v 为了利用丰富的光谱带,传统的逐像素HSI分类模型主要集中在两个步骤:特征工程和分类器训练。特征工程方法包括特征选择(波段选择)和特征提取[7]。特征工程的主要目标是降低HSI像素的高维度并提取最具辨别性的特征或波段。接下来,使用从特征工程步骤获得的判别特征对通用分类器进行训练。特征提取方法通常通过非线性变换学习代表特征。
v 例如,[8]综合了不同类型的降维方法得到的多个特征来训练支持向量机(SVM)分类器。与特征提取不同的是,特征选择方法试图从原始的HSI中找到最具代表性的特征,而不改变它们以保持其物理意义。例如,[9]采用流形排序作为无监督特征选择方法,选择最有代表性的频带来训练后续的分类器。此外,基于多任务联合稀疏表示的方法[10]综合波段选择方法与马尔可夫随机场施加的平滑先验。这两个基于波段选择的范例使用来自所有可用像素的光谱带进行特征选择,并且可以被解释为半监督学习方法。
v 另一方面,将HSI分类的空间信息纳入空间化输入和后处理有两种方法。空间化输入方法对从HSI获得的三维立方体进行特征工程步骤。许多论文认为,扩展输入数据的方法可以提高分类性能[11-12]。
v 在这些方法中,支持向量机是HSI分类中最常用的分类器,因为支持向量机利用高维输入数据来强有力地执行[13],[14]。例如,[15]采用了一个基于区域的核心提取光谱空间特征,学习SVM分类器识别高光谱像素的类别。相比之下,后处理方法已经考虑到光滑性的先验知识,具有相似光谱信息的相邻像素可能属于相同的陆地覆盖类别。例如,[16]引入了概率图模型作为后处理步骤来改善核SVM的分类结果。尽管许多作品使用典型的分类框架,它们是由特征提取器和可训练分类器组成的,但它们有两个缺点。首先,特征工程步骤通常不能很好地适用于其他情况。其次,在线性分类器之前应用事实上的一层非线性变换(例如,核方法)具有有限的表示能力以充分利用丰富的光谱和空间特征。
v 深度学习的基本理念是让训练好的模型本身决定哪些特征比其他特征更重要,而人类所施加的约束更少。多层神经网络可以提取HSI的鲁棒性和判别性特征,并且胜过支持向量机。然而,这两种模型都遭受了同样的空间信息丢失问题,这是由一维输入数据的需求所引起的。----引出---3D
v 残差网络可以看作是CNN中卷积层的延伸。而且解决了深度的梯度消失问题。
v 将残留学习与完全卷积层相结合,形成一个上下文CNN。然而,用一个相同的核,一起输入空谱信息,这种方法不能区分光谱特征和空间特征。因此,本文研究了两种残差结构对于HSI分类的光谱空间特征学习的有效性及其在不同场景下的鲁棒性。本文旨在研究SSRN对大小训练样本,高,中等空间分辨率的HSI数据集的泛化能力,以及不同类别的不均匀样本的各种地形类型的泛化能力。
v 1)设计的SSRN采用残差连接来缓解精度下降现象,提高HSI分类精度。
v 2)两个连续的残差块分别学习谱和空间表示,通过它们可以提取更多的判别特征。
v 3)本文验证了批量归一化(BN)作为一种正则化方法的有效性,以改善使用不平衡训练样本的分类结果。
v 4)统一的体系结构设计使得SSRN成为一个在三个常用的HSI数据集中得到广泛推广的框架。更重要的是,SSRN使用固定空间大小的有限训练数据实现了最先进的分类精度。
v 为了充分利用HSI所提供的光谱和空间信息,所提出的网络从原始数据中取出大小为w×w×b的立方体作为输入,BN [28]在SSRN中的每个卷积层进行。 这个策略使得深度学习模型的训练处理更有效率
v 通过反向传播(1)中的交叉熵目标函数的梯度来更新SSRN的参数
v 交叉熵公式
