结构化机器学习项目——机器学习策略(2)
一、误差分析
1.性能上限:优化模型中的某个性能所减少的最大的误差。

2.并行评估。对比多种导致误差的原因,通过分析错误标记的例子,统计假阳性(False positives)和假阴性(False nagatives)其在错误识别集中所占的比例,决定最终可选择的优化手段,同时在分析的过程中还可能受到启发发现新的问题类型。这种快速统计的过程可以经常做,只需要几个小时就可以帮助我们分析出高优先级的任务,并了解每种手段对性能提升有多大的空间。
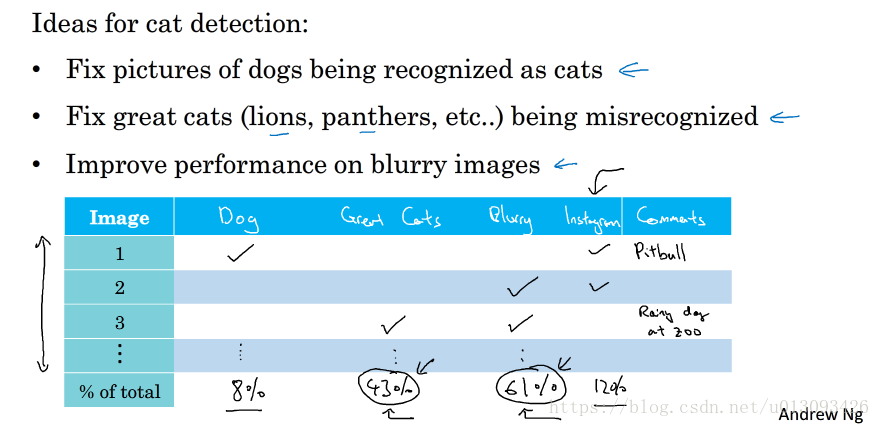
二、清除错误标记的数据
1.标签错误的影响
(1)随机误差:深度学习算法对于随机误差具有很好的鲁棒性,只要训练集足够大错误标签可不做处理,当然修正也是有好处的但是不要花费过多的时间。
(2)系统性误差:比如数据工程师一直把白色小狗标记成猫,那就会影响分类效果。
2.错误标签数据的处理:如果标签错误严重影响了在开发测试集上评估算法的能力,那么就需要处理这种标签错误的数据;但是如果错误标签数据没有严重影响到开发集评估cost偏差的能力,则不需处理。
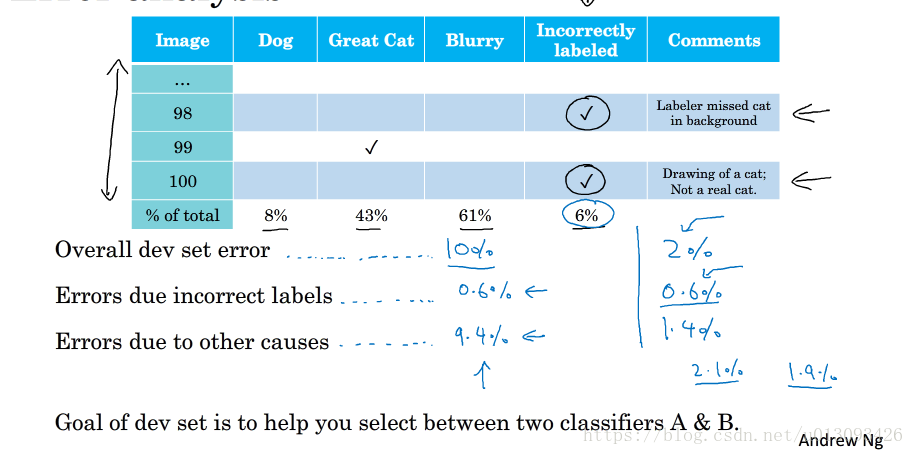
3.修正开发测试集中的错误样本
注意:(1)以相同的方式处理开发集和测试集,以保障他们有相同的分布;(2)和(3)可不做处理。

