网页的排版效果不好,可以从以下链接下载pdf版本:
https://download.csdn.net/download/hyk_1996/10602389
Scalable Person Re-identification: A Benchmark
可拓展的行人重识别:一个基准
摘要
这篇论文贡献了一个新的用于行人重识别领域的高质量数据集,称为“Market-1501”.一般来说,目前的数据集有如下缺点:1)规模有限;2)由人工绘制的包围框组成,在现实条件下不可用;3)对于每个identity(封闭环境下),只有一个ground truth和一个query图像。为了处理这些问题,新提出的Market-1501数据集具有这三个方面的特征。首先,它包含了超过32000个标注的包围框,加上一个超过500K张图像的干扰集,使它成为目前为止最大的行人重识别数据集。其次,Market-1501数据集中的图像采用可变形部件模型(DPM)作为行人检测子的方法生成。最后,我们的数据集在一个开放系统中收集得到,因此每个identity在每个摄像头下有多张图像。
作为次要贡献,本文提出了一个无监督的Bag-of-Words描述子,它受到了最近大规模图像搜索领域的进展的启发。我们将行人重识别看作是图像搜索中的一个特殊任务。在实验中,我们展示了提出的描述子能够在VIPeR,CUHK-03和Market-1501数据集上取得有竞争力的准确率,并且在大规模的500k数据集上有拓展性。
1. 绪论
本文考虑了行人重识别任务。给定一张测试图像(query),我们的任务是去在一个gallery(数据库)搜索含有同一个人的图像。
我们的工作有两方面的动机。首先,大多数存在的行人重识别数据集[10,44,4,13,22,19]在数据集规模或数据丰富性方面存在缺陷。具体而言,identity的数量通常限制在几百个。这使得在大规模数据下测试算法的鲁棒性变得不可行。而且,同一个人的图像通常由两个摄像头获取;每个identity在每个摄像头下都有一张图像,所以query和相关图像的数目非常有限。此外,在大多数数据集中,行人通过手绘包围框能得到很好地配准。但在现实中,当使用行人检测子时,检测到的行人可能会经历错位或部分缺失(图1)。另一方面,行人检测子,在产生正确的正例包围框时,也会产生由复杂背景或遮挡(图1)引起的错误警报。这些干扰可能会对识别准确率造成不可忽视的影响。因此,目前的方法可能偏向于理想的设置,并且一旦理想数据集遇到实际情况,其效果可能会受到损害。为了解决这个问题,引入更接近实际设置的数据集非常重要。
其次,基于局部特征的方法[11,40,38,3]被证明是有效的行人重识别。考虑到“查询-搜索”模式,这可能与基于Bag-of-Words(BoW)模型的图像搜索兼容。尽管如此,一些最先进的行人重识别方法依赖于蛮力特征匹配[39,38]。尽管获得了良好的识别率,但这种方法的计算效率较低,这限制了其在大规模应用中的潜力。在BoW模型中,使用预训练码本将局部特征量化为视觉词汇。因此图像由TF-IDF方案加权的视觉词汇直方图表示。在BoW模型中,局部特征被聚合成一个全局矢量,而不是在图像之间进行详尽的视觉匹配[39]。
考虑到上述两个问题,本文作出了两点贡献。主要贡献是收集一个新的行人重识别数据集,名为“Market-1501”(图1)。它包含由6台摄像机收集的1,501个identities. 我们进一步添加了一个由500K张无关图像组成的干扰集。据我们所知,Market-1501是由32,668 + 500K个包围框和3,368个query图像组成的最大行人重识别数据集。它在三个方面与现有数据集有所区别:用DPM检测包围框,包含干扰图像,以及每个identity的multi-query、multi-ground truth. 这个数据集因此提供了更真实的基准。为了进行精度评估,我们建议使用均值平均精度(mAP),这是一种比常用的累积匹配特性(CMC)曲线更全面的测量方法[38,39,20]。

图1. Market-1501数据集的示例图像。所有图像标准化到128x64. (上:) 具有独特外观的三个行人的示例图像。(中:)我们展示了三个外观非常相似的行人的情况。(下:) 提供了一些干扰图像样本(左侧)以及无用图像(右侧).