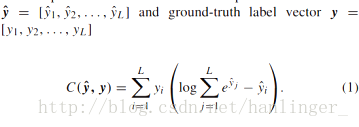
v 归一化,减少不平衡

Xk是(k +1)层的第i个输入特征张量,X k^为第k层批量特征块Xk的归一化结果,E(·)和Var(·)分别表示输入特征张量的期望和方差函数。H、b是(k + 1)层中的第i个卷积滤波器组的参数和偏差,*表示3-D卷积运算,并且R(·)是经整流的线性单元激活 函数将具有负数的元素设置为零。
v 频谱和空间残差块:这种现象源于CNNs的表示能力与相同正则化设置相对较少的训练样本相比太高的事实。残差块可以看作是两个卷积层的延伸。这种架构使得更高层次中的梯度快速传播回到较低层,从而促进和规范了模型训练过程。
v 在频谱残差块中,(谱残差块保留了丰富的特征(减少一半)并保持了空间尺寸不变)大小为1×1×m的卷积核分别在第pth和第(p + 1)层的连续滤波器组h(p + 1)和h(p + 2)中使用。 同时,通过填充策略,三维特征立方体X(p + 1)和X(p + 2)的空间尺寸保持在w×w不变,这意味着输出特征立方体将边界区域的值复制到填充在光谱维度上进行卷积运算后的面积( means that the output feature cubes copy the values from the border area to the padding area after convolutional operation in the spectral dimension.)。然后,这两个卷积层建立残差函数F(Xp;θ),而不是使用跳过连接直接映射Xp。 谱残差结构可以表述如下:
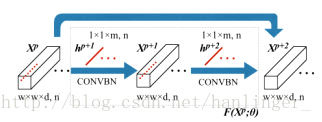
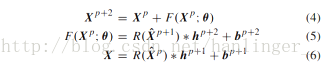
其中,theta= {h(p + 1),h(p + 2),b(p + 1),b(p + 2)},X(p + 1)表示第(p + 1)层的n个输入三维特征立方体,h(p + 1)和d( p + 1)分别表示第(p + 1)层中的谱卷积核和偏差。事实上,卷积核h(p + 1)和d(p + 1)是由一维向量组成的,这可以看作是三维卷积核的一个特例。谱残差块的输出张量也包括n个三维特征立方体。
v 在空间残差块中,如图4所示,重点主要放在使用连续滤波器组Hq + 1和Hq + 2中尺寸为a×a×d的n个3-D卷积核的空间特征提取上 两个连续的层次。这些核的光谱深度d等于输入三维特征立方体Xq的光谱深度.特征立方体Xq + 1和Xq + 2的空间尺寸在w×w处保持不变。因此,空间残差结构可以表述如下:
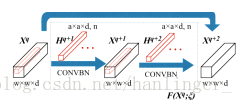
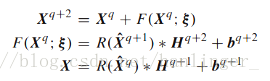
v 与CNN相比,SSRN通过在每个其他层之间添加跳跃连接来缓解降低精度现象,从而将层次特征表示层制定为连续残留块。我们以IN数据集为例,说明设计的SSRN的三维样本大小为7×7×200。谱特征学习部分包括两个卷积层和两个谱残差块。在第一卷积层中,采样子步长为(1,1,2)的24个1×1×7谱核卷积输入的HSI体积,生成24个7×7×97特征立方体。由于原始输入数据包含丰富和冗余的光谱信息,因此在这些块中使用1×1×7向量内核。该层减少了输入立方体的高维度,并提取了HSI的低级光谱特征。然后,两个连续的谱残差块,其中包含四个卷积层和两个身份映射,在每个卷积层使用24 1×1×7向量核来学习深度谱表示。在谱残差块中,所有卷积层都使用填充来保持输出特征立方体的大小与输入相同。在谱残差块的基础上,本学习部分的最后一个卷积层包含128个1×1×97谱核,用于保留判别性谱特征,对24个7×7特征张量进行卷积,产生一个7×7特征量作为输入空间特征学习部分。
