转载请注明出处:https://www.cnblogs.com/White-xzx/
原文地址:https://arxiv.org/abs/1811.07130
【Abstract】
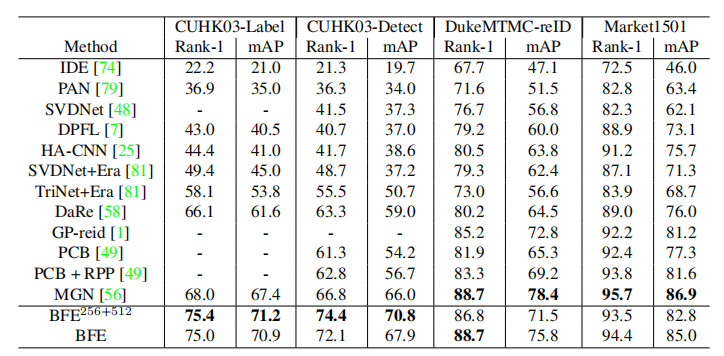
这篇文章展示了行人ReID的一个新的训练机制——批特征擦除(Batch Feature Erasing,BFE)。作者运用这个方法来训练一个新的网络,该网络由以ResNet50为主网络和两个分支组成,这两个分支分别由一个全卷积分支和一个特征擦除分支构成。当训练特征擦除分支时,随机擦除整个batch中所有特征图的相同区域。然后通过两个分支的特征级联来进行行人ReID。该方法虽然简单,但在行人ReID中达到了最新水平,同时能够应用于一般的图像检索问题的一般测度学习任务。例如,该方法在CUHK03-Detect数据集上的Rank1达到了75.4%的准确率,在Stanford Online Products数据集上达到了83.0%的Recall-1分数,大幅超过了现有的方法。
【Introduction】
行人ReID相当于,从没有视觉重叠的多个摄像头检测到的不同行人图片中,鉴定是否为同一个人。这在视频监控中有重要应用,也是一个有意义的计算机视觉挑战。近期的大部分工作都聚焦于学习合适的特征表达来达到对姿势、光照、视觉角度改变的鲁棒性来促进行人ReID。其中,许多工作设法定位不同的肢体部分和对齐相关联的特征,其他工作则使用粗分割和注意力选择网络来提高特征学习。
这篇文章研究训练行人ReID神经网络的优化过程。作者展示了一个简单但有效的训练机制,BFE,其随机裁剪掉同一batch中所有图片学习到的特征图的一个区域。不同于DropBlock,作者提倡使用批处理,即同一batch中的所有图片使用相同的方式裁剪。当所有的输入图片粗略地对齐,这种批操作对测度学习任务尤其有效,如行人ReID的场景。直观上来说,它禁用了同一batch的所有图片中与语义部分相关的所有特征,如头,腿,包等等,来强化网络对剩余特征学习更好的表达。如图1。

图1:(a)同一batch的输入图片。
(b)来自上一个基础网络resnet50的输出,通过特征向量L2正则化的灰度强度可视化的相应特征图。
这些简单的训练策略使行人ReID的结果得到了提高。Resnet-50和hard triplet loss损失函数与BFE的网络结构,在CUHK03-
Detect 数据集上达到了74.4%的Rank1准确率,这比最新成果高了7.6%。
BFE也能够被不同的测量学习方案所采用,包括triplet loss、lifted structure loss、weighted sampling based margin loss和histogram loss。在CUB200-2011、 CARS196、In Shop Clothes Retrieval数据集和 Stanford online products数据集上进行图像检索任务的测试,BFE也能够在不同方案中同样提高Rank1准确率。
【Related work】
【Problem Formulation】
行人ReID经常被公式表示为一个图片检索问题,其目标是从一个大的候选图片集合中找到最相似的图片。这个检索问题可以通过找到标定函数f(·)和度量函数D(· , ·)来解决,其通过标定一张输入图片x为高维特征向量f(x),然后再通过可度量的D(f(x), f(y))来度量两个标定向量f(x)和f(y)的的相似度。
在这篇文章中,作者简单地使用了欧氏距离作为度量函数D(· , ·)和训练一个神经网络来学习标定函数f(·)。可以用如下公式表达一般的图像检索问题,提供C类的数据集X,并将X划分为拥有Ctrain类的训练集Xtrain和拥有Ctest类的测试集Xtest,注意Ctrain和Ctest的没有相同的类别。然后在Xtrian图片样本上使用合适的损失函数训练一个神经网络来学习标定函数f(·)。在测试中,首先对Xtest中的所有图片计算特征标定来建立一个标定向量的数据库Ftest。然后对每一张Xtest中的测试图q,计算它的标定fq,并在标定数据库Ftest中搜索K-最近邻,标定的检索图片本身不包括在那些KNN中。对每一个返回的KNN结果,如果其类别与检索图片的类别是一致的我们则认为是正确的。
因为每个人可以看作是同一个类,所以行人ReID问题能够被当做一个图像检索问题。另外,每张行人图片都有一个摄像机ID来指明是由哪个摄像机抓拍到的。在人ReID中,在测试集Xtest中每个人的检索图片被选来建立检索数据库Xquery,剩余的测试图片组成gallery数据集Xgallery。换句话说,X被分割成train、query和gallery,train有Ctrain个ID,query和gallery拥有相同的Ctest个ID。训练过程与一般的图片检索相同,在测试时,计算gallery数据集的标定数据库Fgallery并在query数据集中搜索每张检索图片的KNN结果。为了使问题更具有挑战性,作者仅认为当具有相同人ID和不同摄像机ID时,检索图片返回的结果是正确的。
【Batch Feature Erasing (BFE) Network】
【Backbone Network】作者使用ResNet50作为backbone来提特征,并对网络结果进行了轻微的改动,在stage4中没有采用下采样的操作,从而得到尺寸为2048×24×8的更大特征图。
【ResNet-50 Baseline】在backbone网络顶部添加了一个global branch的分支。确切地说,在残差网络stage4 后使用了全局平均池化来得到一个2048维特征向量,通过一个1×1卷积层、bn层和一个ReLU层维度减少为512,输入triplet loss和softmax loss,作者将这个全局平均池化分支和backbone一起表示为ResNet50.
【Baseline】
【Batch Feature Erasing Layer】在单个batch中,输入图片由backbone网络产生的特征向量T,被BFE层随机擦除相同的区域。所有的擦除区域都以零为输出,所有的算法细节都在Algorithm 1。

在Figure 2中可视化了BFE层在triplet loss中的应用,同时其也能在其他损失函数中采用。擦除区域的高度和宽度会因不同task而不同。但是通常擦除的区域必须足够大到能够覆盖输入特征图的一个语义区域。
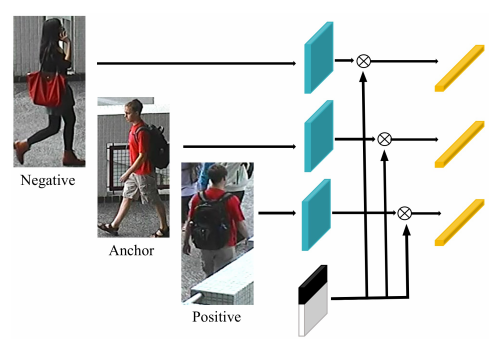 Figure 2:BFE在triplet loss函数中的表示
Figure 2:BFE在triplet loss函数中的表示
【Structure of the BFE Network】Figure 3展示了BFE网络的结构,由global branch和特征擦除branch组成。global branch有两个目的。第一,为了提供全局特征表达;第二,用于监督特征擦除分支的训练。特征擦除分支使用BFE层处理特征图T并提供批量擦除特征图T'。然后用全局最大池化得到2048维的特征向量,最终在triplet loss和softmax loss中减到1024维,网络中没有用到Dropout。
应用在特征图T上的多层卷积ResNet bottleneck模块是十分重要的,如果缺少该模块,则全局平均池化层和全局最大池化必须同时应用在特征图T上,从而造成网络难以收敛。根据作者的观察,经过特征擦除层后平均池化是不稳定的,因此在特征擦除分支中使用全局最大池化代替平均池化。
来自global branch和feature erasing branch的特征进行级联然后作为一张行人图片的标定向量。有三点值得注意的是,①BFE层不会增加网络大小;②BFE层能够应用到除了人ReID的其他度量学习任务;③BFE超参数能够经过微调而不改变网络结构来适应不同的task。

Figure 3:batch hard triplet loss的BFE网络结构在人ReID中的表示。在ResNet50 stage4之后添加了 global branch,feature erasing branch引入了一个掩膜来裁剪 bottleneck特征图中的一个较大区域;在测试时,对来自两个分支的特征进行级联来作为最终的行人图片的描述子。
【Loss function】损失函数是在两个分支上soft margin batch-hard triplet loss与softmax loss的和。soft margin batch-hard triplet loss 的定义如下,