作为一项次要贡献,受到最先进的图像搜索系统的启发,我们还提出了一种无监督的BoW表示法。 在生成训练数据的码本之后,将每个行人图像表示为视觉词汇直方图。在这一步中,整合了许多技术,例如根描述子[2],负证据[14],突发加权[16],avgIDF [41]等。此外,还采用了几个进一步的改进,如几何弱约束,高斯模板,多查询和重排序。通过简单的点积作为相似性度量,我们证明了所提出的BoW表示在获得快速响应时间的同时可以产生有竞争力的识别精度。
2. 相关工作
对于行人重识别,这些年来,有监督和无监督模型已被广泛研究。在判别模型[28,12,7,20,3]中,经典SVM(或RankSVM [28,40])和boosting [11, 30] 是流行的选择。例如,Zhao等人 [40] 使用RankSVM学习滤波器响应的权重和块匹配得分,而Gray等人[11] 通过boosting方法在局部描述符的集合中执行特征选择。最近,li等人 [20] 提出了一个深度学习网络来共同优化所有pipeline步骤。这一系列研究有助于减少多视角变化的影响,但需要费力的标注,特别是当系统中添加新摄像机时。另一方面,在无监督模型中,Farenzena等人 [8] 利用行人的对称性和不对称性,提出局部特征的对称驱动累积(SDALF). Ma等人 [25] 使用Fisher向量将局部特征编码为全局向量。为了利用行人图像中的显著信息,Zhao等人[38] 建议将更高的权重分配给罕见的颜色,这与图像搜索中的逆文档频率(IDF)[41]非常相似。本文提出了一种适用于不同摄像机网络的非监督方法。
另一方面,自从引入SIFT描述符[24]和BoW模型以来,图像搜索领域已经有了很大的发展。在过去的十年中,已经开发了无数种方法[15,42,45]来提高搜索性能。例如,为了提高匹配精度,Jégou等人 [15]在倒序文件中嵌入二进制SIFT特征。同时,精细化视觉匹配也可以通过补充描述符之间的索引级特征融合[42]产生。由于BoW模型没有考虑局部特征的空间分布(也是行人重识别领域的一个问题),另一个方向是对空间约束进行建模[45,37]。空间编码[45]通过偏移图来检查图像之间的几何一致性,而Zhang等人 [37] 发现用于编码空间信息的视觉短语。对于排序问题,有效的重排序步骤通常会带来一些改进。Liu等人[23] 设计了一个“one shot”的反馈优化方案,允许用户快速优化搜索结果。Zheng等人 [43] 建议利用分数列表的配置文件自适应地将权重分配给各种特征。在[29]中,排名最高的图像再次用作查询,最终得分是单个得分的加权和。当存在多个查询时[1],可以通过平均或最大操作来形成新的查询。本文集成了几种最先进的图像搜索技术,产生了一个有竞争力的行人重识别系统。
3. Market-1501数据集
3.1. 描述
在本文中,引入了一个新的行人重识别数据集,“Market-1501”数据集。 在收集数据集时,共有6台摄像机放在校园超市前面,其中包括5台1280×1080高清摄像机和一台720×576 SD摄像机。这些摄像头之间存在重叠。该数据集包含1306个行人的32,668个包围框。由于开放的环境,每个行人的图像最多由六台摄像机拍摄。我们确保每个标注的行人都至少由两台摄像头拍摄,以便进行跨摄像头搜索。总体而言,我们的数据集具有以下特征属性。

表1. Market-1501和现有的数据集[20,10,44,22,19,4]比较
首先,尽管大多数现有数据集都使用手工裁剪的包围框,但Market-1501数据集采用了最先进的检测器,即可变形部件模型(DPM)[9]。 基于“完美的”手绘包围框,目前的方法并没有充分考虑行人图像的不对齐,这是基于DPM的包围框中一直存在的问题。 如图1所示,在检测到的图像中,未对齐和部分缺失是常见的。
其次,除了错误正例包围框外,我们还提供了错误警报。我们注意到CUHK03数据集[20] 也使用DPM检测器,但CUHK03中的包围框在检测器方面相对较好。事实上,大量的检测到的包围框会非常“不好”。考虑到这一点,对每个检测到的包围框进行注释,提供了一个手绘的ground truth包围框(类似于[20])。与[20]不同,对于检测到的和手绘的框,计算重叠区域与联合区域的比率。在我们的数据集中,如果面积比大于50%,DPM包围框被标记为“良好”(物体检测中的例程[9]); 如果比例小于20%,DPM 包围框被标记为“干扰”; 否则,包围框被标记为“无用”[27],这意味着此图像对重识别准确性没有影响。而且,一些明显的误警报包围框也被标记为“干扰”。在图1中,“好”图像的示例显示在最上面的两行中,而“干扰”和“无用”图像位于最下面的行中。这些图像在姿态,分辨率等方面经历了广泛的变化。
