结构化机器学习项目——机器学习策略(一)
一、为什么是机器学习(ML)策略

二、正交化
1.在深度学习中,需要调整的超参数非常多,而对于资深的深度学习专家而言,对于需要调整什么以达到什么效果是很明确的。
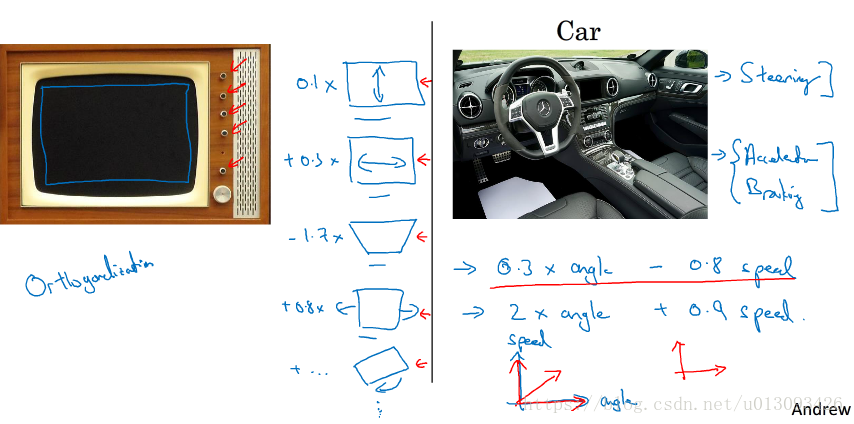
2.正交化的定义:对于某个由多个维度决定的变量,如果各维度之间可以单独调整而不影响其余维度,那么这些维度之间的关系称为正交化,下面以电视机调节和汽车操纵为例。
3.机器学习模型调整的“假设链”,在每一步上要有评估的指标和调整的“旋钮”
- 使cost函数能够很好的适应训练集(training set):bigger network,Adam
- 适应开发集(dev set):regularization、bigger training set
- 适应测试集(test set):bigger dev set
- 适应实际应用:bigger dev set,cost function

4.在训练机器学习模型时要有调节电视机的直觉,看到宽度、高度、色彩不好时要能够判断出需要调整那个按钮。
三、单实数评估指标
1.常用的单实数评估指标,这两个指标往往需要折中考虑。
- 查准率(Precision):在预测结果中,有多少样本被检测正确了
- 查全率(Recall):对于标签为真的样本,有多少被检测出来了
2.查准率与查全率需要折中考虑不便于评估,因此有学者提出了F1分数的评估,该指标P和R的某种均值展示,计算公式如下:
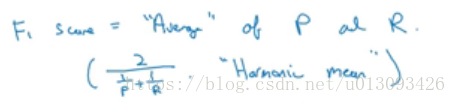
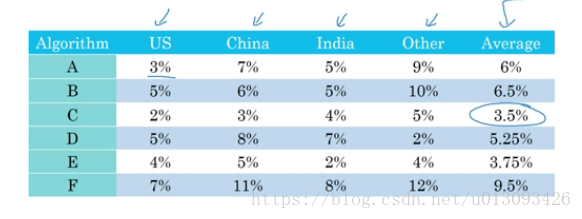
3.对于有多个测试集的项目,计算模型在各个样本集中的平均误差是选择最佳模型的较好的评估指标。
四、满足和优化指标
1.评估指标除了可以包含精确度指标外,还可以包含运行时间等指标。如果我们要求运行时间必须满足某一个值,那么我们在评估分类器时,可以将运行时间当作满足指标(satisficing metric),而精确度当作优化指标(optimizing metric)。从这个思路出发,如果在一个项目中分类器选择有N个指标(metrics),通常确定1个优化指标,其余N-1个作为满足指标。

