论文原文链接Deep Residual Learning for Image Recognition
摘要
越深的网络越难训练。我们提供了一个残差学习框架来简化网络训练过程,这个网络比之前所用的网络要深得多。该网络能够根据输入学习残差函数而不是原始函数。本文提供了全面的实例来表明这些残差网络更容易优化并且可以从更深的网络中获得更高的准确率。在ImageNet数据集上,我们用一个152层的网络来评估残差网络。该网络深度是VGG网络的8倍,但复杂度仍然比VGG网络要低。这些残差网络的组合模型在ImageNet数据集上达到了3.57%的误差,在2015年ILSVRC任务中取得第一名的成绩。我们也在CIFAR-10数据集上对100层和1000网络进行了分析。
网络表达的深度对于很多视觉识别任务上是至关重要的。仅仅由于非常深的网络表达,我们在COCO目标检测数据集上获得了28%的性能提升。深度残差网络是我们提交给ILSVRC&COCO竞赛的基础,我们在ImageNet检测、定位、COCO检测、分割任务上获得第一名的成绩。
动机
作者首先提出了一个问题:学习一个更好的网络是否和堆叠更多的层一样简单?并且提到了当网络较深时容易出现的梯度消失/爆炸问题。但归一初始化和中间归一化在很大程度上解决了这个问题。
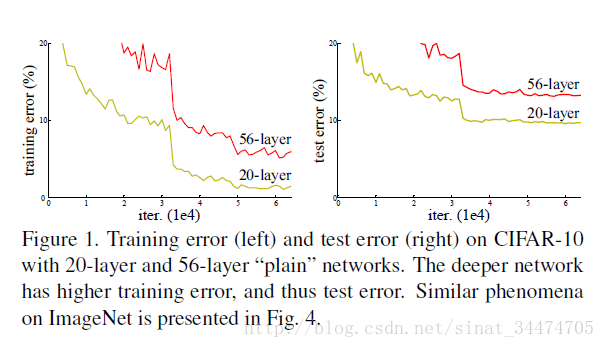
虽然题都消失/爆炸问题得到了很好的解决,但是作者又指出,当更深的网络开始收敛时,随着网络的不断加深,模型的准确率达到饱和随之迅速下降。文中将这个现象称为退化(degradating)(图1)。退化现象并不是由过拟合导致的,而是因为当网络很深时,模型变得越来越复杂,比相对较浅的网络更难优化。
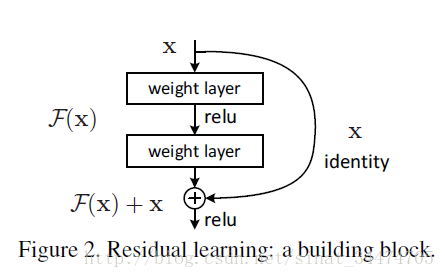
由此,作者引入了残差学习(图2),不再让网络中一部分堆叠的层直接去拟合
模型
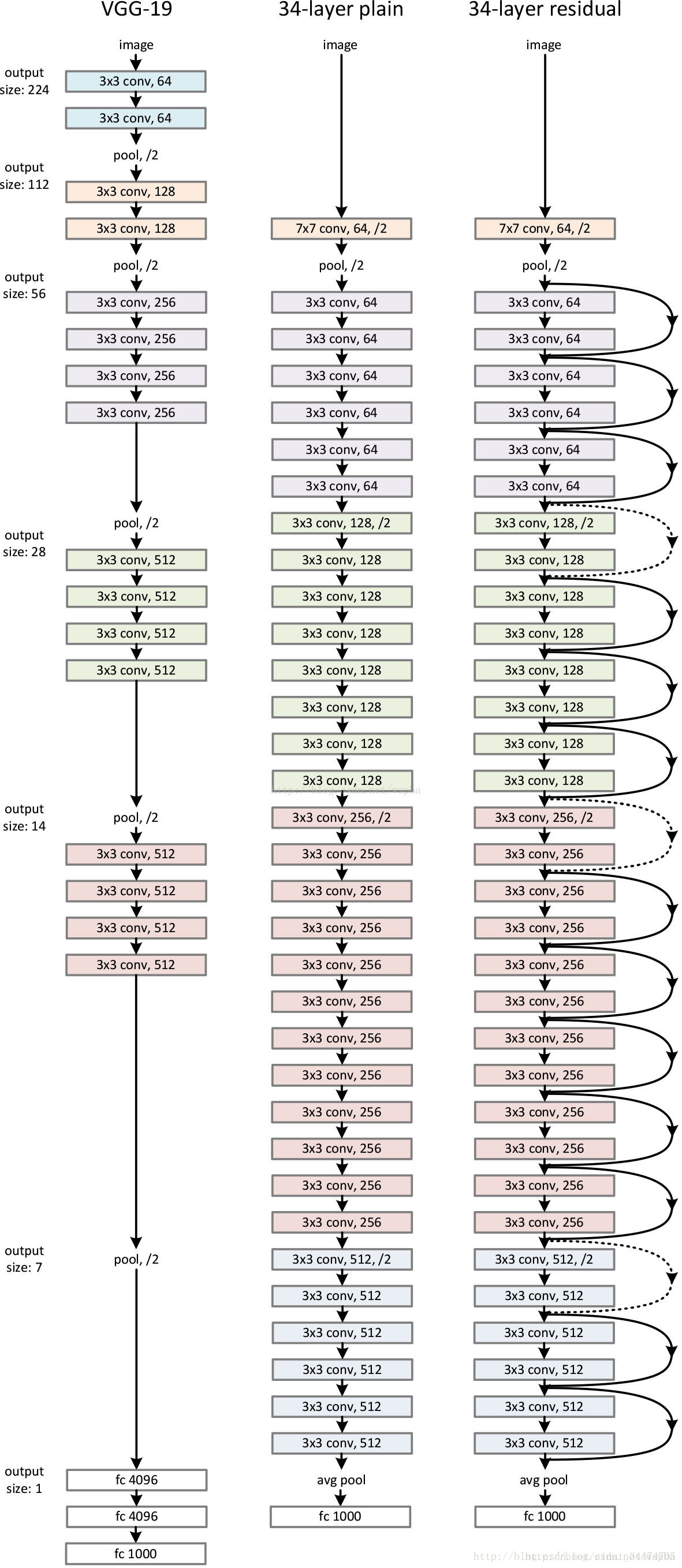
以34层残差网络为例,该网络由对应的34层平原网络(plain network)加入大量的shortcut构成,每一个shortcut相当于一个恒等变换。但需要注意的是,在维度发生变化的地方(即下图残差网络中的虚线shortcut),需要采取相应的维度变化方案,文中提到两种:
(1)shortcut仍然使用恒等映射,在增加的维度上使用0来填充,这样做的好处是不会增加额外的参数;
(2)通过1*1的卷积核使维度保持一致。
实验
ImageNet分类
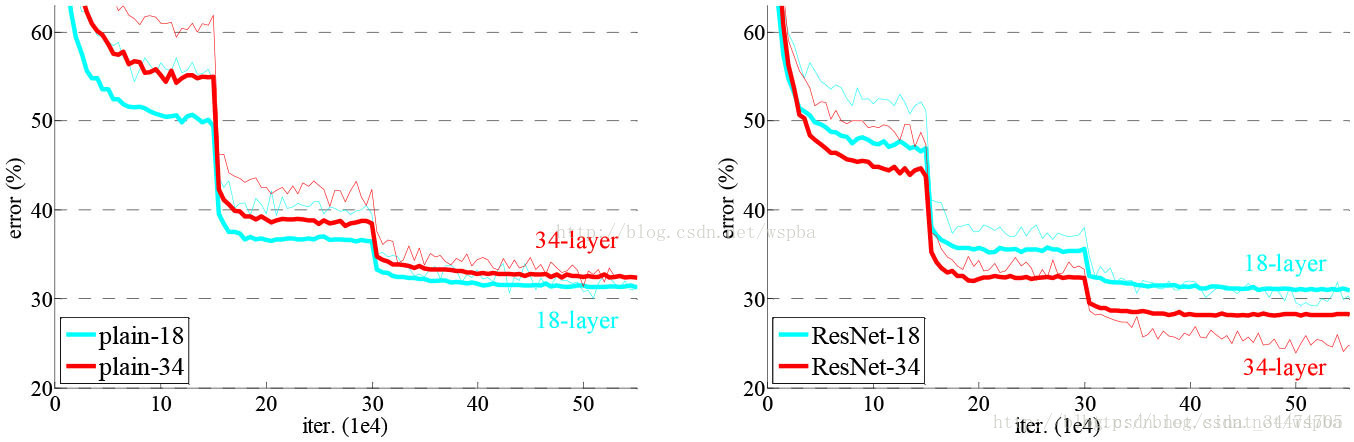
文中比较了不同深度下的平原网络和残差网络在ImageNet数据集上的分类结果。从下图中可以看出,对于平原网络,34层的训练误差和测试误差均比18层的要高,而对于残差网络,34层的网络的性能却比18层的性能好很多。而且相对于平原网络,残差网络有着更快的收敛速度。(PS:更详细的实验数据及分析请看论文原文,这里只做简单介绍)
Cifar10分类
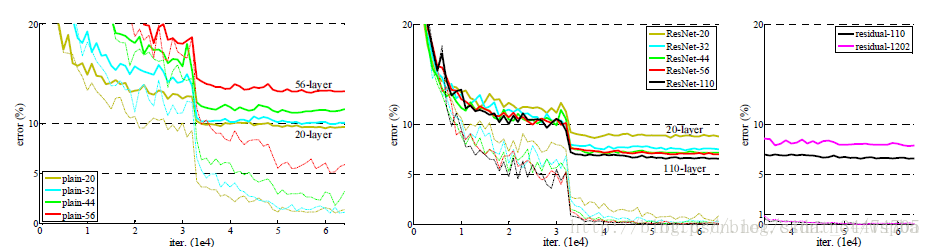
文中在cifar10数据集上对更深的网络做了类似的对比实验,并得到了一致的结论,不同的是,对于1202层和110层的残差网络,110层的结果更优于1202层,这是由于1202层的网络十分庞大,而cifar10数据集相对于ImgeNet数据集非常小,导致模型训练出现了过拟合。不过这个问题可以通过正则化的方法来解决。(PS:更详细的实验数据及分析请看论文原文,这里只做简单介绍)