第三,每个行人在每个摄像机下可能有多个图像。因此,在跨摄像头搜索过程中,每个行人可能有多个查询图像和多个ground truth。这与实际使用一致,特别是在可以充分利用多个查询图像来获得关于感兴趣的行人的更多区分性信息的情况下。在性能评估方面,对于一个重识别系统,一个完美的方法应该能够找出待查询行人的所有实例。从这个意义上说,我们的数据集为在开放系统中应用的方法提供了测试平台。

图2. 干扰数据集的示例图片
3.2. 干扰数据集
我们强调规模是行人重识别研究中的重要问题。因此,我们进一步增加了Market-1501数据集,增加了一个额外的干扰集。该数据集包含超过500,000个包围框,包含背景虚假警报以及不属于1,501个标注行人的行人。样本图像如图2所示。在实验中,除了Market-1501数据集外,我们还将报告拓展的Market-1501 + 500K数据集的结果。
表1显示了与现有数据集的统计比较。我们的数据集包含1,501个行人,少于CUHK02 [19]。 关于这一点,我们计划发布2.0版以包含更多行人。原始数据集包含32,668个完全注释的包围框,使其成为迄今为止最大的行人重识别数据集。由于包含行人的图像用手绘包围框和ID标注,因此此数据集也可用于行人检测。而且,我们的数据集被500K的干扰图像大大放大,可以可靠地进行效率/可扩展性分析。与其他基准数据集相比,Market-1501还具有6个摄像头。我们的数据集代替了仅有2台摄像头的封闭系统,可作为度量学习方法的理想基准,从而可以评估它们的泛化能力以用于实际用途。
3.3. 评估协议
当前数据集通常使用累积匹配特征(CMC)曲线来评估行人重识别算法的性能。CMC曲线显示了待查询行人出现在不同大小的候选列表中的概率。只有在给定查询只有一个真实匹配的情况下(见图3(a) ),该评估测量才有效。在这种情况下,精确度和召回率是同样的问题。但是,如果存在多个真实匹配,则 CMC曲线存在偏差,因为未考虑“召回率”。例如,图3(b) 和图3(c) 的CMC曲线都等于1,这不能提供两个排序列表之间的质量的公平比较。

图3. AP和CMC度量之间差异的一个简单例子。真实匹配和错误匹配分别为绿色和红色。对于所有三个排序列表,CMC曲线都等于1.但AP分别等于1, 1, 和0.71.
对于Market-1501数据集,每个查询平均有14.8个跨摄像头的真实匹配。因此,我们使用均值平均精度(mAP)来评估整体表现。对于每个查询,我们计算Precision-Recall曲线下的面积,即平均精度(AP)。然后,计算所有查询的AP的平均值,即mAP,它考虑算法的精准度和召回率,从而提供更全面的评估。当使用平均精度(AP)时,图3(b) 和图3(c) 中的排序列表被有效地区分。
我们的数据集被随机分为训练集和测试集,分别包含750和751个行人。在测试过程中,对于每个行人,我们在每台摄像机中选择一个查询图像。请注意,所选的查询是手绘的,而不是像在gallery中那样用DPM检测。原因在于,实际上,交互式绘制一个包围框非常方便,它可以产生更高的识别准确度[20]。搜索过程以跨摄像机模式执行,即,与查询一样来自同一摄像机捕获的相关图像被视为“无效”。在这种情况下,一个行人最多有6个查询,总共有3368个查询图像。两个行人样本的查询如图4所示。
图4. 查询图像示例。在Market-1501数据集,查询图像是人手绘制的包围框。每个行人有最多6张查询图像,一个摄像头一张。

4. 我们的方法
4.1. Bag-of-Words模型
出于三个原因,我们采用词袋(BoW)模型。首先,它很好地适应了局部特征,这些特征在之前的研究中被认为是有效的[25,38]。其次,它可以实现快速的全局特征匹配,而不是费时费力的特征-特征匹配[40,39,3]。第三,通过将相似的局部描述符量化为相同的视觉单词,BoW模型实现了对照明、视角等的一些不变性。我们描述各个步骤如下。
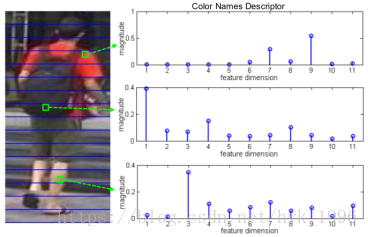
图5. 局部特征提取。我们为每个4x4图像块计算平均CN向量。每个水平条的局部特征被量化和池化为一个直方图。
特征提取。我们采用我们使用颜色命名(CN)描述符[32]。给定标准化为128×64像素的行人图像,4×4大小的图像块被密集采样。采样步长是4,因此块之间不会有重叠。对于每个块,计算所有像素的CN描述子,并且随后被L1规范化,接着是√(·)运算符[2]。用平均向量作为这个块的描述符(见图5)。
码本。对于Market-1501,我们在训练集上生成了码本。对于其它数据集,码本用独立的TUD-Brussels数据集[35] 训练。使用了标准k-means算法,因此码本的大小为k.