2.trigger words
五、训练集、开发集、测试集的划分
1.开发集(dev set):development set 也称 hold out corss validation(保留交叉验证集)。开发集主要用来评估不同的思路,然后选择一个评估指标比较好的分类器然后不断迭代直到可以获得一个令人满意的cost值,然后在去测试集中测试。
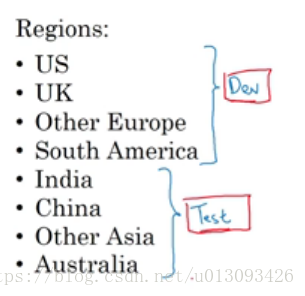
2.开发集与测试集划分的原则,假设我们有下图中的数据,我们在划分训练集和测试集的时候很容犯的错误是直接或随即的将一部分数据华为开发集一部分作为测试集,之所以说这种划分方法不对,是因为没有考虑数据分布,因为这个不同地区的数据很大程度上是满足不同的分布的。正确的做法是将这些数据先随即打乱,这样开发集和测试集中都有下面八个地区的数据,并且满足同分布。
六、开发集和测试集的大小选择
1.划分数据集的方法
数据量较小
- training set/ test set = 70/30
- training set / dev set /test set = 60/20/20
大数据时代(100万左右)
- training set / dev set /test set = 98/1/1
- 保证测试集能够在整个集合中有足够高的置信度
2.测试集的目的是测试cost偏差,因此只要开发集足够大,那么不设置测试集也是可以的。
七、何时更改开发集和目标
1.更改情景一:当评估指标无法衡量算法之间的优劣顺序时,此时需要改变评估指标或者开发集。
2.分类误差指标

当指标无法衡量算法之间的优劣顺序时,分类误差指标也需要进行调整
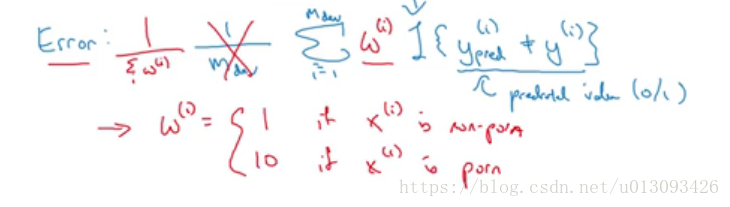
3.注意要将正交化的思路应用到选择指标和更改开发集这个步骤中,使二者尽量正交。

4.更改情景二:开发集与用户数据不满足同分布(例如:建立模型用的图片都是高清的而用户拍的照片画质很差)
5.总结:拥有了评价指标和开发集可以加快团队的迭代速度,即使选择的不好也可以在后期迭代过程中调整;切忌不要在没有评价指标和开发集时跑太久模型因为这大大减慢团队迭代的速度。
八、机器学习系统与人类表现的比较
1.与人类表现比较的原因:(1)机器学习算法的表现逐渐优于人类表现;(2)机器逐渐承担人类可处理的任务。
2.贝叶斯最有误差(bayers optimal error / bayersian error):机器学习性能的上限
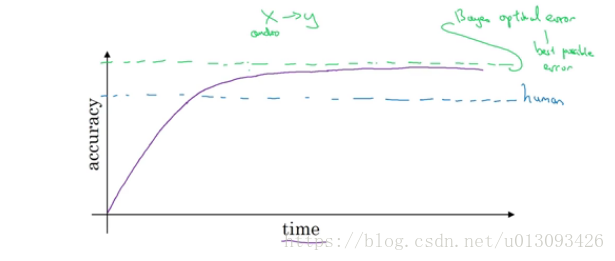
3.机器学习的表现在超过人类接近贝叶斯最有误差的过程中是非常缓慢的,一是因为人类表现已经离贝叶斯最有误差比较接近,原本没有太多的改善区间;二是改善性能的措施不在适用超过人类表现后的优化过程。
4.改善性能的措施(机器学习的表现在超过人类之前)