P:不同人的数量;K:每个人的图片数量;所以在一个batch中有P×K个的三元组。
lBH(·) 表示batch-hard triplet loss。对每一个锚图片Xai,从ID都为i的图片中选择最大距离的图片作为正图片Xpi ,在不同的ID=j的图片中选择距离最小的图片作为负图片Xnj。因此,Xai、Xpi、Xaj建立了一个三元组。lSBH(·) 是在一个batch中的所有三元组的soft margin batch-hard triplet loss之和。D(·, ·) 表示欧氏距离函数,fθ 是BFE网络学习的特征标定函数。
【Experiments】
训练时,输入图片resize为384×128,然后通过水平翻转、归一化和随机擦除进行数据增强。在BFE层,作者设置擦除的高度比率为0.5,宽度比率为1.0,这些比率在所有的人reid数据集中设置均相同。测试图片被resize到384×128,仅通过归一化进行数据增强。
对每张检索图片,我们将所有的gallery图片按它们与检索图片欧氏距离大小进行降序排列,然后计算CMC曲线。作者使用rank1的准确率和mAP作为评价标准。具有相同人ID和摄像机ID的结果没有被计算在内,值得注意的是,为了简便,所有的实验都是单一查询设置并没有reranking。
作者用了4个GTX1080 GPU,batchsize为128,每个id包含4张图片在一个batch中,所以有32个id每个batch;使用batch hard soft margin triplet loss和Adam优化器。
实验结果比较,BFE256+512表示global branch的特征维度为256,feature erasing branch的特征维度为512,

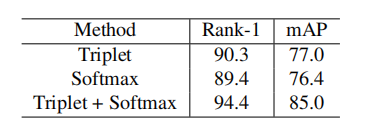
【Benefit of Triplet and Softmax Joint Training.】以下显示了Market1501在不同的loss组合训练的效果,联合训练的方法对提高性能有帮助。
【Benefit of Global and Feature Erasing Branches】没有global branch的情况下,BFE网络的表现比backbone网络的表现略差。BFE层相当于正则化方法的作用,两个分支能够完成同时从global branch学习突出的外貌特征,从 feature erasing branch学习可区分的细粒度特征,两个分支互相作用并对最终的结果同样重要。
【Comparison with Dropout Strategies】
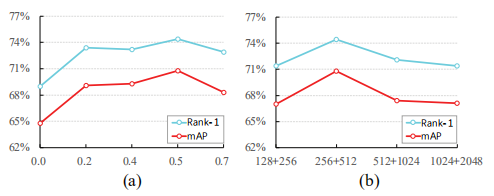
【Impact of BFE Layer Hyper-parameters】【Impact of Embedding Dimensions】擦除比率参数对性能的CMC分数和mAP的影响。(a)固定了宽度比率为1,高度比率变化对指标的影响。(b)在 CUHK03-Detect数据集上,特征维度对指标的影响。高维度的特征描述子具有更加的表达性但在测试时容易过拟合。
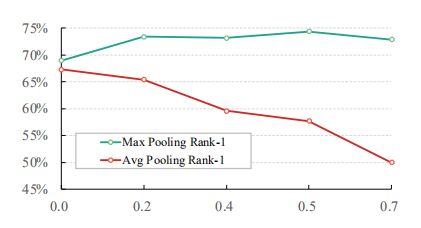
【Average Pooling vs Max Pooling in Feature Erasing Branch】实验表明,feature erasing branch中,在不同的高度擦除比下,最大池化对收敛的鲁棒性更强、对性能提高影响更大。
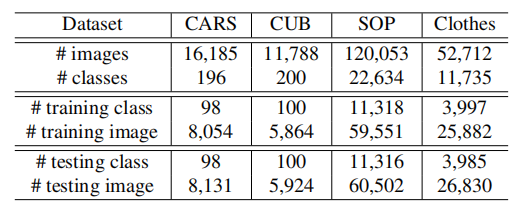
【Image Retrieval Experiments】在图片检索数据集上直接进行图片检索实验,训练图片的操作:保持宽高比,经过填充和resize为256*256,再随机裁剪为224*224。测试时,CUB200-2011, In-Shop Clothes数据集的图片填充较短边,然后缩放到256*256,其他数据集直接缩放到256*256,高度和宽度的擦除比都设置为0.5,


【Adapt to Other Metric Learning Methods】采用其他测度损失函数的性能对比