量化。给定一个局部描述子,我们使用多重分配(MA)[15]在码本中找到欧氏距离下的近邻。 我们设置MA = 10,所以一个特征由10个视觉词的索引表示。
TF-IDF。视觉词直方图通过TF-IDF方案进行加权。TF编码视觉词的出现次数,并且IDF被计算为 ,,其中N是gallery中的图像的数量,是包含视觉词i的图像的数量。在本文中,我们使用avgIDF [41]变体代替标准的IDF。
突发性。突发性是指查询特征在测试图像中发现多个匹配的现象[16]。对于CN描述符,由于与SIFT相比具有较低的判别能力,所以突发性可能更为普遍。因此,直方图中的所有项除以√tf。
负证据。根据[14],我们计算训练集中的平均特征向量。然后,从所有测试特征中减去均值向量。 因此,特征向量中的零元素也被考虑到点积中。
相似度函数。给定一个查询图像Q和一个gallery图像G,我们计算它们特征向量间的点乘。注意,在用L2范数标准化后,点积等于欧几里德距离。在大规模的实验中,近似最近邻算法[33] 采用欧几里得距离。
4.2. 改进
弱几何约束。在行人重识别中,编码几何约束的流行方法包括“邻接约束搜索”(ACS)[38,39]。 这种方法在结合空间约束方面是有效的,但是其计算成本很高。受到空间金字塔匹配[18]的启发,我们将ACS整合到BoW模型中。如图5所示,输入图像被划分成M个水平条纹。然后,对于条纹m,视觉词直方图被表示为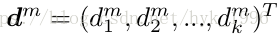

背景抑制。背景干扰的负面影响已被广泛研究[8,38,39]。在一个解决方案中,Farenzena等人 [8]提出通过分割将前景行人与背景分开。
由于为每幅图像生成掩膜的过程既费时又不稳定,本文提出了一种简单的解决方案,在图像上施加一个二维高斯模板。具体而言,高斯函数采用N(μx,σx,μy,σy)的形式,其中μx,μy是水平和垂直方向的高斯平均值,而σx,σy是水平和垂直方向的高斯标准差。我们将(μx,μy)设置为图像中心,并且对于所有实验设置(σx,σy)=(1,1)。该方法假定人位于图像的中心,并且被背景包围。
多个查询。在图像搜索[1]和重识别 [8]的研究中表明,多个查询的使用可以产生出色的结果。由于考虑了类内方差,该算法对行人变化更加鲁棒。
当每个行人在单个摄像机中具有多个查询图像时,基于速度的考虑,我们将它们合并为单个查询,而不是多对多匹配策略[8]。在这里,我们采用两种池化策略,即平均池化和最大池化。在平均池化中,多个查询的特征向量按平均总和池化成一个; 在最大池化中,最终特征向量从所有查询中获取每个维度中的最大值。
重排序。当把行人重识别看作是排序问题时,很自然想到了使用重排列算法。在本文中,我们使用一种简单的重排列方法,将最初排序列表中排名最高的T张图像作为查询再次搜索gallery。具体地,给定查询Q的初始排序列表,将作为列表中第i个图像R i用作查询。当使用R i作为查询时,gallery图像G的相似度得分被表示为S(R i,G)。我们为每个top-i排序的查询分配一个权重1 /(i + 1),i = 1,...,T,其中T是扩展查询的数量。然后,查询Q的gallery图像G的最终分数被确定为,

其中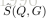
5. 实验
5.1. 数据集
VIPeR数据集[10] 由632个行人组成,每个行人有两张从两个不同的摄像头捕获的图像。所有图像被归一化为128×48像素。VIPeR被随机分成两半,一半用于训练,另一半用于测试。每一半包含316个行人。对于每个行人,我们从一个摄像头拍摄的图像作为查询,并执行跨摄像头搜索。
CHUK-03数据集[20] 包含1467个行人的13,164个DPM 包围框。每个行人由两台摄像机观察,每个视角平均有4.8张图像。按照[20]中的协议,对于测试集,我们随机选择100个人。对于每个人,所有的图像都被轮流用作查询,并进行跨摄像机搜索。测试过程重复20次。我们报告了VIPeR和CUHK03数据集的CMC得分和mAP。
5.2. 重要的参数
码本大小k. 在我们的实验中,构造了不同大小的码本,在Market-1501数据集上的mAP得分如表2所示。当k=350时可以得到最高得分。
条纹的数目M. 表3展示了不同条纹数目下的性能。随着条纹数量的增加,对行人图像的更精细划分导致更具辨别性的表示。因此识别准确度增加,对于太大的M值,召回率可能会下降。作为一个速度和准确率的权衡,在实验中我们选择将图像分割成16个条纹。
扩展查询的数量T. 表4总结了不同数量的扩展查询获得的结果。我们发现当T = 1时达到最佳性能。当T增加时,mAP缓慢下降,这证实了对于T的鲁棒性。重排序的性能高度依赖于初始列表的质量,而较大的T会引入更多的噪音。在下面,我们将T设置为1.

