Deep Learning 基础 – 梯度爆炸与消失
Tags: Deep_Learning
本文主要包含如下内容:
梯度爆炸与消失
定义:在反向传播的算法过程中,由于我们使用了是矩阵求导的链式法则,有一大串连乘,如果连乘的数字在每层都是小于1的,则梯度越往前乘越小,导致梯度消失,而如果连乘的数字在每层都是大于1的,则梯度越往前乘越大,导致梯度爆炸。

为什么使用梯度更新
深度网络由许多非线性层堆叠而来,每一层非线性层都可以视为是一个非线性函数,因此整个深度网路可以视为一个复合的非线性多元函数.这个多元函数完成了输入和输出之间的映射,为了寻找合适的权值,我们定义loss函数,寻找最小值问题,使用最优化方法,采用SGD梯度下降方法.
梯度爆炸/消失的原因
梯度消失:网络深度/不合适的损失函数(激活函数)
梯度爆炸:网络深度/权值初始化值太大
深层网络角度:BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为
激活函数角度:如果激活函数选择不合适,比如使用sigmoid,梯度消失就会很明显了,如果使用sigmoid作为损失函数,其梯度是不可能超过0.25的,这样经过链式求导之后,很容易发生梯度消失.

解决方法
减小学习率/小心的权重初始化:根据链式法则即可.
预训练模型:无监督逐层训练方法,基本思想是每次训练一层隐层节点,训练时将上一层隐层节点的输出作为输入,而本层隐层节点的输出作为下一层隐层节点的输入,此过程就是逐层预训练,随后再对整个网络进行微调fine-tunning.该思想相当于先搜寻局部最优,然后整合起来寻找全局最优.
权重正则化:
激活函数:RELU(Rectified Linear Unit):relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。relu的主要贡献为:解决了梯度消失、爆炸的问题\计算方便,计算速度快\加速了网络的训练,缺点:由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)\输出不是以0为中心的.
批量归一化(BN:Batch Normalization):解决在训练过程中,中间层数据分布发生改变的问题,以防止梯度消失或爆炸、加快训练速度.
思想:通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。由于反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
BN层的作用:改善流经网络的梯度;允许更大的学习率,大幅提高训练速度;减少对初始化的强烈依赖;改善正则化策略:作为正则化的一种形式,轻微减少了对dropout的需求;
残差网络:
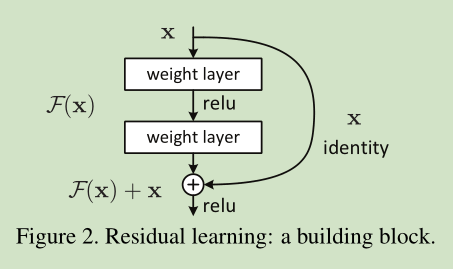
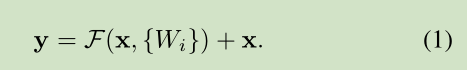
根据网络结构,我们可以写出反向传播公式:
由于梯度中1的存在有效防止了梯度消失.
LSTM 长短期记忆网络:主要原因在于LSTM内部复杂的“门”(gates),可以接下来更新的时候“记住”前几次训练的”残留记忆“