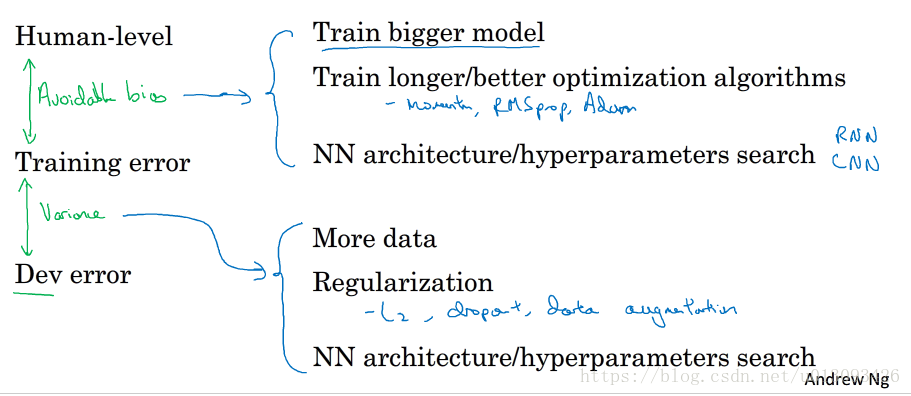
九、可避免偏差
1.人类表现在衡量机器学习性能中的作用(如在机器视觉中,由于人类非常擅长识别,因此可以用人类的表现作为贝叶斯最优误差,当然是在不过拟合的前提下)

2.可避免偏差(available bias):样本集的误差与贝叶斯误差(人类表现误差)之间的差值,也就是还可优化的区间。
十、理解人类水平表现(human-level performance)
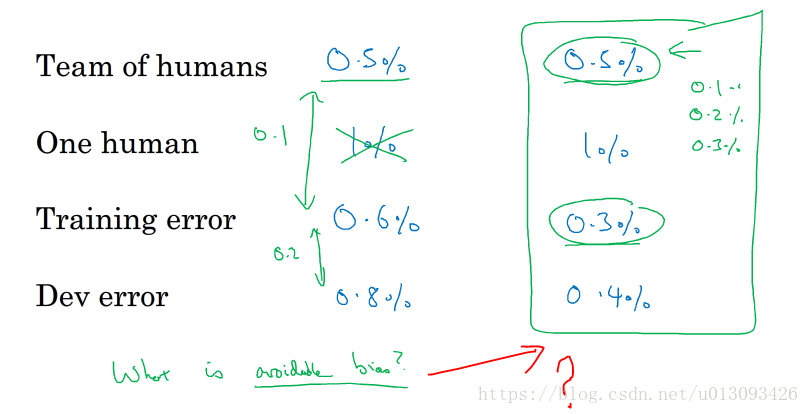
1.如何定义human-level performance?如下图不同能力的人产生的误差水平是不一样的,那么以谁为准呢?

其实在训练算法时,人类表现误差的选择是一个阶段性的问题,算法在训练集和开发集上的不同误差对人类表现误差的选择也会有所不同。

2.通过对人类表现误差的理解,在以后项目中我们应该形成一个概念:训练算法时不需再以0%作为贝叶斯误差。
十一、算法超越人类表现后如何优化
1.可以说在算法误差超越人类表现后,会很难找到优化的思路和方向
2.目前已经优化人类表现的领域:线上广告、产品推荐(书籍,电影)、物流预测(AB两地之间用时)、贷款额度。这四个案例的特点:(1)都是从结构化数据得来;(2)非自然感知(自然感知能力领域,机器学习想要超越人类还很难);(3)有大量数据(使得机器更有可能习得数据的分布规律)。
3.在自然感知方面有些已经赶超单个人类的表现:语音识别、计算机视觉、医疗(读脑电图、癌症诊断、放射图像分析)
十二、改善模型表现
1.监督学习中的两个前提假设(1)模型能很好的适应训练集;(2)在训练集中的表现能够推广到开发集和测试集。
2.总结:减小可避免偏差和方差的方法。