表2. 码本大小对Market-1501的影响。我们的结果由“BoW + Geo + Gauss”得到。

表3. 水平条数目对Market-1501的影响。我们的结果由“BoW + Geo + Gauss”得到。

表4. 拓展查询图像数目对Market-1501的影响。T=0对应于“BoW + Geo + Gauss + MultiQ_max”
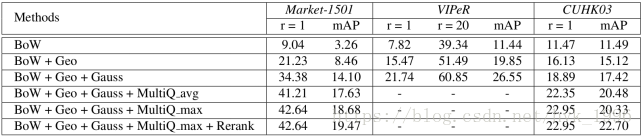
表5. 通过结合不同的方法( 即,BoW模型(BoW),弱几何约束(Geo),背景抑制(Gauss) )在三个数据集上的结果( rank-1,rank-20的匹配率和均值平均精度(mAP),平均多查询(MultiQ_avg) 和最大池化(MultiQ_max),以及重排序(Rerank)。请注意,这里我们使用BoW的颜色名称描述符。
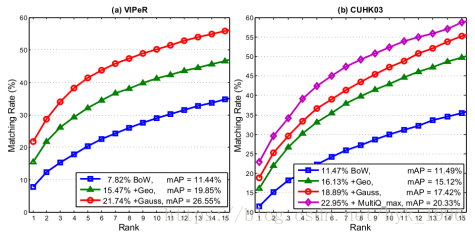
图6. 在VIPeR和CUHK03数据集下,不同方法结合的性能
5.3. 评估
BoW模型和它的改进。我们在表5和图6中给出了由BoW、几何约束(Geo)、高斯掩模(Gauss)、多重查询(MultiQ)和重排列(Rerank)获得的结果。
第一,基线BoW矢量产生了相对较低的准确性:rank-1准确率= 9.04%、10.56%和5.35%,分别对应Market-1501、VIPeR和CUHK03数据集。
第二,当我们通过条纹匹配来整合几何约束时,我们观察到准确性的连续提高。例如,在Market-1501数据集中,mAP从3.26%上升到8.46%(+ 5.20%),rank-1准确度从9.04%到21.23%(+ 12.19%)可以看到更大的改进。
第三,很显然,高斯掩膜在所有三个数据集上运作良好。我们在Market-1501数据集的mAP中观察到5.64%的提升。 因此,行人大致位于图像中央的先验在统计上是合理的。
其次,我们在CUHK03和Market-1501数据集上测试多查询,其中每个待查询行人具有多个包围框。结果表明使用多查询进一步提高了识别的准确性。Market-1501数据集的改进更为突出,查询图像的外观更加多样化(参见图4)。此外,通过最大池化的多重查询略优于平均池化,可能是因为最大池化提供了更多权重给罕见但突出的功能,并提高了召回率。
最后,我们从表4和表5看出,重排列会产生更高的mAP。然而,重排序的一个常见问题是对初始排序列表的质量的敏感性。在Market-1501和CUHK03数据集上,由于大多数查询不具有top-1匹配,因此mAP的改进相对较小。
摄像头组之间的结果。为了进一步理解Market-1501数据集,我们提供了所有摄像头对之间的重识别结果,如图7所示。我们使用“BoW+Geo+Gauss”表示。很容易知道,在同一个摄像头中的重识别会产生最高的准确性。另一方面,正如预期的那样,不同摄像头对之间的表现差异很大。对于摄像头对1-4和3-5,BoW描述符产生相对较好的性能,这主要是因为两个摄像头对共享更多重叠。此外,摄像头6是一个720×576 SD摄像头,并捕捉与其他高清摄像头不同的背景,因此摄像头6和其他摄像头之间的重识别准确度非常低。在摄像头对5-1和5-2之间可以观察到类似的低结果。我们还计算了跨摄像头的平均mAP和平均rank-1准确度:分别为10.51%和13.72%. 我们根据查询次数对不同摄像机对之间的mAP进行加权,并且不计算对角线上的结果。与表5中的“BoW + Geo + Gauss”线相比,这两种测量结果都远远低于所有摄像头作为gallery时的池化图像。这表明在我们的数据集中,摄像头对间重识别非常具有挑战性。
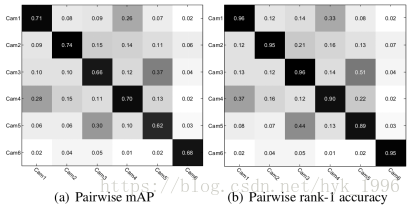
图7. Market-1501上摄像头对之间的重识别性能表现: (a) mAP和 (b) rank-1准确率。垂直和水平轴上的摄像头分别是probe和gallery. 跨摄像头平均mAP和平均rank-1准确度分别为10.51%和13.72%.

图8. 在VIPeR上和最先进方法的比较。我们结合了HS和CN特征,和eSDC方法。

表6. 在CUHK03和Market-1501上的方法比较

表7. 在Market-1501数据集上不同步骤的平均查询时间。为了公平地比较,采用Matlab实现。
和最先进方法的比较。我们将我们的结果和最先进方法相比较,如图8和表6所示。在VIPeR(图8)中,我们的方法优于两种无监督方法,即eSDC [39],SDALF [8]。具体而言,当使用两个特征时,即颜色名称(CN)和HS直方图(HS),我们实现26.08%的rank-1识别率。当eSDC [39]进一步整合时,匹配率增加到32.15%.
在CUHK03上,我们的没有多查询的方法显著优于几乎所有的方法。与建立深度学习架构的FPNN [20]相比,我们的精确度略低1.00%. 但是,当多查询和HS特征集成时,CUHK03数据集上的rank-1匹配率超过[20] + 4.44%。
在Market-1501上,我们与包括HistLBP [36]、gBiCov [26]和LOMO [21]在内的最新描述符进行比较。我们提出的BoW描述符明显优于这些竞争的方法。然后,我们在BoW上应用各种度量学习方法[34,6,17](在PCA降至100维之后)。不使用成对训练(在大型摄像机网络下可能代价高昂[31]),我们将6台摄像机中的所有正负对作为训练样本。我们观察到度量学习带来了不错的改进。
Market-1501数据集中的一些样本结果提供在图9中。除了随着方法演进而增加的mAP,另一个值得注意的发现是,DPM检测到的复杂背景或身体部位等干扰图像会严重影响重识别的准确性。以前的研究通常只关注“良好”的包围框,而很少研究检测器的错误。
大规模数据的实验。首先,在Market-1501上,我们在两个方面比较了我们的方法与SDALF [8]和SDC [39],即特征提取和搜索时间。我们使用作者的Matlab实现,为了公平的比较,也在Matlab中运行我们的算法。在2.59 GHz CPU和256 GB内存的服务器上进行评估,效率结果如表7所示。对于我们的方法,我们通过HS(我们提取了一个20维的HS直方图并生成另一个与CN融合的BoW矢量)和CN特征报告总时间。与SDC相比,我们实现了两个数量级以上的效率增益。对于SDALF,涉及三个特征,即MSCR,wHSV和RHSP。特征提取时间分别为0.09s,0.03s,2.79s; 搜索时间分别为2643.94s,0.66s和0.20s. 因此,我们的方法比SDALF快三个数量级。

图9.Market-1501数据集上的样本结果。四行对应于四种配置,即“BoW”,“BoW + Geo + Gauss”,“BoW + Geo + Gauss + MultiQ”和“BoW + Geo + Gauss + MultiQ + Rerank”. 原始查询位于蓝色的bbox中,添加的多个查询以黄色显示。与查询具有相同身份的图像位于绿色框中,否则为红色。
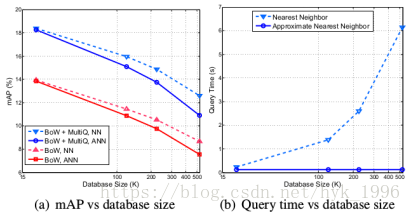
图10. mAP (a) 和查询时间 (b) 在Market-1501 + 500K数据集中。虚线由精确的NN搜索获得,而实线代表ANN搜索。
然后,我们在Market-1501 + 500K数据集上进行实验。将500K数据集中的图像视为异常值。为了提高效率,我们使用[33]中提出的近似最近邻(ANN)算法。在索引构建过程中,我们构建4棵kd树,并以knn图的形式为每个数据存储50个近邻。NN和ANN返回的近邻数目都是1000(因此NN的mAP略低于表5中的报告)。
大规模数据集的重识别性能表现如图10所示。随着数据库变大,精度下降。在Market-1501 + 500K数据集上,使用ANN时,“BoW + MultiQ max”达到10.92%的mAP。与原始数据集的结果相比,观察到相对下降69.7%. 因此,数据库大小对性能有显著的负面影响,这在文献中很少讨论。而且,虽然ANN略微降低了重识别的准确性,但它带来的好处却很明显。使用ANN,500K数据集的查询时间为127.5ms,与NN情况相比,查询速度提高了50倍。
6.结论
本文首先介绍了一个大规模的重识别数据集Market-1501(+ 500k),它更接近实际设置。然后,提出了一个BoW描述子,试图弥合行人重识别和图像搜索间的差距。新的数据集将使多个方向的研究成为可能,如深度学习、大规模度量学习、多重查询技术、搜索重排序等等。将来,当前的测试数据将被视为验证集,并且新的测试ID将在即将到来的行人重识别挑战中被标注并出现。
参考文献
[1] R. Arandjelovic and A. Zisserman. Multiple queries for large scale specific object retrieval. In BMVC, 2012.
[2] R. Arandjelovic and A. Zisserman. Three things everyone should know to improve object retrieval. In CVPR, 2012.