3.关于深度学习训练过程的误解:通常机器学习工程师在描述自己训练模型时习惯说“我只是把数据喂给模型而已”,在训练过程中我们确实少有人工干预,但是在训练实际应用的过程中,通常需要更多的人工误差分析和人类见解来构架这些系统;其次很多工程师和研究人员不愿花时间查看错误数据,但是达叔极力推荐按照本节所讲的表格去分析这些原因,对决定优先处理哪个问题极有帮助。
三、快速搭建你的第一个系统然后不断迭代
1.搭建深度学习算法的开始策略:(1)先快速构建一个初始的系统,也许这个系统有很多问题,但是随后我们可以通过分析偏差/方差分析和误差分析来选择下一步的优化方向;(2)构造一种已有系统,可多借鉴该领域的学术论文,实现其中的一个算法,然后进行优化。

2.在需要把深度学习算法应用到某个应用程序时,主要目标是如何构建一个能用的系统,而不是发明一个新的深度学习算法。
四、尝试在不同的划分策略上训练和测试
1.当构建模型的数据与用户应用数据不同分布时该如何处理:(1)将两个数据集合并,随机打乱后分配到train/dev/test集,但是这样划分形成的dev/test集中有很大比例是来自模型数据,这种dev/test集的分布不是我们真正关心的分布(因为dev/test集是用来目标的),因此这种处理方式不推荐使用;(2)利用用户应用数据作为dev/test集,多余出的数据划分到train集中(此时瞄准的目标就是要处理的目标),这种处理的方式最大的问题是train集与dev/test集不同分布,但是从长期来说能给系统带来更好的性能。
五、不匹配数据划分的偏差和方差
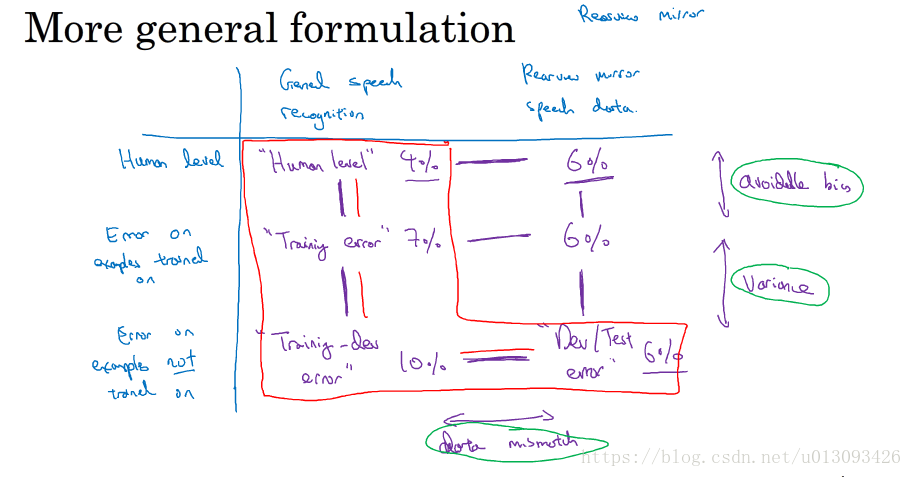
1.当train集与dev/test集不同分布时,偏差/方差分析法将不能直接作为评判的标准。此时我们需要构建一个新的子集train-dev集;这个子集来源于训练集,但不用来训练网络;然后根据train集和train-dev集的误差来分析。

2.train集与dev/test集不同分布时的偏差/方差分析法

3.通用规则:
六、定位数据不匹配
1.数据不匹配问题没有一个系统的解决方案,但是我们可以(1)手动进行误差分析比较方差和偏差以更好地理解训练集和开发/测试集的区别;(2)使训练数据与开发/测试集接近或者收集更多与开发/测试集相似的数据(人工数据合成)。

