1. 什么是DRN,为什么需要DRN
DRN的全称是Deep Residual Network,深度残差网络,是对普通的深度学习网络的一种改进。
我们为什么需要深度残差网络呢?因为普通的深度学习网络存在着这样的问题
在层数比较少的时候,我们增加网络的深度,可以获得更好的表达效果。但是当层数已经足够多,比如说超过了三十层,那这个时候我们增加深度,反而会降低识别率
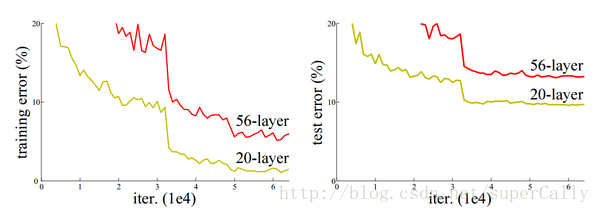
这是因为,当层数加深的时候,梯度在传播过程中会逐渐消失,导致无法对前面几层的权重进行调整。下面我们就来简单介绍一下梯度消失的问题
2. 梯度消失问题
我们知道,神经网络的优化都是通过梯度下降的方法来优化的。每次我正向计算的时候计算出Loss,然后我需要知道,究竟怎样调整参数矩阵才能使得我的Loss更小,预测和事实更接近,所以我们需要通过back propogation来对传播梯度,但是在传播的过程中,会出现一些我们没有预料到的问题。
2.1 Sigmoid当中的梯度消失
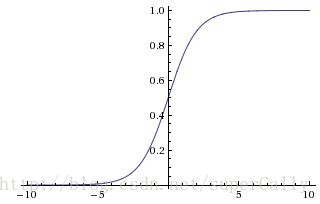
这是Sigmoid的函数图像,我们可以看到,Sigmoid函数把[-INF,INF]上的值映射到了[-1,1]之间。这个映射可以增加非线性性,但是有个问题,就是当输入值足够大或者足够小的时候,输出值基本上不变,这个时候函数的梯度值基本上为0。这就达不到梯度下降的功能了
2.2 用ReLU代替Sigmoid
为了解决这个问题,引入了新的非线性单元,ReLU。其实表达式也非常简单。我们可以看到,不管输入值多大,梯度值都是存在的,这就在一定程度上解决了梯度消失的问题,因而ReLU也比Sigmoid在性能上要更好
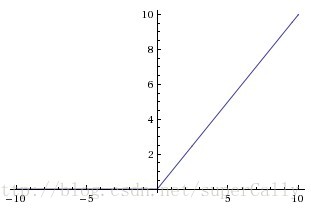
2.3 连乘导致的梯度消失问题
但是因为梯度连乘的问题,梯度消失的问题依然存在。我们通过正常的back propagation进行计算,
但是这个时候,如果网络很深很深,就会出现这样的情况
这个时候再做back propagation求偏导的话,就是
这个偏导就是我们求的gradient,这个值本来就很小,而且再计算的时候还要再乘stepsize,就更小了
所以通过这里可以看到,梯度在反向传播过程中的计算,如果N很大,那么梯度值传播到前几层的时候就会越来越小,也就是梯度消失的问题
3. DRN怎样解决了梯度消失问题?
所以这个时候,DRN就出现了,它在神经网络结构的层面解决了这个问题
它将基本的单元改成了这个样子
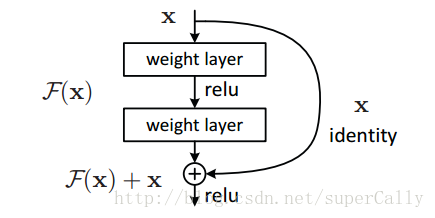
其实也很明显,通过求偏导我们就能看到
这样就算深度很深,梯度也不会消失了
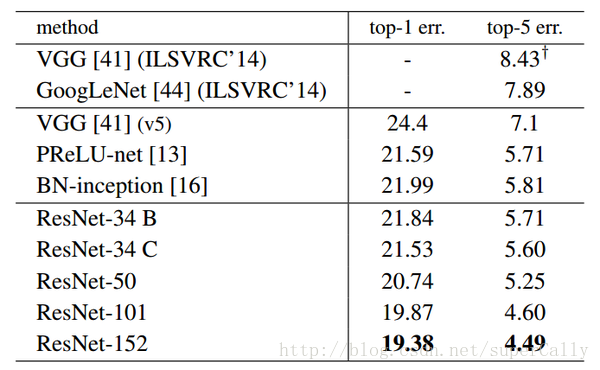
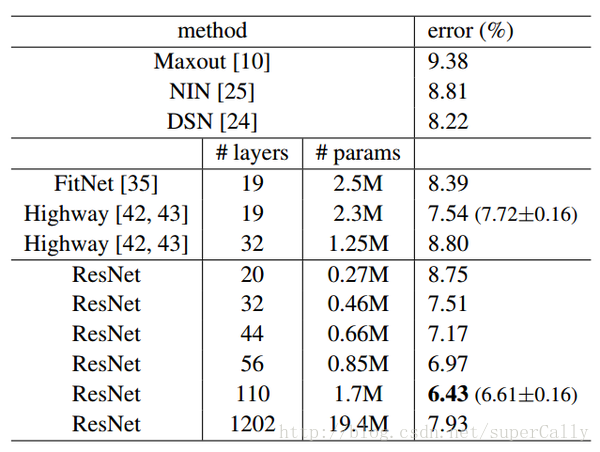
4. 效果详细说明
zhe yang