[3] D. Chen, Z. Yuan, G. Hua, N. Zheng, and J. Wang. Similarity learning on an explicit polynomial kernel feature map for person re-identification. In CVPR, 2015.
[4] D. S. Cheng, M. Cristani, M. Stoppa, L. Bazzani, and V. Murino.Custom pictorial structures for re-identification. In BMVC, volume 2, page 6, 2011.
[5] A. Das, A. Chakraborty, and A. K. Roy-Chowdhury. Consistent re-identification in a camera network. In ECCV. 2014.
[6] J. V. Davis, B. Kulis, P. Jain, S. Sra, and I. S. Dhillon. Information-theoretic metric learning. In ICML, pages 209–216. ACM, 2007.
[7] M. Dikmen, E. Akbas, T. S. Huang, and N. Ahuja. Pedestrian recognition with a learned metric. In ACCV. 2011.
[8] M. Farenzena, L. Bazzani, A. Perina, V. Murino, and M. Cristani.Person re-identification by symmetry-driven accumulation of local features. In CVPR, pages 2360–2367. IEEE, 2010.
[9] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part-based models. T-PAMI, 32(9):1627–1645, 2010.
[10] D. Gray, S. Brennan, and H. Tao. Evaluating appearance models for recognition, reacquisition, and tracking. In Proc. IEEE International Workshop on Performance Evaluation for Tracking and Surveillance,volume 3, 2007.
[11] D. Gray and H. Tao. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In ECCV. 2008.
[12] M. Hirzer, C. Beleznai, P. M. Roth, and H. Bischof. Person re-identification by descriptive and discriminative classification. In Image Analysis, pages 91–102. Springer, 2011.
[13] M. Hirzer, P. M. Roth, M. Köstinger, and H. Bischof. Relaxed pairwise learned metric for person re-identification. In ECCV. 2012.
[14] H. Jégou and O. Chum. Negative evidences and co-occurences in image retrieval: The benefit of pca and whitening. In ECCV. 2012.
[15] H. Jegou, M. Douze, and C. Schmid. Hamming embedding and weak geometric consistency for large scale image search. In ECCV, pages 304–317. Springer, 2008.
[16] H. Jégou, M. Douze, and C. Schmid. On the burstiness of visual elements. In CVPR, pages 1169–1176, 2009.
