通过Lifted Muliticut和行人重识别进行多行人跟踪
1. 摘要
多行人跟踪中,遮挡处理和person re-identification是比较重要的。
本文的创新点:
1、 将multi-persontracking问题看成最小化代价lifted multicut问题。在regular edges的基础上引入lifted edges。
2、 设计并训练融合行人人体姿势信息的深度神经网络来进行行人重识别。这样能够通过外表特征更加准确的识别同一人。将时间上较远的人关联起来,并允许它们将遮挡之前和之后对应起来。
这两个创新点分别在2,3章节中详细讨论。
2. 模型
将多行人跟踪数学抽象成MP、LMP问题。是一种基于图的分解/聚类问题。
MP:the minimum cost muticut problem. LMP: minimum cost lifted muticutproblem.
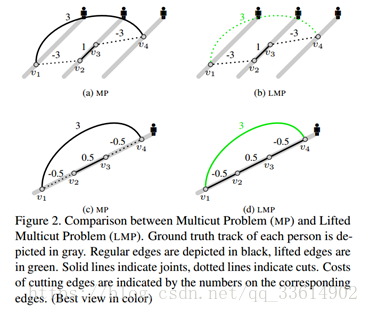
图中,v表示在帧中检测到的行人,实线表示joint (两个v可以认为是同一个行人),虚线表示cut (认为是两个不同的行人),黑线表示regular edge,绿线表示lifted edge,线上数字表示cut对应边的代价。
a,b场景中有三个不同的目标人,其中v1是单独的目标,v2、v3是同一目标,v4是单独目标。v1和v4在时间上相聚较远,MP错误的将v1,v4认为是同一人,而LMP通过lifted edge连接v1,v4,由于local edges不支持长距离的joint,所以这条lifted edge被cut。
c,d场景中v1,v2,v3,v4来自同一目标人。由于遮挡等问题,MP错误的将v1,v2,v3,v4认为是三个目标,而LMP通过lifted edge连接v1,v4,并认为v1和v4是一个confident observation,cut的代价很高,最终正确认为所有的v来自同一目标人。
2.1 参数
a)有限集V表示在一幅图像中的一个目标检测,即跟踪框。对于每个目标检测v∈V,它的高度是h_v,中心位置是(x_v,y_v),帧数是t_v。
b)对于每对v,w∈V,条件概率p_vw∈(0,1)表示v,w分属于不同目标的概率。
c)在图G=(V,E)中,每个边都是regular边,表示在相同帧中连接v,w,或者在不同帧但是帧数相近中连接v,w,并且这个差距存在上界δ_t≥|t_v-t_w |。
d)在图G'=(V,E')中,E⊆E',lifted边{v,w}∈E'\E,表示在不同帧中连接相似的v,w,并且满足|t_v-t_w |≥δ_t和p_vw≤p_0,其中p_0∈(0,0.5)
2.2 可行性解集
LMP的任一可行解都是01向量x∈{0,1}^(E' ),其中x_vw=1表示结点v和w属于不同分量。为了使x能定义G的分量,扩展补充定义:在X_(GG' )∈{0,1}^(E' )中的量x∈{0,1}^(E' ),存在以下约束:
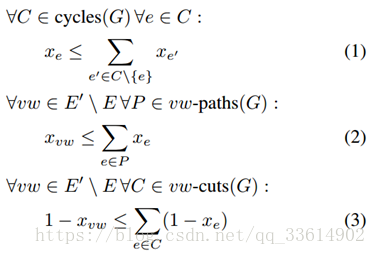
约束(1)表示,对于任意邻居结点v和w,如果在G中存在一条路径,这个路径的所有边都标记为0,那么vw的边也只能标记为0。
约束(2)(3)表示,当且仅当v和w再一个更小的图中相连,并且路径的边都标记为0,对于所有的可行解和所有的lifted边vw∈E'\E,x_vw都标记为0。(意味着v和w属于同一个目标)
通过给lifted边vw∈E'\E分配cost c_vw ,我们可以不用将v和w直接相连再求概率,而是可以给可行解中分属于不同目标的v,w分配cost。
2.3 目标函数
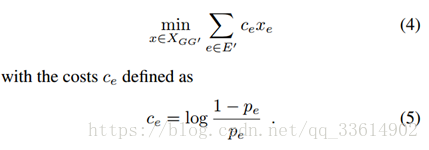
式(4)表示选择那些能最大化相同目标和不同目标概率的分量对。
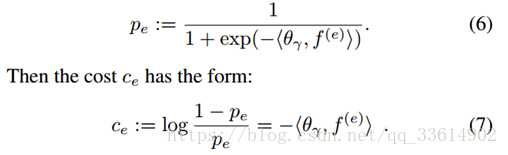
θ_γ是在训练集上通过logistic回归估计得到的,γ表示目标检测对之间间隔长度。f^((e))在这里表示目标检测间的相似度。
2.4 优化
使用[1]的启发式方法,其中子图的双划分由一组变换序列更新。
3 跟踪中的行人重识别
主要比较多个CNN结构对重识别问题的作用,本文的基础CNN结构是VGG-16 Net。然后将MOT15benchmark、MOT16 benchmark中的5个序列作为训练集;将CUHK03、Market-1501用于人物识别例子;将MOT16中的序列MOT16-02和序列MOT16-11作为测试集。总共2511个identities用作训练,123个identities用作测试。
3.1 结构
a)ID-Net:首先使用VGG net 从收集好的数据集中学习N=2511个identities,即N分类问题,然后将图像划分成112*224*3,每个图像xi与ground truth identity标记yi∈{1,...,N}相连接,VGG就将每个图像属于每个标记的概率pi=∅(xi)作为前向传播函数,而损失函数则选择softmax。
在测试时,给定一个没有identities标记的图像,最后的softmax层将被移除,然后全连接层∅f7将的输出将用作identity的特征。给定一对图像,两identity特征的欧几里得距离将被用作判断是否这对图像是否具有相同的identity。在实验中作者认为这个identity特征已经有较好准确度,然而使用SiameseNet和StackNet的效果将会更上一层楼。

b)SiameseNet:一个Siamese结构指的是含有共享参数的两个对称CNNs的网络。为了对相似性建模,作者在两个CNNs顶部使用一个全连接层,通过这层就可以由一组图像得到特征FC6(xi)和FC6(xj),然后再通过后面两个全连接层FC7和FC8连接并转换。其中紧接着FC7的是非线性的ReLU,而FC8则使用softmax函数产生概率估计来判断它们是含有相同的identity还是不同的identities。
c)StackNet:首先将一对图像根据RGB通道存到栈中,这样的话网络的输入大小就变成112*224*6,第一个卷积层大小也从3*3*3变成3*3*6,剩下的网络则使用VGG的结构。最后的全连接层和SiameseNet的FC8一样,将输出这对图像是否含有相同identity或不同identities。
在测试时,给定一对图像,SiameseNet和StackNet将输出得到是否含有相同或不同identities的概率作为前向传播。
StackNet允许一对图像在网络早期阶段进行比较,但是仍然受限于与目标身体部分回馈的配合。
3.2 融合身体部分信息
目前网络需要改进的是如何提取身体部分信息,并将此作为一个感兴趣的局部区域,然后基于这个局部区域和整个图像再计算图像对之间的相似性。作者将融合身体部分的检测加入到CNN中,并且为图像对的14个不同身体部分计算score maps(由于对称最终得到7个scores maps),每一个都和输入图像具有相同大小。然后将这些图也存到栈中,这样就有112*224*20的输入大小,第一个卷积层大小也变成了3*3*20,剩下的和StackNet后面的结构一样。
3.3 实验分析
训练:实施基于Caffe深度学习框架。ID-net中的VGG模型是在ImageNet分类任务中预先训练好的。然后使用ID-Net作为学习SiameseNet, StackNet和StackNetPose的初始化,这样能够使训练更快并产生更好的结果。
Setup:从MOT16-02和MOT16-11收集的123个行人身份作为测试集。在两个序列中,当检测到的某一行人身份与现有的123个行人身份的intersection-over-union大于0.5时,才被认为时true positive。根据跟踪期间的正负样本分布,从相同身份的检测结果中随机选择1000个正配对、不同检测结果中选择4000个负配对作为测试集。对于ID-Net当两图像之间的特征值距离小于阈值时,认为它们可以构成图像对。这个阈值是在单独的验证数据上取得的,以最大化验证的准确性。
结果:

如上图所e所示,从ID-Net中的基于∅_f7特征的l^2距离已经产生了很好的精度,其中StackNetPose的Accuracy最高。本文使用StackNetPose模型生成person re-identificationconfidence。尽管检测的bounding box不准确、背景干扰存在,body part maps仍然使网络能够准确的定位到行人。
4 Pairwise Potentials
目标函数定义为:c_e=-<θ_γ,f^((e))>,本节中介绍基于三个信息源的f^((e)),三个信息源分别是ST(spatio-temporalrelations),DM(dense correspondencematching),Re-ID(person re-identification confidence)。
ST:给定两个检测v,w,他们的时空信息为(x,y,t),高度为h,它们的相似度计算方式为:

其中,
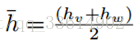
这种相似度计算方式只考虑图像边界框的信息,没有考虑图像的内容信息。
DM:给定连个检测v,w,每个检测都有一个匹配的关键点k。定义两个检测的并集为MU=|M_v∪M_w |,交集为MI=|M_v∩M_w |,然后两个检测间的成对特征定义为f_dm=MI ⁄ MU。
Re-ID:随着时间距离的增加,DM特征的性能会急剧下降,但Re-ID的性能是健壮的。本文中最终的配对信息f^((e))定义为: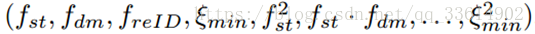
4.1 实验分析
本节分析ST,DM,Re-ID,Comb特征在不同时间距离下,在行人重识别的准确度方面的性能。

如上图所示,DM特征在10帧时拥有良好的精度,但时间距离增加时其性能连续下降。时间距离从1帧增加到200帧,组合特征一直保持着很高的精度。基于这样的实验结果,本文的跟踪实验中使用了组合特征。
5 跟踪实验和结果
本文的跟踪实验会与以前的基于的MOT16 Benchmark的实验在性能上做比较。测试集包含了7个序列,其中相机运动、相机角度和成像条件都有很大的差异。
为了分析跟踪模型,使用训练集中的MOT16-02和MOT16-11作为验证序列。在MOT16-02上训练的模型参数用于MOT16-11,反之亦然。为了从MP或LMP生成的簇中获得最终轨迹,使用[21]中的代码,根据属于同一簇的检测来估计平滑轨迹。当由于遮挡而在时间上存在差距时,我们沿着估计的轨迹填写缺失的检测结果。实验中,不考虑任何小于5的聚类。
评估指标。 遵循standard CLEARMOT指标来评估多人跟踪性能。MOTA:(它结合了identify switches(ID),false positive(FP)和false negatives(FN),MOTP:mostly tracked(MT),mostly lost(ML)和fragmentation(FM)。
5.1 Lifted edges和Regularedges
LMP图中有两种边,regular edges和lifted edges。regular edges用于图的分解/聚类;lifted edges引入长距离的信息,这些信息包含哪些结点应该被joint/cut,当然它们不会修改可行的解集。
比如:如图4所示,即使超过50帧,实验中的成对相似度测量的准确度仍高于90%。但是,如果我们直接用regular edges来编码它们,我们有10%的机会做出false joint,这样的错误将直接产生更长的错误tracks。如果使用lifted edges来缓冲一下,那么最终在连接这些结点前要通过regular edges的验证。验证不存在这样的路径,就不能joint两结点。
简言之,对于MP,所有小于δ_max的边都是regular edges。对于LMP,设置一个δ,边的时间距离小于δ时为regular edges,反之则为lifted edges。lifted edges需要经过regular edges验证才能最终决定结点的joint/cut。

上图时MP和LMP的对比,显然LMP的MOTA更高。
5.2 在MOT16基准上的测试结果

上表展示了本文提出的LMP方法与其他方法在各种性能指标上的对比。