吴恩达深度学习第二门课第一周总结
先上目录:

从目录可以看到第一周主要解决了两个问题:过拟合,预防梯度消失/梯度爆炸。现在分别来讨论并进行代码实现。
一、梯度消失/爆炸及解决办法
在训练神经网络时,有时候会遇到导数或坡度(dW,db)变得特别大或特别小,即我们说的梯度爆炸或梯度消失,结果使得梯度下降算法花费更长的时间甚至训练失败。为了避免产生这种情况,可以采用权重初始化的方法,使得W既不会比1大很多,也不会比1小很多。
在之前的课程中对权重矩阵W的初始化我们通常会使用np.random.randn()方法,该方法是从均值为0的单位标准正态分布进行取样,但随着对神经网络中的某一层输入量的增大,在输出数据的分布中,方差也会随之增大,于是就有了改进的权重初始化方法,即通过将权重向量按输入的平方根进行缩放,从而将每个神经元的输出方差标准化为1,以保证网络中所有的神经元最初的分布大致相同,并在经验上提高了收敛速度。
如果激活函数是tanh函数,公式为:,这被称为Xavier初始化;
如果激活函数是relu函数,公式为:,这被称为Xavier初始化,
def init_parameters(layer_dims,initialization):
np.random.seed(3)
parameters = {}
if initialization=='zeros':
for i in range(1,len(layer_dims)):
parameters['W'+str(i)] = np.zeros((layer_dims[i],layer_dims[i-1]))
parameters['b'+str(i)] = np.zeros((layer_dims[i],1))
elif initialization=='random':
for i in range(1,len(layer_dims)):
parameters['W'+str(i)] = np.random.randn(layer_dims[i],layer_dims[i-1])
parameters['b'+str(i)] = np.zeros((layer_dims[i],1))
elif initialization=='he': #这是由He等人在所写的Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification论文中得到的结论
for i in range(1,len(layer_dims)):
parameters['W'+str(i)] = np.random.randn(layer_dims[i],layer_dims[i-1]) * np.sqrt(2/layer_dims[i-1])
parameters['b'+str(i)] = np.zeros((layer_dims[i],1))
else:
print("错误的初始化参数!程序退出")
exit()
assert(parameters['W'+str(i)].shape == (layer_dims[i],layer_dims[i-1]))
assert(parameters['b'+str(i)].shape == (layer_dims[i],1))
return parameters
1.layer_dims = [train_X.shape[0],10,10,1],learning_rate=0.5
- initialization=‘zeros’
 图1 cost值变化曲线 图1 cost值变化曲线
|
 图2 训练结果 图2 训练结果
|
- initialization=‘random’
 图1 cost变化曲线 图1 cost变化曲线
|
 图2 训练结果 图2 训练结果
|
- initialization=‘he’
 图1 cost变化曲线 图1 cost变化曲线
|
 图2 训练结果 图2 训练结果
|
2.layer_dims = [train_X.shape[0],100,100,1],learning_rate=0.5
- initialization=‘zeros’
|
图1 cost值变化曲线
|
图2 训练结果
|
- initialization=‘random’
 图1 cost变化曲线 图1 cost变化曲线
|
 图2 训练结果 图2 训练结果
|
- initialization=‘he’
 图1 cost变化曲线 图1 cost变化曲线
|
 图2 训练结果 图2 训练结果
|
