Unsupervised Person Re-identification via Softened Similarity Learning全文整理理解
Abstract
行为重识别(Re-ID)是计算机视觉研究的一个重要课题。本文研究了reid的无监督方向,该方向不能使用任何标记信息,可以自由部署到新的场景中。在这种方向下的研究很少,目前最好的方法之一是使用迭代聚类和分类,将未标记的图像聚类到伪类中进行分类器的训练,然后使用更新后的特征进行聚类等。该方法存在两个问题,即难以确定聚类的数量和聚类中的难量化损失。**在本文中遵循迭代训练机制,但放弃了聚类,因为它会导致硬量化的损失,但其唯一的产物图像级相似度,可以很容易地被两两计算和一个软化的分类任务所替代。有了这些改进方法变得更简洁,对超参数更改也更健壮。**在两个基于图像和基于视频的数据集上的实验证明了在无监督的reid设置下的最先进的性能。
Introduction
给定一个查询图像,重识别(Re-ID)的目标是在多个非重叠的相机上匹配该人。在过去的几年里,由于其广泛的应用,如寻找感兴趣的人和追踪人等,Re-ID越来越受到研究的关注。然而,大多数提出的方法是监督方式,这需要密集的手工标记,并不能适用于实际应用。为了缓解可伸缩性问题,在本文中关注无监督的reid任务。
与利用从其他Re-ID数据集学习的先验知识的无监督域自适应(UDA)方法不同,在本文中目的是在没有任何Re-ID注释的情况下解决该问题。其中的一个分支方法被验证是有效的,该方法采用了迭代聚类和深度学习机制,基于无监督聚类生成的伪标签对网络进行训练。然而,基于聚类的方法将图像粗略地分割成聚类进行训练,使得模型对聚类结果的依赖性很大。如图1 (b)所示,将同一个人的图像划分为不同的聚类,再对聚类进行训练,使用分配错误的伪标签进行分离。由于无监督聚类的错误是不可避免的,具有难量化损失的学习容易适应聚类产生的带噪标签。
本文提出了一种新的无监督学习框架,该框架不再需要聚类,从而减轻了难量化损失带来的误差。如图1 ©所示,不用显式标签,而是将未标记图像之间的关系挖掘为一个温和的约束,使相似的图像具有更紧密的表示。具体来说,我们的框架采用了一个带有软化标签的分类网络,软化标签反映了图像的相似度。与强迫图像属于一个确切类的原始单热点标签不同,我们将这些标签视为一个分布,鼓励将一个图像与几个相关的类关联。对于每一个训练数据,网络不仅被训练来预测基真类,而且被激励去预测相似的类。学习到的嵌入与相似的嵌入非常接近,与不相关的图像有很长的距离。一方面,没有硬标签的学习,硬量化的错误被消除。另一方面,软化标签的监管相对薄弱,这也为算法提供了更多的空间。为了充分发挥模型的潜力,引入了一些辅助信息来帮助寻找相似的图像。具体来说,在测量图像之间的相似性时,需要研究每个行人图像的摄像头ID和部分细节。为了解决相机差异的问题,提出了跨相机鼓励项(cross-camera encouragement term, CCE)来促进不同相机视图下图像的软化相似度学习。通过这种方式,模型将从更多样化的数据中学习。注意相机ID是在拍摄的瞬间自动获得的,不需要人为标记。此外,我们提取部分特征,并考虑局部细节和全局外观作为额外的线索。
我们在两个基于图像和两个基于视频的re-ID数据集上评估了提出的方法。实验结果表明,该方法在迭代过程中具有较好的鲁棒性和稳定性。比最先进的无监督方法在所有的四个数据集具有高精度和不需要任何注释的优点,我们的方法很容易部署到实际应用程序中。
我们的贡献可以概括为两方面。首先,我们提出了一种基于软化相似度学习的无监督reid框架。采用重新分配软标签分布的分类网络,对约束平滑的相似图像进行学习。通过将每个人的图像推向相似的图像,而将其他所有人的图像相互推开,我们的框架学习到一个强大的、具有高潜力的有区别的模型。其次,利用高势模型引入辅助信息来指导相似度估计。提出了一个跨相机鼓励(CCE)来鼓励不同相机视图图像之间的相似性探索。在度量相似度时也要考虑细粒度的细节。这些策略在插入其他非监督re-ID方法时也被证明是有效的。
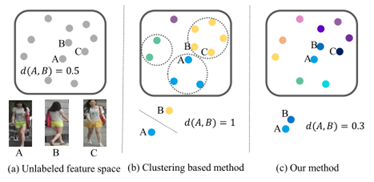
图1所示。(a)在特征空间中将未标记的图像表示为灰色圆圈。图像A和图像B是同一个人,初始距离为0.5。图像C来自另一个人。(b)基于聚类的无监督reid方法将图像大致分成类进行网络训练。虽然图像A和图像B是相同的,但是他们被分配了不同的伪标签,并学会了分开。©我们的方法使用软约束将相似颜色(相似图像)的圆圈推得更近。
Proposed Method
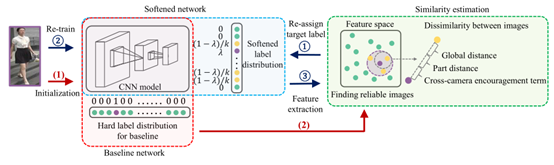
图2方法概述:首先,采用硬标签分布的基线网络进行初始化,如上红色箭头所示。然后用初始化的网络迭代进行三个过程:1. 提取训练图像的特征嵌入;2. 估计图像间的相似度,重新分配目标标签;3.用软化的标签对网络进行再训练。这些过程如下所示。值得注意的是,带有红色箭头的过程只执行一次,而带有蓝色箭头的过程是迭代执行的。
在本文中,主要研究无监督的re-ID问题。针对一组行人图像的训练集,我们的目标是通过探索图像之间的关系来学习人物图像的特征嵌入函数,而不是使用人工标注。然后在评价阶段,对于查询数据和图库数据,使用学习到的特征嵌入函数将每幅图像嵌入到特征空间中。查询结果是所有测试图像根据查询嵌入的特征与测试数据之间的欧氏距离进行排序的列表。
在无监督设置下,图像的标签是未知的,因此将每幅图像作为一个不同的类来初始化一个网络,逐渐挖掘未标记图像之间的相似度作为温和的监督。如图2所示,该框架结合了三个子组件(如图3个彩色矩形所示):(1)采用基线分类网络将每幅图像划分为不同的类别。基线用作生成特征表示的初始化;(2)基于特征嵌入和辅助信息,探索未标记图像之间的相似性,为每个训练数据选择可靠的图像;(3)根据可靠图像软化目标标签分布,并与软化后的标签对网络进行微调,将选择的可靠图像拉到一起,排斥其他图像。
Baseline: Initialization with Hard Labels
在无监督的行为重识别设置下,假设有一个训练集X = { x 1 x_1 x1, x 2 x_2 x2,…, x N x_N xN},其中每个 x i x_i xi是未标记的人物图像。目标是在不进行任何人工标注的情况下,从X学习到一个特征嵌入函数:由于没有每个图像 x i x_i xi的真实身份标签,所以首先通过它的索引为每个训练数据分配 x i x_i xi,即{ y i y_i yi= i | 1≤i≤N}。 y i y_i yi是数据 x i x_i xi的初始伪标签。这样每个训练图像都被假设为一个单独的类。
接下来采用非参数分类器的分类模型,其中使用一个查找表来存储所有训练图像的特征。然后将存储的各图像特征作为各类的权值向量。使用softmax准则来制定分类目标,对于每个图像x,通过 v = φ ( θ ; x ) ∣ ∣ φ ( θ ; x ) ∣ ∣ v =\frac{φ(θ;x)} {||φ(θ;x) | |} v=∣∣φ(θ;x)∣∣φ(θ;x)正则化它的特征 ∣ ∣ v ∣ ∣ = 1 | | v | |=1 ∣∣v∣∣=1。那么将一幅图像属于第i类的概率定义为:

其中,V∈ R N × n φ R^{N×n_φ} RN×nφ是存储各类特征的查找表, V j V_j Vj是V的第j列,表示第j类特征。N为类的个数,与训练图像的个数相同。 τ τ τ是一个温度参数,它控制概率分布在类上的柔软度,在之后设置了 τ τ τ= 0.1。
损失函数可以表示为:

其中t( y j y_j yj)是类别标签上的条件经验分布。作者将ground truth类的分布概率设为1,将所有其他类的分布概率设为0。Eq. 2的目标使每个图像特征 v i v_i vi和查找表 V j ≠ y i V_{j≠y_i} Vj=yi中的每个特征之间的余弦距离最大,同时使每个图像特征 v i v_i vi和对应的质心特征 V j = y i V_{j=y_i} Vj=yi的余弦距离最小。
Model Learning with Softened Similarity
初始化的基线网络学习识别每一幅未标记的图像,并获得初始的识别能力。通过Eq. 1,学习将每个训练样本与其他训练图像推开。但是在特征空间中存在相同的图像,应该是相近的。强迫同一个人的图像有明显不同的表现形式将对网络产生负面影响。受ECN的启发提出学习一种相似的图像表示,估计是相同的身份。
为了找到相同身份的图像,为每个训练样本选择相异程度最小的图像。对于两幅图像 x a x_a xa和 x b x_b xb,将两幅图像之间的不相似度定义为两幅图像之间的距离,即 D( x a x_a xa, x b x_b xb) = d( x a x_a xa, x b x_b xb),其中距离计算为两个图像特征之间的欧氏距离,即 d( x a x_a xa, x b x_b xb) = ∣ ∣ φ ( θ ; ||φ(θ; ∣∣φ(θ;x_a ) − φ ( θ ; ) − φ(θ; )−φ(θ;x_b ) ∣ ∣ )|| )∣∣,然后对于每一幅训练图像 x i x_i xi,选择差异最小的k幅图像作为可靠图像。定义一个可靠的图像集 X i r e l i a b l e X^{reliable}_i Xireliable = { x i 1 x^1_i xi1, x i 2 x^2_i xi2,…, x i k x^k_i xik}与标签 Y i r e l i a b l e Y^{reliable}_i Yireliable = { y i 1 y^1_i yi1, y i 2 y^2_i yi2,…, y i k y^k_i yik}。每个元素 x i j x^j_i xij被估计为与 x i x_i xi相同的身份,每个类 y i j y^j_i yij被视为可靠类。
提出了一种软化的分类网络,它可以更平滑地学习身份之间的相似性,而不是将可靠的图像作为同一类进行训练。在训练过程中,不仅能将每幅图像预测成ground truth类,而且能将训练图像预测成可靠的类。因此将一个非零值重新分配给目标标签中的可靠类。将数据 x i x_i xi的目标标签分布写成:

其中,λ是平衡ground truth类和reliable类的影响超参数。当真实值为1时,Eq. 3简化为基线网络中只有0,1选项的函数,即模型学会识别每一幅图像,但没有学会同一个人的图像之间的相似度和一致性。另一方面,当λ太小时,模型可能无法预测ground truth标签。
与基线网络相比,图像采用的是软标签分布(即概率),而不是硬标签0,1。这些标签不再是ground truth类,而是k个可能可靠类的概率。通过对可靠类的考虑,降低了ground truth类的置信度,增加了可信类的可信度,从而引导网络平滑地学习身份图像之间的相似性。通过Eq. 2和Eq. 3定义软化的交叉熵损失为:

提出的目标不仅使查找表中每个图像特征与ground truth特征之间的余弦距离最小,而且使每个图像的特征与其可靠图像之间的距离最小。同时最大化了图像中每个特征与其他类特征之间的余弦距离。
通过软化分类网络,逐渐学习到一个接近可靠图像的特征。可靠类的学习是柔和的,尽量避免可靠集中出现错误图像的负面影响。另一方面,相对弱的监督信号使模型更加自由,具有更高的潜力。这样就可以利用辅助信息来帮助学习更好的模型。在实验中验证了在有辅助信息的情况下,软学习模型比使用硬标签学习的模型表现更好。
Similarity Estimation with Auxiliary Information
如上节所示,对于每个训练样本,选择差异最小的k幅图像为可靠的。为了为约束引入额外的先验,还考虑了其他资源来帮助估计相似性。
部分相似的探索。为了辅助全局特征之间的相似性度量,建议同时考虑部分特征(细节)之间的相似性。通过CNN提取特征图并将其划分为p个横条。然后将每个分区特征平均合并为部分级特征嵌入。取对应部分的平均距离作为两幅图像之间的部分距离。将两幅图像 x a x_a xa和 x b x_b xb之间的部分距离表示为:

其中, φ i φ^i φi是第i部分特征嵌入函数。

图3。跨镜头鼓励的说明。在计算有无CCE时,所选择的可靠图像是不同的。CCE提倡寻找交叉摄像头 ground truth,而不是硬阴性样本。负样本图像用红色显示。
跨摄像头鼓励。提出了一个跨相机鼓励术语(CCE),它增加了不同相机捕捉到的图像的差异性,从而将其视为可靠的图像。添加CCE的直觉是双重的。首先,与内摄像头对相比,不同摄像头ID的图像对将教会网络学习跨摄像头信息。因此该模型预测了不同摄像头下的人的相似特征,这有利于Re-ID任务。第二有许多不同的行人穿着相似的衣服出现在同一个摄像头下。CCE帮助我们找到相互间的真实情况,而不是这些难以克服的消极因素。如图3所示,在没有CCE的情况下,虽然查询和camera 3捕获的图像属于同一个人,但是由于camera gap,两者的差异很大。即使是一个负样本(红色的那个)与查询的距离也较小,因为它们来自同一台相机。
具体来说,将训练样本的摄像机ID记为C = {
c 1 c_1 c1, c 2 c_2 c2,…, c N c_N cN}。两幅图像 x a x_a xa和 x b x_b xb之间的CCE表示为:

其中,“迁移”是控制交叉摄像头提升强度的参数。随着CCE项的增加,相同相机ID的图像之间的相似性增加。因此CCE有助于将更多的交叉相机图像纳入可靠的设置,并减少一些内部相机的负图像。
整体不同。考虑到部分相似度探索和跨镜头鼓励,则图像 x a x_a xa和 x b x_b xb之间的整体差异D( x a x_a xa, x b x_b xb)可表示为:

其中, λ p λ_p λp平衡度平衡了全局相似性和局部相似性的贡献。如图2的绿色分量所示,两幅图像之间的差异由全局距离、局部距离和跨相机鼓励项组成。通过计算全局距离和局部距离,测量全局外观和局部细节的相似度,保证了可靠图像选择的准确性。通过添加CCE项,来自不同摄像机的图像往往被选择为可靠的,这使得网络能够从不同的图像中学习。两者都有利于训练模型的识别能力。