版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_41427758/article/details/80643113
Motivation
- 巨大的姿势变化以及复杂的视角差异增加了从行人图片中提取特征与匹配的困难
Contribution
- 提出了Pose-driven Deep Convolutional(PDC) model来提高特征学习以及匹配
- pose driven feature weighting sub-network来学习自适应特征融合
思考
- 利用pose的关键点对身体分块并对不同块加权来增强细节特征来进行识别,越来越多的re-id方法更加注重局部细节特征的识别,18年CVPR出现了用human分割产生更精准的部分来进行特征提取,个人认为如何最大化利用可判别的细节特征是一个值得尝试的方法;文中运用了多种网络,结构相对复杂,对于如何借鉴已有方法的思想来解决re-id也很有启发
1.Introduction
- re-id定义:给定包含某个特定照相机下的特定人物的探测图像或视频序列,从其他照相机查询此人的图像,位置和时间戳。
- 传统方法:
- 从图片中提取局部不变特征
- 度量学习减少相同人特征图片之间的距离
- 深度学习:卷积提特征 + 欧式距离
- Softmax Loss学习全局表示
- 预先分的身体模块来学习局部特征,融合局部特征与全局特征
- 虽然相比传统方法有较大的提升,但是没有考虑身体姿势变化对人外观的影响
- 一些尝试:
- 通过预先的设定来进行简单分割
- 先利用pose estimation算法预测姿势,再训练Re-ID模型(非end-to-end)
- 本文的网络:
- Pose-driven Deep Convolutional(PDC)来同时学习全局(softmax loss)与局部特征(Feature Embedding subNet–>Pose Transformation Network),并通过Feature Weighting subNet(FWN)对不同部分加权融合局部与全局特征
- 局部表示产生如下图:original image –> 14个身体关节点的响应图 –> 14个关键点 –> 6个身体部分 –> 对各部分旋转 + 缩放 –> PTN归一化–> 送入网络学习表示

- 本文动机+贡献
2.Related Work
- 传统方法、Deep Learning、其他区分身体部分的尝试
- 本文方法:
- 更精确的姿势估计方法
- 考虑了姿势估计的精度、遮挡以及光线变化的影响
- 不同身体部分具有不同的判别力,对得到的身体区域进行了归一化处理再通过FEN得到更加鲁棒的特征,并通过FWN学习每个部分的权重
3.Pose-driven Deep ReID Model
3.1 Framework