在人工数据合成时需要注意一个问题,如果合成的数据只占整体的很小一部分,那么神经网络可能会对这部分数据过拟合。
七、迁移学习
1.定义:把在A深度学习任务中建立起的神经网络应用到B学习任务中。
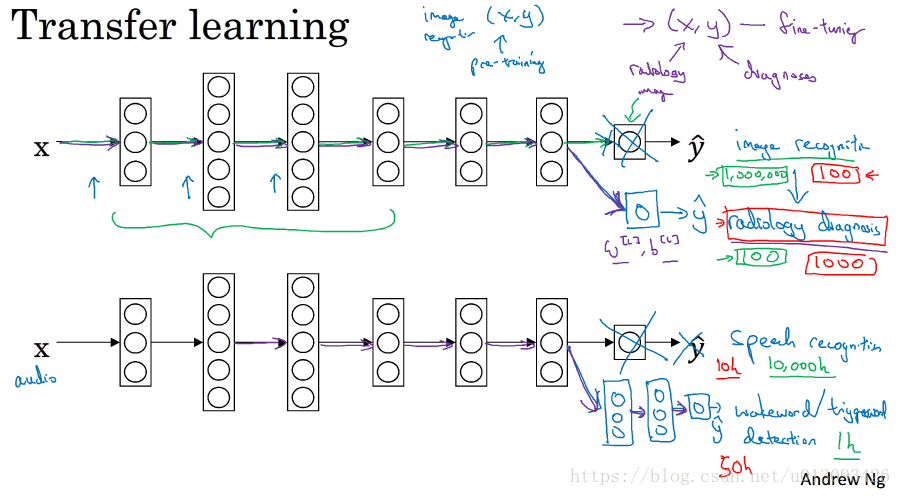
2.迁移学习什么时候是有意义的?
迁移来源问题(A)有很多数据,但迁移目标问题(B)没有那么多数据。比如在图像识别任务中有很多大量的数据(比如100W条),那么神经网络的前面几层可以学习到很多有用的低层次特征,而在放射影像识别中可能只有少量数据(比如100张图片),所以在图像识别训练中学到的很多知识(主要是低层次特征)可以迁移,以帮助增强放射影像识别任务的性能,如果这个过程是反过来的,那么就没有什么意义了

八、多任务学习
1.应用场景:比如在自动驾驶的学习中,对于路况的识别包括:信号灯、路标、车辆、行人等等,这是一个典型的多任务学习。在这种学习任务中,由于一个样本可能包含多种标签,我们有多个方案进行学习(1)建立一个神经网络,对多个标签进行学习,(2)建立多个网络对标签进行学习,其中神经网络的一些早期特征可共用。但是通常训练一个网络做多件事情,比建立多个网络分别做一个事情,性能要好很多。
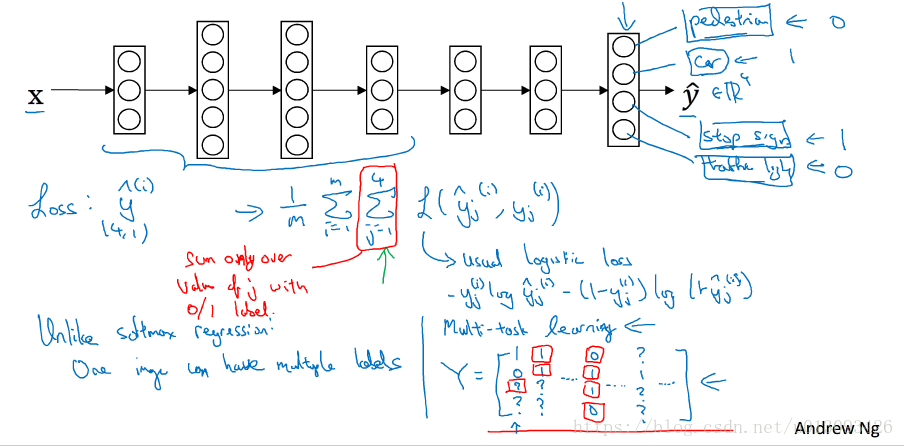
2.多任务学习何时有意义?
- 如果训练的的一组任务可以共用 低层次特征,比如无人驾驶需同时识别交通灯、汽车、行人等,这些事物时有相似特征的
- (非绝对)每个任务的任务量比较接近
- 能够建立一个足够大的神经网络来在所有任务上去的好的效果,也就是说当我们能够搭建起一个足够大的神经网络来实现多任务学习时,那这个大的多任务的神经网络所能达到的性能肯定优于针对每一个任务搭建一个神经网络所能达到的性能。

