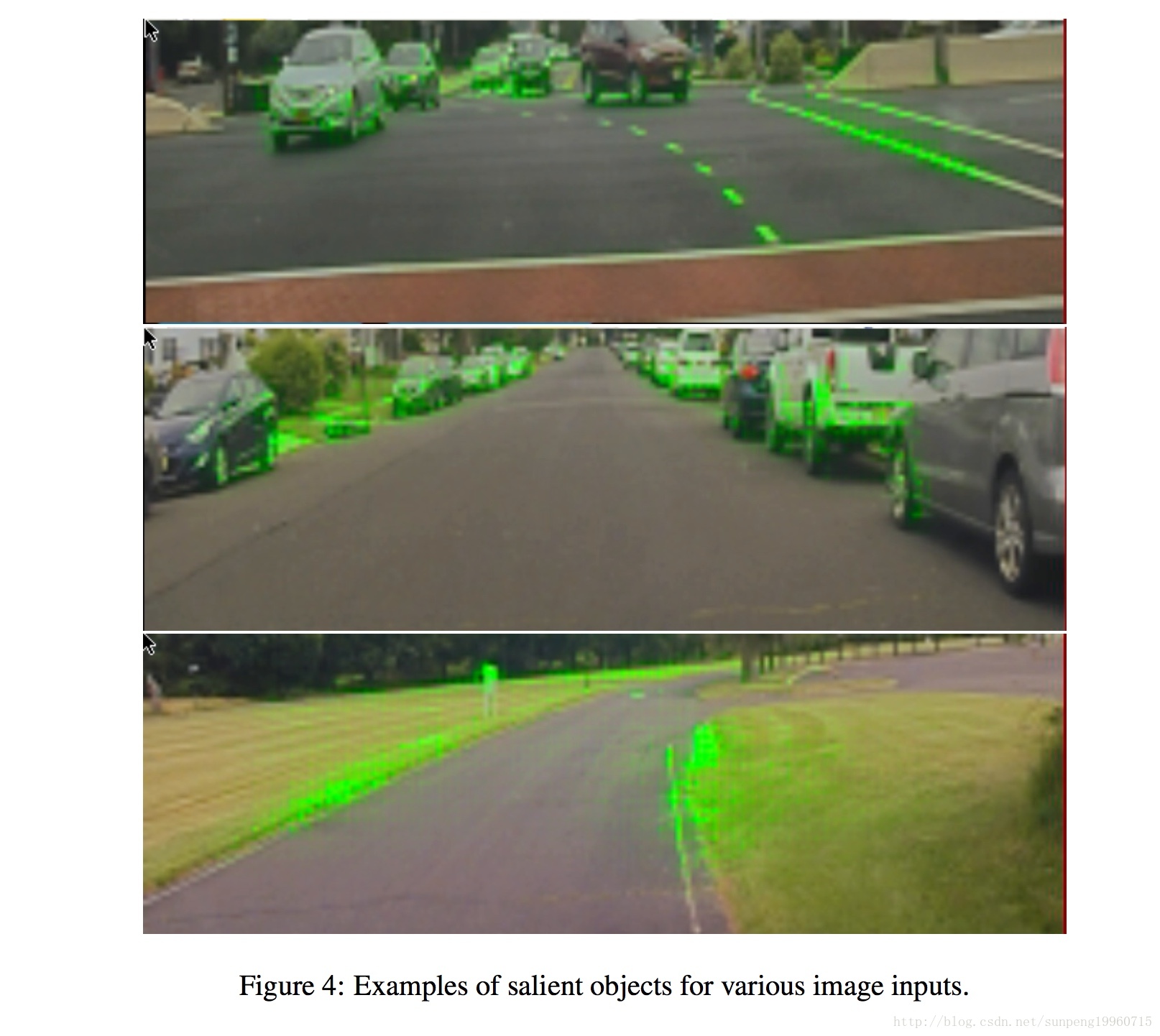
在顶部图像中注意到,汽车的基础以及指示车道的线条(虚线和实线)被突出显示,而人行横道的几乎水平的线被忽略。
在中间的图像上道路上没有画的车道,但停放的汽车,指出了道路的边缘,被高亮了。在下面的图像,道路边的草也被高亮了。没有任何编码,这些检测显示 PilotNet 展现了司机会使用这些视觉线索的方式。

图5展示了在测试车中内观,在图像的top,我们通过挡风玻璃看到实际的view,Pilotnet监控器在底部显示着诊断信息。
图6是一个放大的pilotnet监控。通过前置摄像头捕捉图像的顶部。绿色的矩形轮廓,是输入到神经网络摄像机图像的部分。下面的图像显示的显著目标区域。注意,pilotnet标识部分遮挡的施工车辆在路的右边是一个突出的对象。据我们所知,这样的车,尤其是在我们这里看到的姿态,不在pilotnet训练数据的一部分。

4 Analysis
虽然我们的方法发现显著对象显然似乎是那些应该影响转向的,我们进行了一系列的实验来验证这些对象实际控制了转向。
为了进行这些测试,我们分割呈现在两类输入图像到PilotNet。
1类是指包括所有具有由PilotNet输出转向角的显著效果的区域。这些区域包括对应于其中可视化掩模高于阈值的位置的所有像素。这些区域然后由30个像素扩张至抵消较高级别的特征图的层的跨度增加相对于所述输入图像。扩张的确切量是被凭经验确定的。
第二类包括在原始图像中的所有像素减去1.类的像素。如果发现通过我们的方法找到的物体确实控制输出转向角,我们希望下面的:
如果我们创建一张图像,一致地只转换class 1 中的像素,而保持class 2的像素位置,使用这个新图像作为PilotNet的输入,我们希望在转角输出一个显著的变化。然而,如果我们替代class 2的像素而保持那些class 1 的像素固定,然后feed PilotNet,我们期望输出变化不大。