- 人体姿势估计算法得到人体关节点位置
- 利用关节点位置来得到人体不同的部分
- 将身体部分通过FEN来变换得到归一化的身体区域
- 将整个图片以及身体区域图片一起送入CNN,前几层共享卷积特征,后几层有各自权重
- 最后通过FWN对身体部分特征进行加权来与全局特征融合后送入Softmax Loss
- 不同数据集尺寸的影响,可能不适合使用ImageNet Pretrained-model (224*224),本文基于GoogleNet设计了自己的网络,本文输入大小为(512 x 256), 结构如下表:
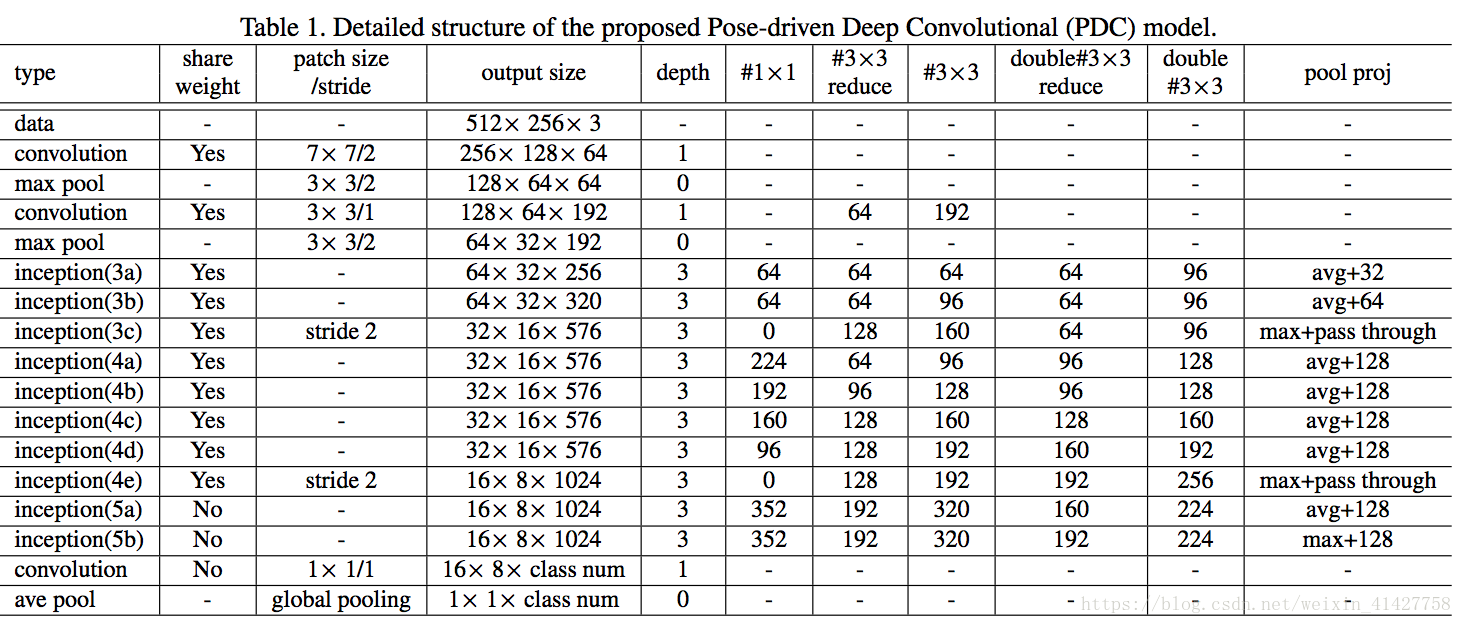
3.2.Feature Embedding sub-Net
定位关节点,产生身体区域:
- 通过姿态估计得到14个关键点
- 利用关节点将人体划分成6个区域:头、上体、两个胳膊、两个腿
- 关节点产生(不是很懂)
PTN:
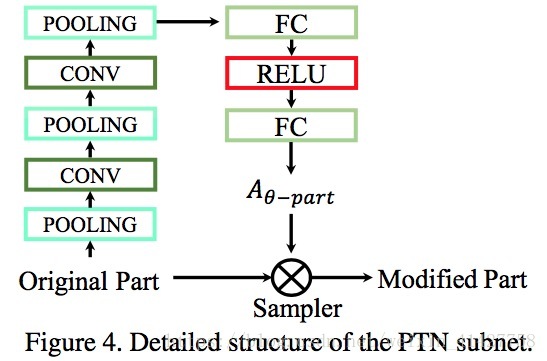
- 关键点定位存在不准确问题,通过STN来学习调整需要旋转的角度
- STN三个部分:
- localisation network:输入feature map,输出转换的参数
- parameterised sampling grid
- differentiable image sampling
- 本文使用affine transformation,6维转换参数:
- 不同身体部分由不同的位置与大小,设计了PTN对每个部分图片来进行转换,如下图
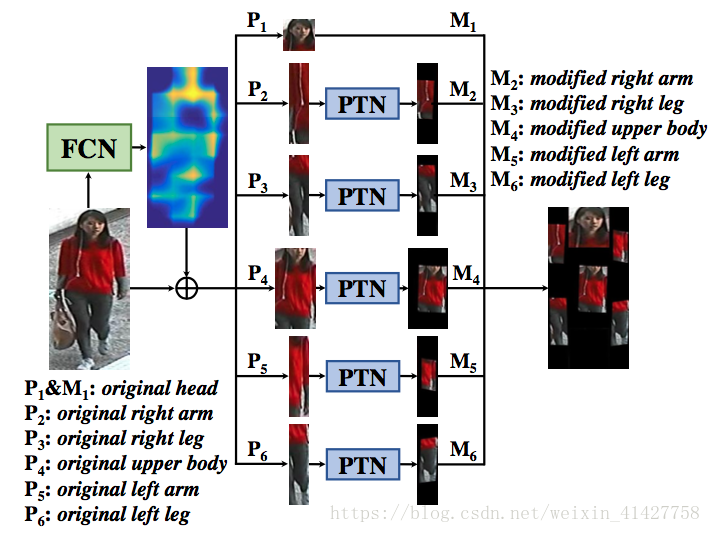
- 考虑到头部很少有较大的旋转,对头没有使用PTN
- 一共有5个独立的PTN,
- 身体部分
通过
得到校正过的身体部分
3.3.Feature Weighting sub-Net
- 产生的身体部分可能不准确,直接融合会产生噪声,如下图
- FWN:Weight Layer + a nonlinear transformation(防止线性过度对特定维度的身体部分向量响应):
- 为两个向量的Hadamard积(对应元素相乘)
FWN梯度计算公式如下:
扫描二维码关注公众号,回复: 3386905 查看本文章
其中 , 为 与 的维度

3.4.ReID Feature Extraction
- 全局特征与身体区域特征通过PDC提取得到1024维度向量,对身体区域特征向量进行加权,再与全局特征拼成2048维向量,该特征向量用来计算欧式距离得到不同图片之间的相似度
-

4.Experiment
4.1.Datasets
- CUHK03
- Market1501
- VIPeR
4.2.Implementation Details
- 评价指标:CMC、mAP(Market1501)
- caffe
- SGD、 batch size 16
- lr 0.01,每个20000个step降低一次,part localization network的学习率只有特征学习网络的0.1%
- 对于每个数据集,利用其训练数据训练了一个pretrained body-based model
- 对于整个网络的训练利用pretrained body-based model进行初始化
- GTX TITAN X GPU,Intel i7 GPU,128GB内存
- 输入大小512x256,减去每个通道上训练集上的均值
Evaluation of Individual Components
- 对本文方法的5个变体进行了评估来验证每个模块的有效性:
- Global Only:
- Global + Part:无FEN与FWN
- Global + Part + FEN
- Global + Part + FWN
- ALL
- 结果如下表:
- 融合全局与局部特征性能优于各自,使用FEN与FWN进一步提升了性能

4.4.Comparison with Related Works
- CUHK03、Market1501、VIPeR结果如下表




4.5.Evaluation of Feature Weighting subNet
- 不同加权层的性能比较:
,
为FWN带非线性变化加权层的数量,结果如下表:
- 下图为在FWN的特征


5.Conclusions
- 提出了PDC model来利用身体区域线索来学习高效的特征表示以及自适应相似性度量
- 对于特征表示:全局与局部特征都被转换为归一化与同源的状态来得到更好的特征嵌入
- 对于相似性度量:自适应加权融合
- 本文方法在三个数据集上超过了SOTA方法