可以看到,是否乘np.sqrt(2/layer_dims[n])这一修正项主要影响的是初始cost值,当网络各层神经元数目较少时,乘不乘这一项对最后的效果影响较小,随着神经元数目增长,不加修正项的初始cost值渐增,其训练结果的非对称性也越来越明显,而加了修正项的随着神经元数目增多,最后训练结果并不会受到特别大的影响。
二、正则化方法
这里首先要理解一个概念,就是机器学习中的偏差和方差。根据吴恩达老师的讲解,偏差是针对训练集的误差大小,方差则是针对训练集和测试集的误差大小比较。如图显示的为同一训练集:
总结一下:
训练集准确率低—高偏差
评估训练集性能,如果偏差太高,可能需要尝试更换新的网络
训练集准确率很高,但测试集准确率偏低
一是扩大自己的数据集,二是正则化
啦啦啦,到我们的重点啦!如何通过正则化解决过拟合的问题?以逻辑回归为例。
1.L1/L2正则化
正则化就是在成本函数J中再加上正则化项,常用的有两种:L1正则化和L2正则化
-
L1正则化
其中:
-
L2正则化
其中:
关于L1和L2的选择,这里引用吴恩达老师的一段话:
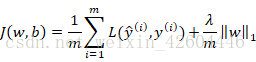
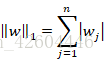
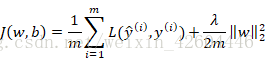
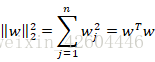
如果用的是L1正则化,W最终会是稀疏的,也就是说W向量中有很多0,有人说这样有利于压缩模型,因为集合中参数均为0,存储模型所占用的内存更少。实际上,虽然L1正则化使模型变得稀疏,却没有降低太多存储内存,所以我认为这并不是L1正则化的目的,至少不是为了压缩模型,人们在训练网络时,越来越倾向于使用L2正则化。
在神经网络的成本函数中加入正则项:
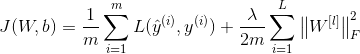
因为W是一个 n [ l ] × n [ l − 1 ] n^{[l]}\times n^{[l-1]} n[l]×n[l−1]的矩阵, n [ l ] n^{[l]} n[l]表示l层神经元的数目, n [ l − 1 ] n^{[l-1]} n[l−1]表示l-1层神经元的数目,故:
∑ i = 1 L ∥ W [ l ] ∥ F 2 = ∑ i = 1 n [ l ] ∑ j = 1 n [ l − 1 ] ( w i j [ l ] ) 2 \sum_{i=1}^{L}\left \| W^{[l]} \right \|_{F}^{2}=\sum_{i=1}^{n^{[l]}}\sum_{j=1}^{n^{[l-1]}}(w_{ij}^{[l]})^2 ∑i=1L∥∥W[l]∥∥F2=∑i=1n[l]∑j=1n[l−1](wij[l])2
即表示一个矩阵中所有元素的和。当使用该范数实现梯度下降,在原先结果的基础上,需要加上正则项对w求偏导后的结果,即
d W [ l ] = ∂ L ∂ W [ l ] + λ m W [ l ] dW^{[l]}=\frac{\partial L}{\partial W^{[l]}}+\frac{\lambda }{m}W^{[l]} dW[l]=∂W[l]∂L+mλW[l]
权重更新:
W [ l ] = W [ l ] − α d W [ l ] = W [ l ] − α ( ∂ L ∂ W [ l ] + λ m W [ l ] ) = ( 1 − α λ m ) W [ l ] − α d W [ l ] W^{[l]}=W^{[l]}-\alpha dW^{[l]}=W^{[l]}-\alpha(\frac{\partial L}{\partial W^{[l]}}+\frac{\lambda }{m}W^{[l]})=(1-\frac{\alpha \lambda }{m})W^{[l]}-\alpha dW^{[l]} W[l]=W[l]−αdW[l]=W[l]−α(∂W[l]∂L+mλW[l])=(1−mαλ)W[l]−αdW[l]
从上式可以看出,正则化试图让 W [ l ] W^{[l]} W[l]乘以一个小于1的权重系数,使其变得更小,因此L2正则化也被称为“权重衰减”。具体正则化为何有利于预防过拟合,可参考第二门课第一周的1.5节(参考链接:http://www.ai-start.com/dl2017/html/lesson2-week1.html#header-n89)。
下面我们来看一下用代码如何实现,效果怎么样?