3.能够使用多任务学习的场合通常低于使用迁移学习,通常如果一个任务中的数据很少,我们可以尝试找到一个类似任务且有大量数据的任务进行迁移学习,但只有在计算机视觉-物体检测中会用到多任务学习
九、端到端深度学习
1.什么是端到端深度学习(end-to-end Deep Learning)
以前一些数据处理系统或者学习系统,需要多个阶段的处理,而端到端深度学习是忽略这些阶段用单个神经网络来代替。这样很多研究者花费多年心血细化的流程或者称中间件就要被神经网络所代替,因为深度学习网络只关系输入和输出,这种方法虽然让一部分人难以接受,但这是目前互联网时代的一个趋势:减少中间环节。不过端到端深度学习有一个挑战就是需要大量的数据,在早期的流水线处理模式对于少量数据的处理非常有效果,但是在大数据时代,深度学习表现出的能力是爆炸式的,这是早期处理系统不可比拟的。
2.流程化学习系统和端到端深度学习系统的应用分析
(1)使用流程化学习的场景
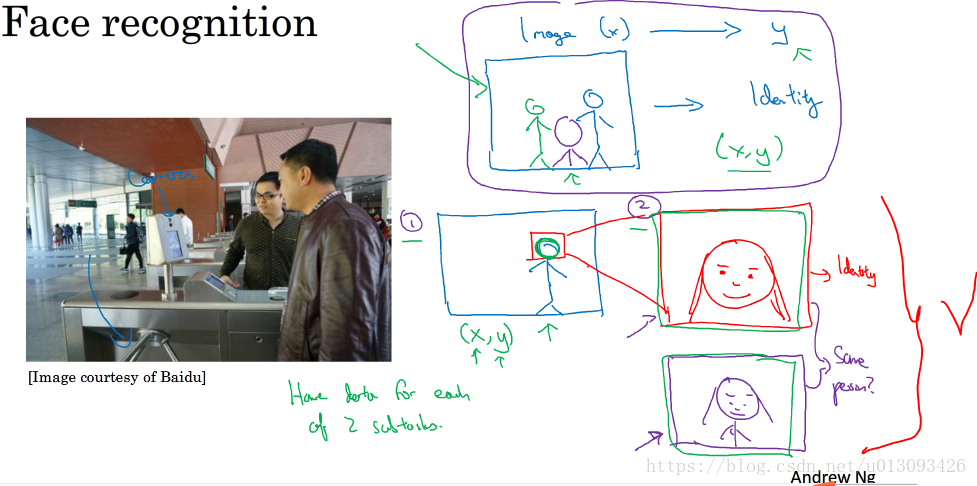
人脸识别:端到端深度学习并非万能,不如在人脸识别中,直接使用深度学习识别摄像机拍下的照片的效率比先定位照片脸部后识别面部的效率要低很多,原因有2:
- 在两步法中,每个问题相对简单很多
- 第二子任务中使用的数据都很大,在目前某些人脸识别项目中可能有数亿张图片
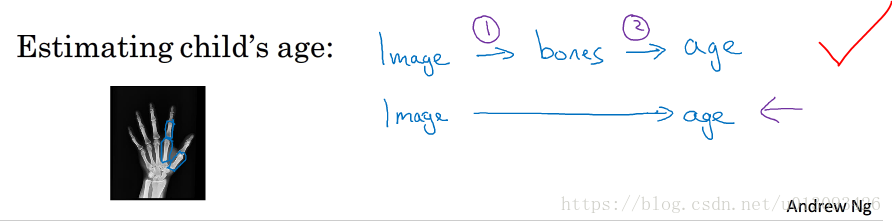
儿童骨龄判断
由于没有足够多的X射线与儿童年龄对应的数据,因此在目前仍然只能使用流程化学习的方法
(2)使用端到端深度学习的场景
机器翻译:今天机器翻译由于有大量的数据,如英法词典,可直接使用端到端深度学习一步到位的进行处理,其效率比分步处理高很多。

十、何时使用端到端深度学习
1.端到端深度学习的优点
(1)让数据说话。在数据足够过的时候我们使用深度学习直接从X映射到Y,这样神经网络可以捕获数据中的各种统计信息,而不是被迫引入人的主观成见,比如在早期的语音识别任务中,有一个音位的概念,这正是人类学家造出来的一个成见,而让学习系统被迫学习这个音位概念明显不如让算法自主的学习那些真正有用的特征。
(2)所需的手工设计的组件更少。可以简化设计流程,不需手工去设计功能或者中间件的表示形式
2.端到端深度学习的缺点
(1)需要大量的数据。
(2)可能排除了有用的手工设计组件。在没有足够的数据时,学习算法就没法从很小的数据集获得洞察力,此时手工设计组件可以把人类知识直接投入到算法中。总之学习算法的输入有两个来源,一个是数据,另一个就是手工设计的东西(功能、组件、其他)
3.应用端到端深度学习
关键点:是否有充足的数据习得一个具有必要复杂度(complexity needed)的x/y映射。