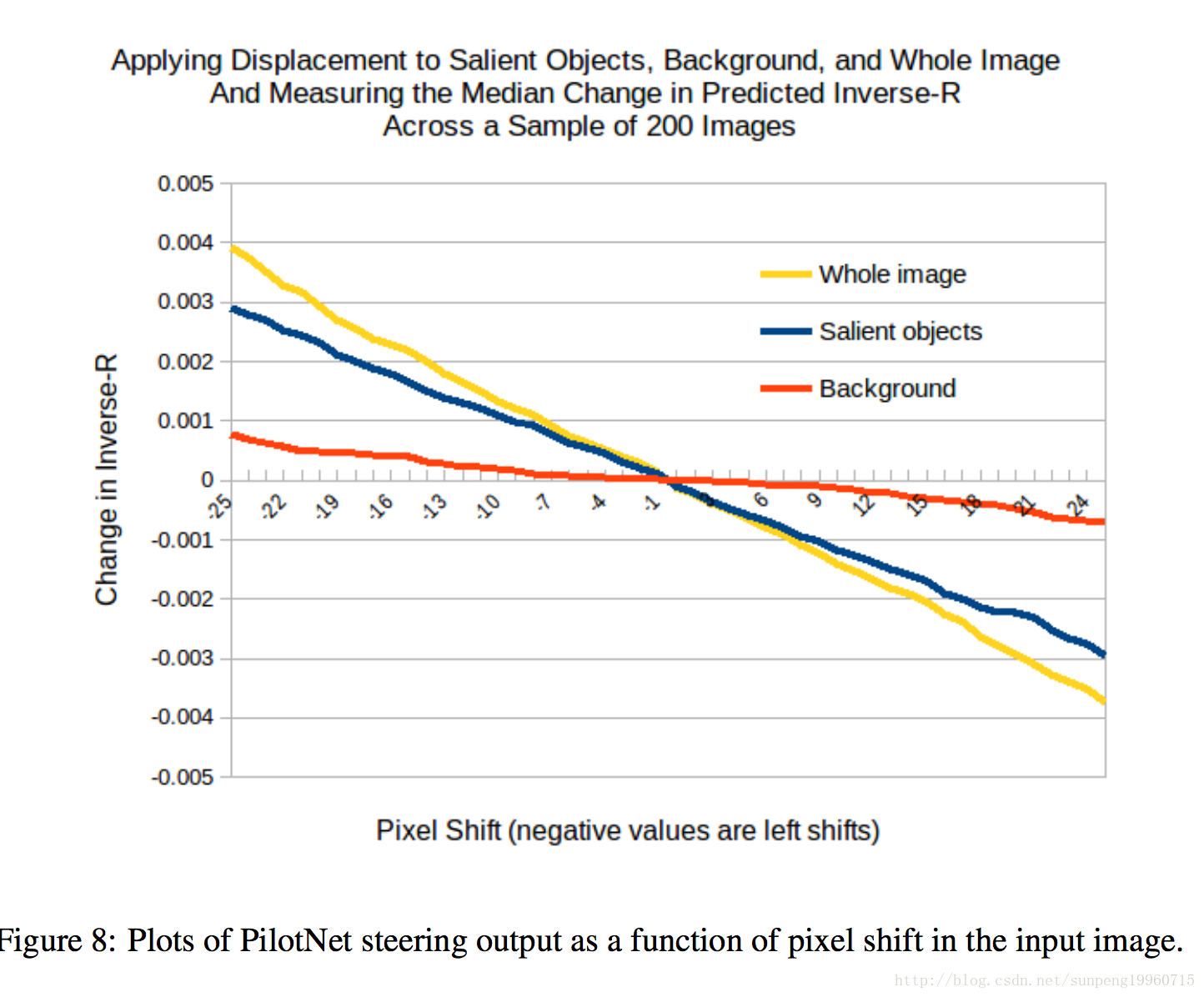
图7说明了上述过程。上图显示的场景的数据采集车拍摄。下面的图片显示了突出的区域,利用3节的方法确定。下面的图片显示了显著区域扩张。下图显示的是测试图像中的显著目标的转移扩张。

The above predictions are indeed born out by our experiments. Figure 8 shows plots of PilotNet steering output as a function of pixel shift in the input image. The blue line shows the results when we shift the pixels that include the salient objects (Class 1). The red line shows the results when we shift the pixels not included in the salient objects. The yellow line shows the result when we shift all the pixels in the input image.
Shifting the salient objects results in a linear change in steering angle that is nearly as large as that which occurs when we shift the entire image. Shifting just the background