还是以二分类为例,为了让效果更明显,这里换成另一个数据集(参考链接:https://blog.csdn.net/weixin_42604446/article/details/81369224)
 图1 训练集 图1 训练集
|
 图2 测试集 图2 测试集
|
参考代码:
def datagen(m,lambd,is_plot):
np.random.seed(1)
N = int(m/2) #分为两类
D = 2 #样本的特征数或维度
X = np.zeros((m,D)) #初始化样本坐标
Y = np.zeros((m,1)) #初始化样本标签
for j in range(2):
ix = range(N*j,N*(j+1))
t = np.random.randn(N)*lambd
r = np.random.randn(N)*lambd
if j==0:
X[ix] = np.c_[t-0.4, r-0.4]
else:
X[ix] = np.c_[t+0.4, r+0.4]
Y[ix] = j #red or blue
if is_plot:
fig = plt.figure()
plt.rcParams['figure.figsize']=(7.0,4.0)
plt.rcParams['image.interpolation']='nearset'
plt.rcParams['image.cmap']='gray'
plt.title('training dataset')
plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral)
plt.show()
return X.T,Y.T
加入正则化后的更新代码:
- 计算cost
def compute_cost_with_regulation(A,Y,parameters,lambd):
m = Y.shape[1]
sum = 0.
cross_entropy_cost = compute_cost(A[len(A)-1],Y)
for i in range(len(A)):
sum += np.sum(np.square(parameters["W"+str(i+1)]))
L2_regularization_cost = lambd * sum / (2 * m)
cost = cross_entropy_cost + L2_regularization_cost
return cost
- 反向传播
def backward_propagation_with_regulation(X,Y,Z,A,W,lambd,derivate_function):
l = len(W)
dZ = list(range(l))
dA = list(range(l))
dW = list(range(l))
db = list(range(l))
m = Y.shape[1]
grads = {}
dZ[l-1] = A[l-1] - Y
for i in range(l-1,-1,-1):
if i>0:
dW[i] = (1/m)*np.dot(dZ[i],A[i-1].T) + ((lambd * W[i] / m))
else:
dW[i] = (1/m)*np.dot(dZ[i],X.T) + ((lambd * W[i] / m))
db[i] = (1/m)*np.sum(dZ[i],axis=1,keepdims=True)
dA[i-1] = np.dot(W[i].T,dZ[i])
dZ[i-1] = np.multiply(dA[i-1],np.int64(A[i-1]>0))
for i in range(len(dW)):
grads["dW"+str(i+1)] = dW[i]
grads["db"+str(i+1)] = db[i]
return grads
接下来看看实验效果:
- 未加入正则化
 图1 训练集分类结果 图1 训练集分类结果
|
 图2 测试集分类结果 图2 测试集分类结果
|
- 加入正则化, λ = 0.5 \lambda =0.5 λ=0.5
 图1 训练集分类结果 图1 训练集分类结果
|
 图2 测试集分类结果 图2 测试集分类结果
|
2.dropout正则化
它的原理就是在神经网络每一层设置消除节点的概率,然后dropout会遍历网络的每一层,并以设置的概率随机保留和消除相应的节点,最后得到一个节点更少,规模更小的网络。因为每个节点被消除的可能性相同,故避免了神经网络依赖于某些特定的节点,达到降低方差,压缩权重,预防过拟合的作用。
|
|
|
实施dropout最常用的方法是inverted dropout(反向随机失活),该方法需要为网络的每一层设置失活概率,用keep-prob表示,比如keep-prob=0.8,那么消除任意一个隐藏单元的概率为0.2。以一个三层网络为例:
首先定义一个向量d,若对网络的第三层实施dropout,则:
d 3 = n p . r a n d o m . r a n d ( A [ 3 ] . s h a p e [ 0 ] , A [ 3 ] . s h a p e [ 1 ] ) < k e e p − p r o b d3=np.random.rand(A^{[3]}.shape[0],A^{[3]}.shape[1])<keep-prob d3=np.random.rand(A[3].shape[0],A[3].shape[1])<keep−prob
A [ 3 ] = n p . m u l t i p l y ( A [ 3 ] , d 3 ) / k e e p − p r o b A^{[3]}=np.multiply(A^{[3]},d3)/keep-prob A[3]=np.multiply(A[3],d3)/keep−prob
第一行公式得到的d3为布尔型数组,值为True或False,<keep-prob即是把小于keep-prob的置为True,大于keep-prob的置为False,第二行公式则是消除相应的节点,除以keep-prob则是为了弥补消除的那一部分,使得 A [ 3 ] A^{[3]} A[3] 的期望值保持不变。
下面来看用代码如何实现,以及实验效果(还是以L2正则化中的训练集为例):
对最后一层不实施dropout,前向传播与反向传播的代码分别如下:
- 前向传播
def forward_propagation_with_dropout(X,parameters,activate_fun,keep_prob):
#retrieve parameters
W = []
b = []
for i in range(1,len(parameters)//2+1):
W.append(parameters["W"+str(i)])
b.append(parameters["b"+str(i)])
#compute forward_propagation
Z = []
A = []
D = []
for i in range(len(W)):
if i==0:
sZ = np.dot(W[i],X)+b[i]
else:
sZ = np.dot(W[i],A[i-1])+b[i]
sA = activate_fun[i](sZ)
if i<(len(W)-1):
sD = np.random.rand(sA.shape[0],sA.shape[1]) < keep_prob
sA = np.multiply(sA,sD) / keep_prob
Z.append(sZ)
A.append(sA)
D.append(sD)
return Z,A,W,D
- 反向传播
def backward_propagation_with_dropout(X,Y,Z,A,W,D,keep_prob):
l = len(W)
dZ = list(range(l))
dA = list(range(l-1))
dW = list(range(l))
db = list(range(l))
m = Y.shape[1]
grads = {}
dZ[l-1] = A[l-1] - Y
for i in range(l-1,0,-1):
if i>0:
dW[i] = (1/m)*np.dot(dZ[i],A[i-1].T)
else:
dW[i] = (1/m)*np.dot(dZ[i],X.T)
db[i] = (1/m)*np.sum(dZ[i],axis=1,keepdims=True)
dA[i-1] = np.dot(W[i].T,dZ[i])*D[i-1]/keep_prob
dZ[i-1] = np.multiply(dA[i-1],np.int64(A[i-1]>0))
for i in range(len(dW)):
grads["dW"+str(i+1)] = dW[i]
grads["db"+str(i+1)] = db[i]
return grads
训练结果:
- 不实施dropout,即keep_prob=1
 图1 训练集分类结果 图1 训练集分类结果
|
 图2 测试集分类结果 图2 测试集分类结果
|
- 实施dropout,keep_prob=0.6
 图1 训练集分类结果 图1 训练集分类结果
|
 图2 测试集分类结果 图2 测试集分类结果
|
从上图可以看出,如果不实施dropout正则化,会出现过拟合的问题,而实施dropout后,过拟合基本被消除。
结束!!!
相关资源下载:https://download.csdn.net/download/weixin_42149550/11666926
************************************************************* 这里是分割线 *****************************************************************
附:
- 对第一门课第三周作业中的backward_propagation部分进行了更正
def backward_propagation_with_regulation(X,Y,Z,A,W,lambd):
l = len(W)
dZ = list(range(l))
dA = list(range(l-1)) #更正前为dA = list(range(l)),实际需要记录的dA不需要包括最后一层,因为代码直接算出了最后一层的dZ
dW = list(range(l))
db = list(range(l))
m = Y.shape[1]
grads = {}
dZ[l-1] = A[l-1] - Y
for i in range(l-1,0,-1): #更正前为 range(l-1,-1,-1),后面计算的dA,dZ的索引值包括i-1,如果为-1,最后dA的索引就有负数了,显然不行
if i>0:
dW[i] = (1/m)*np.dot(dZ[i],A[i-1].T) + ((lambd * W[i] / m))
else:
dW[i] = (1/m)*np.dot(dZ[i],X.T) + ((lambd * W[i] / m))
db[i] = (1/m)*np.sum(dZ[i],axis=1,keepdims=True)
dA[i-1] = np.dot(W[i].T,dZ[i])
dZ[i-1] = np.multiply(dA[i-1],np.int64(A[i-1]>0))
for i in range(len(dW)):
grads["dW"+str(i+1)] = dW[i]
grads["db"+str(i+1)] = db[i]
return grads
- 在Markdown编辑器中如何将多张图片并排放并居中?
<table>
<tr>
<td ><center><img src="https://img-blog.csdnimg.cn/20190904211338386.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjE0OTU1MA==,size_16,color_FFFFFF,t_70" width=480 >图1 训练集分类结果</center></td>
<td ><center><img src="https://img-blog.csdnimg.cn/2019090421135561.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjE0OTU1MA==,size_16,color_FFFFFF,t_70" width=480 >图2 测试集分类结果</center></td>
</tr>