本文转自:http://jermmy.xyz/2017/09/25/2017-9-25-paper-notes-deep-residual-learning/,觉得作者写的很好,也注意到是作者自己开发的一个总结学习的一个web系统,怕作者关服务器后,想看再也看不到了的情况= = 所以厚着脸贴了过来。若有冒犯,立刻删除。
Deep Residual Learning
深度神经网络在训练过程中容易产生梯度消失,梯度爆炸的问题。在Batch Normalization中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域,在一定程度上能缓解这种问题。但是,当网络层数急剧增加,BP算法中导数累乘还是容易出现这种问题。而深度残差学习网络可以说是根治了这种问题。
为什么Deep Residual Learning能解决这种问题?BP过程建议亲自推导一下,很容易就发现,在求导过程中会出现一个随着层数增加而累乘导数的现象,我们尽可能控制每个导数的值,使它尽量接近1,这样累乘结果不会太小,也不会太大。
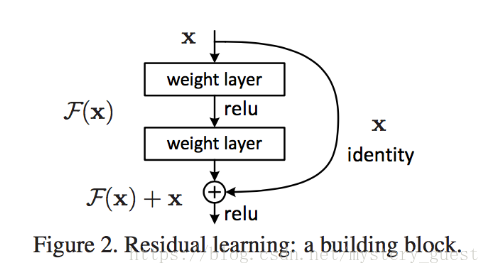
残差网络中的一个残差块(block):
简单的神经网络(将其假设为一条链):
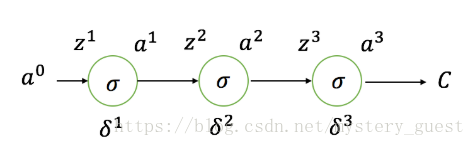




深度残差网络
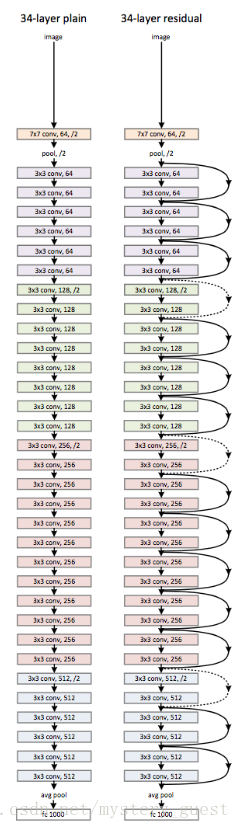
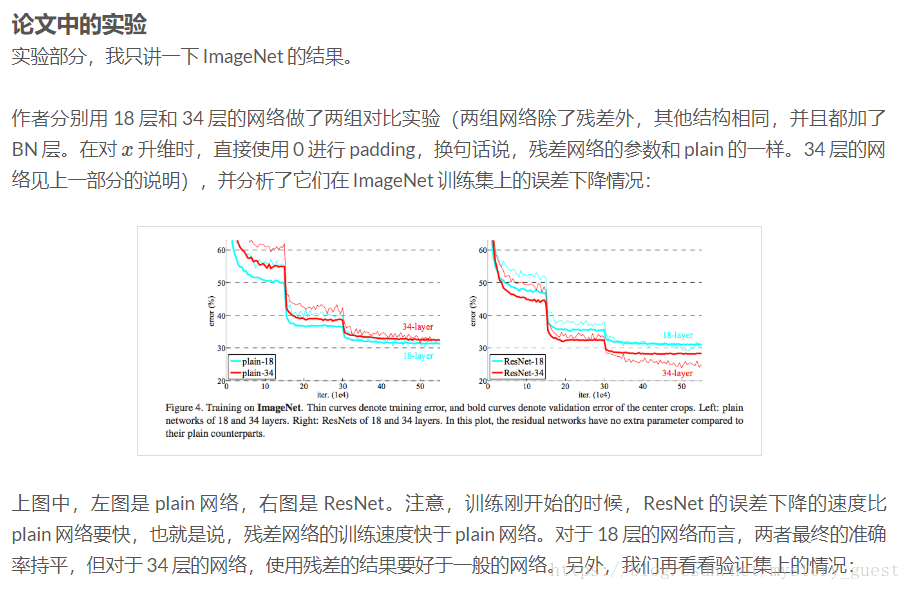
左图为plain network,表示这个网络很“平”,也就是普通的网络,右边是一个完整的深度残差网络。它其实就是由前文所说的小的网络结构组成的,虚线表示要对 xx 的维度进行扩增。作者在两个网络中都加了 Batch Normalization(具体加在卷积层之后,激活层之前),我想目的大概是要在之后的实验中凸显 residual learning 优于 BN 的效果吧。
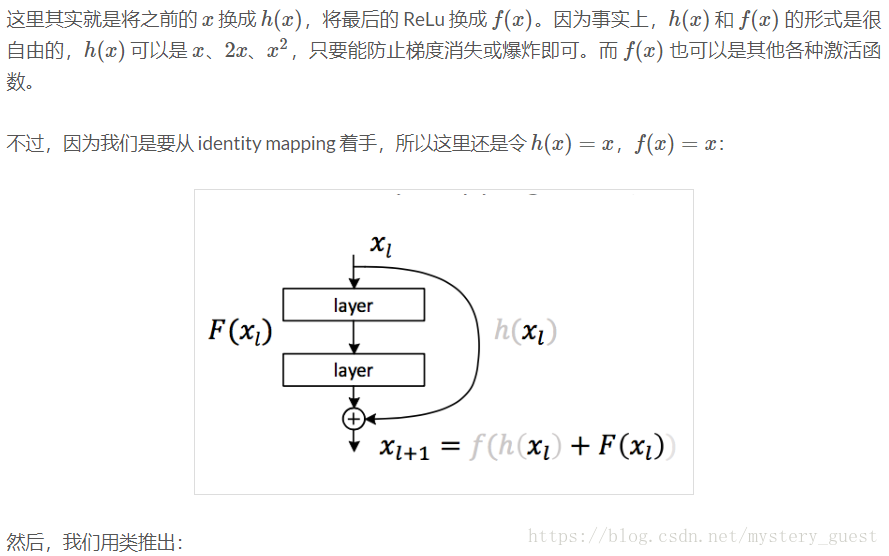
下面分析一下 identity mapping 对残差网络所起的作用,通过这个最简单的映射来了解 residual learning 不同于一般网络的地方。
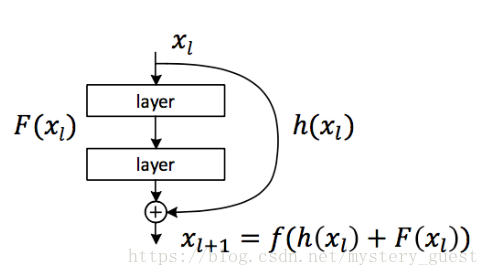
首先,给出最通用的网络结构: