何凯明大神2017年发表在CVPR上名为《残差变换聚合深度网络》的文章
ILSVRC 2016年分类工具的基础,并获得了第二名
论文链接:https://arxiv.org/abs/1611.05431
代码发布:http://github.com/facebookresearch/ResNeXt
PyTorch代码:https://github.com/miraclewkf/ResNeXt-PyTorch
测试数据集:ImageNet-1K,ImageNet-5K ,COCO(faster R-CNN目标检测),CIFAR
模型名称:ResNeXt(因为是基于ResNet改进的)
论文贡献:提出了深度神经网络中除 深度和宽度之外的另一维度 cardinality(基度)
物体分类经历了:手工设计特征(SIFT and HOG)->通过神经网络从大规模数据中获取
涉及神经网络结构比较复杂,因为有很多参数需要设置(width《指每一层通道的数目》,filter size,strides等等)
突破:
2015年提出的VGG网络 简化的网络参数的配置,通过堆积相同的模块。
ResNet继承了VGG堆积相同模块的策略,这么做好处是可以简化参数选择,防止过度调整参数。
Inception模型使用了split-transform-merge策略。通过过滤器降维,再通过串联器合并。准确率提高了,参数少了。
过滤器的数目和尺寸需要单独设计,并且每一次转化都不一样。
以下三种表示方法表示的cardinality作用是相同的:


思想来源:简单神经网络的思想

一个简单神经网络经历了:spliting-transforming-aggregating的过程,所以类比提出了network in neuron的想法

特别说明一下,虽然前面举得是三层的例子,这个模型不仅仅适用于>=3层卷积,也适用于2层的时,如下所示:

模型可用性分析:
下图左边参数为:256*64+3*3*64*64+64*256~70K
下图右边参数为:C(256*d+3*3*d*d+d*256)~70K C=32,d=4
基本具有相似的复杂度
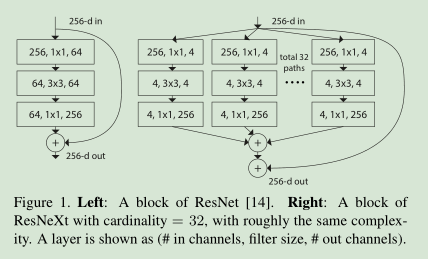
实施情况:
输入数据来自ImageNet的随机裁剪的长宽比增加的224x224的图片。保持一致
使用conv3,4,5 在stride-2,3x3的卷积核,SGD,mini-batch 256 在8GPU,权重递减为0.0001,momentum为0.9
使用figure3c里的结构运行
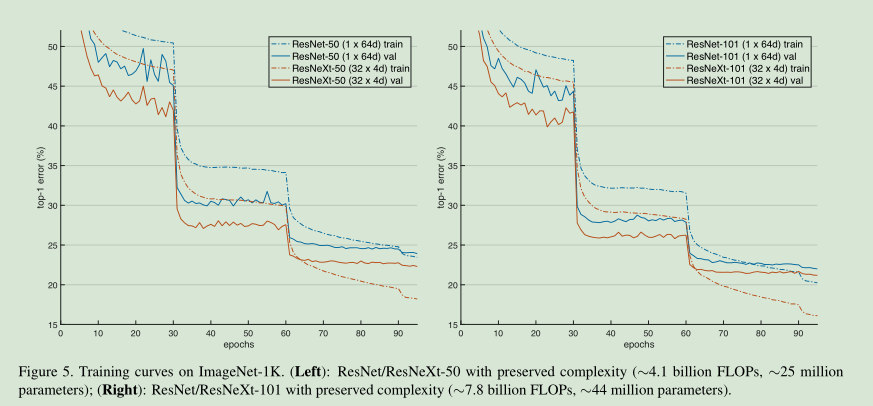
参照下图设置ResNet和ResNext的参数:

可以看到ResNet 和ResNext在保持参数数目一致的情况下,训练集和验证集的错误率下降更快。
改变d和c错误率的变化:

应用:
CIFAR
目标检测:Faster R-CNN