[17] M. Kostinger, M. Hirzer, P. Wohlhart, P. M. Roth, and H. Bischof.Large scale metric learning from equivalence constraints. In CVPR, pages 2288–2295, 2012.
[18] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In CVPR, 2006.
[19] W. Li and X. Wang. Locally aligned feature transforms across views. In CVPR, pages 3594–3601, 2013.
[20] W. Li, R. Zhao, T. Xiao, and X. Wang. Deepreid: Deep filter pairing neural network for person re-identification. In CVPR, pages 152–159, 2014.
[21] S. Liao, Y. Hu, X. Zhu, and S. Z. Li. Person re-identification by local maximal occurrence representation and metric learning. In CVPR, 2015.
[22] S. Liao, Z. Mo, Y. Hu, and S. Z. Li. Open-set person re-identification. arXiv preprint arXiv:1408.0872, 2014.
[23] C. Liu, C. C. Loy, S. Gong, and G. Wang. Pop: Person re-identification post-rank optimisation. In ICCV, 2013.
[24] D. G. Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 60(2):91–110, 2004.
[25] B. Ma, Y. Su, and F. Jurie. Local descriptors encoded by fisher vectors for person re-identification. In ECCV Workshops and Demonstrations, pages 413–422. Springer, 2012.
[26] B. Ma, Y. Su, and F. Jurie. Covariance descriptor based on bio-inspired features for person re-identification and face verification. Image and Vision Computing, 32(6):379–390, 2014.
[27] J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman. Object retrieval with large vocabularies and fast spatial matching. In CVPR, pages 1–8, 2007.
[28] B. Prosser, W.-S. Zheng, S. Gong, T. Xiang, and Q. Mary. Person re-identification by support vector ranking. In BMVC, volume 1, page 5, 2010.
[29] X. Shen, Z. Lin, J. Brandt, S. Avidan, and Y. Wu. Object retrieval and localization with spatially-constrained similarity measure and knn re-ranking. In CVPR, 2012.
[30] Y. Shen, W. Lin, J. Yan, M. Xu, J. Wu, and J. Wang. Person re-identification with correspondence structure learning. In ICCV, 2015.
[31] C. Su, f. Yang, S. Zhang, Q. Tian, L. Davis, and W. Gao. Multi-task learning with low rank attribute embedding for person re-identification. In ICCV, 2015.
[32] J. Van De Weijer, C. Schmid, J. Verbeek, and D. Larlus. Learning color names for real-world applications. TIP, 18(7):1512–1523, 2009.
[33] J. Wang and S. Li. Query-driven iterated neighborhood graph search for large scale indexing. In ACM MM, 2012.
[34] K. Q. Weinberger, J. Blitzer, and L. K. Saul. Distance metric learning for large margin nearest neighbor classification. In NIPS, pages 1473–1480, 2005.
[35] C. Wojek, S. Walk, and B. Schiele. Multi-cue onboard pedestrian detection. In CVPR, pages 794–801. IEEE, 2009.
[36] F. Xiong, M. Gou, O. Camps, and M. Sznaier. Person re-identification using kernel-based metric learning methods. In ECCV. 2014.
[37] S. Zhang, Q. Tian, G. Hua, Q. Huang, and S. Li. Descriptive visual words and visual phrases for image applications. In ACM MM, 2009.
[38] R. Zhao, W. Ouyang, and X. Wang. Person re-identification by salience matching. In ICCV, 2013.
[39] R. Zhao, W. Ouyang, and X. Wang. Unsupervised salience learning for person re-identification. In CVPR, 2013.
[40] R. Zhao, W. Ouyang, and X. Wang. Learning mid-level filters for person re-identification. In CVPR, 2014.
[41] L. Zheng, S. Wang, Z. Liu, and Q. Tian. Lp-norm idf for large scale image search. In CVPR, 2013.
[42] L. Zheng, S. Wang, Z. Liu, and Q. Tian. Packing and padding: Coupled multi-index for accurate image retrieval. In CVPR, 2014.
[43] L. Zheng, S. Wang, L. Tian, F. He, Z. Liu, and Q. Tian. Query-adaptive late fusion for image search and person re-identification. In CVPR, 2015.
[44] W.-S. Zheng, S. Gong, and T. Xiang. Associating groups of people. In BMVC, volume 2, page 6, 2009.
[45] W. Zhou, Y. Lu, H. Li, Y. Song, and Q. Tian. Spatial coding for large scale partial-duplicate web image search. In ACM MM, 2010.