pixels has a much smaller effect on the steering angle. We are thus confident that our method does indeed find the most important regions in the image for determining steering(确定转向).
5 Conclusions
我们提出了一个方法用来找到在输入图像里决定转向的区域—the salient objects,进一步实验表明,提出的区域是正确的,结果有助于充分理解PilotNet学到了神马。
实验结果表明PilotNet学到的特征,“人的意义”,忽略那些对驾驶不相关的摄像头图像,这个能力是起源于不需要手制作的规则。事实上,PilotNet学会了识别精妙的特征,这很难由人类工程师来预测和编码,例如道路边缘的灌木丛和非典型的车辆类别。
正如图中所示,PilotNet 在驾驶汽车时关注的位置和人类驾驶者相同,包括路标、道路边缘和其他车辆。其中最令人兴奋的是:我们从未直接告诉神经网络需要注意到这些东西。计算机在训练过程中的行为和人类在驾校中所做的一样:通过观察学习。
「使用深度神经网络的好处在于:让汽车自己找到解决问题的方式,而如果我们不知道它们如何做出决策,我们就无法对系统作出进一步的改进,」Muller 解释道。「我们开发的可视化方式让寻找答案成为了可能。这也给了我们更大的信心,现在我们或许无法解释汽车的所有动作,但我们已经可以把它思考的过程显示出来了。」
当自动驾驶汽车真正得到广泛应用时,很多不同的人工智能神经网络和传统技术会共同工作,驱动汽车行驶。除控制方向盘的 PilotNet 之外,其他的神经网络也会经过训练处理其他特定的任务,如行人检测、车道识别、读取路标、防碰撞等等。