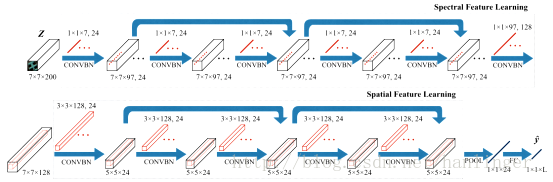
空间特征学习部分使用连续的3-D卷积滤波器组提取有区别的空间特征,其中内核具有与输入3-D特征量相同的深度。该部分包括三维卷积层和两个空间残差块。本节中的第一卷积层减少了输入特征块的空间尺寸,提取了24×3×128个空间核的低层空间特征,得到输出5×5×24特征张量。然后,这两个空间残差块类似于它们的谱对应,利用四个卷积层学习深度空间表示,所有这些都使用24个3×3×24的空间核,并保持特征立方体的大小不变。
v SSRN的可训练参数总数(约36万)远大于三个高光谱数据集中的可用训练数据,这意味着该网络具有足够的能力来学习HSI的特征表示,但也倾向于过度拟合训练集。因此,将BN和dropout作为正则化策略进行研究,以进一步提高SSRN的分类性能。
v 数据 印第安纳西北部收集的IN数据集包括16个植被类别,具有145×145像素,分辨率为20m×1像素。一旦丢失了20个吸收波段的波段,剩余的200个波段被用于分析,波长范围为400-2500nm。UP数据集包含9个城市地表覆盖类型,具有610×340像素,分辨率为1.3m。一旦噪声带被丢弃,其余的103个带被用于评估,范围从430到860nm。还有一个13种,512×614像素,分辨率为18m×1像素。一旦低信噪比的波段已经被去除,其余的176个波段被用于评估,范围从400到2500nm。
v 训练集很小,我们将批量设置为16,并采用RMSProp优化器[30]来利用训练过程。须知:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ,加衰减速率ρ

学习率(优化率和学习率有关)控制每个训练迭代的学习步骤。具体来说,不恰当的学习率设置会导致分歧或收敛缓慢。因此,我们使用网格搜索方法,对每个数据集运行200个历元的每个实验,从{0.01,0.003,0.001,0.0003,0.0001,0.00003}中找到最优学习率。根据分类结果,IN,KSC和UP数据集的最优学习率分别为0.0003,0.0001和0.0003。
v 卷积滤波器组的内核数决定了SSRN的表示能力和计算量。他这篇是找了一个通用的内核大小。每个卷积滤波器组中有24个核的模型在IN和UP数据集中分类精度最高,而在16个核中的模型在KSC数据集中获得最佳性能。这些结果是在三个数据集的每个设置200个代的训练过程中获得的。关于倾向过拟合,用BN比dropout好,而且相比CNN等BN在残差上效果更明显。分类结果都随着输入立方体的空间大小(图片大小,全文性)而增加。考虑到较大的输入大小会导致较高的分类精度,我们通过固定输入HSI数据的空间大小(这里代码应该会有)来对不同的分类方法进行公平的比较。
v 为了验证所提出的框架下光谱和空间残差块的有效性,我们还测试了仅包含光谱特征学习部分(SPC)和仅包含空间特征学习部分(SPA)的网络。SSRN的分类准确率都比三维CNN的分类准确率高,标准偏差小。
v SSRN中的频谱残差块需要比它们的空间对应物更大量的计算能力。 SSRN比CNN需要6-10倍的训练时间,这意味着SSRN比CNN在计算上更加昂贵。
v 神经网络的这种结构,讲谱与空间连在一起,而非分开先降维…,有连贯性,信息是一定程度是有关联的。会更加准确。