关键字:代价函数,梯度下降,学习速率,batch梯度下降法
话说这个梯度下降法我们的专业课数值线性代数是有的,突然发现数值线性代数果然是有用的啊
1、梯度下降法
算法(一个形象的说法:盲人下山)

注意点:所有的参数都要同时更新
1.1 代价函数
J为代价函数,吴恩达老师举例:平方差代价函数
如果想求代价函数J的最小值,可以采用梯度下降法
1.2 .学习速率
这里的参数alpha称为学习速率,为正数,控制每次的步长
alpha的大小需要控制,如果太大的话最后不会收敛甚至可能发散
alpha为常数:接近局部最优解时,不需要减小alpha,因为到达最优解时导数越来越趋近于0,此时alpha不动,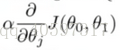
学习速率的选取:
可以画出迭代次数与代价函数的图像
1.良好情况下,代价函数会降低,最后趋向平稳,这个时候的alpha的选择就比较好。
2.但是如果alpha太大,那么图像就像这样


3.如果代价函数如下
 那么应该选择较小的alpha
那么应该选择较小的alpha
1.3 应用:不仅可以应用于线性回归,也可以应用于非线性回归模型。
2.线性回归模型
线性方程 和 平方和代价函数

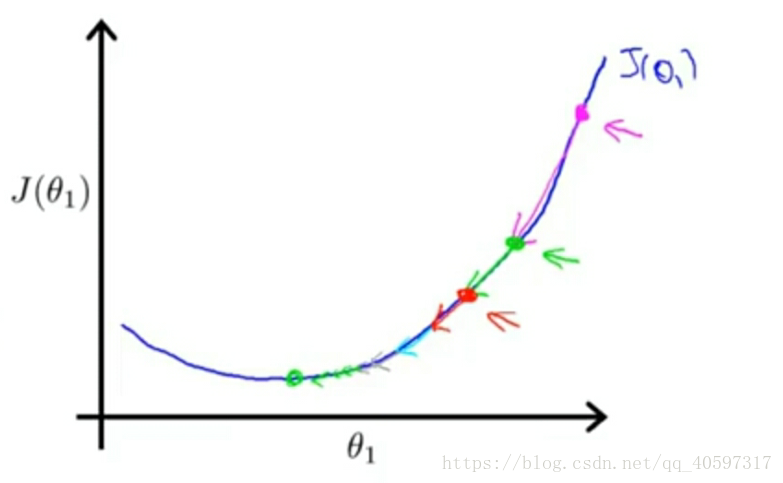
3、Batch梯度下降法
3.1 算法
线性回归模型化简后的梯度下降法如下,这里的J采用平方差代价函数
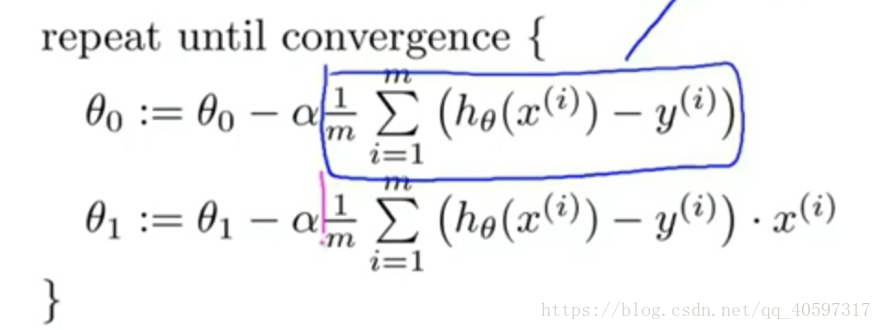
不断的更新参数
分析:
右边的图像一个等高线图,在同一圈上的参数对应的代价函数的值都一样的
右图实际上是一个3D图,第三维是代价函数J,在最里面的小圆点J是最小的,就像碗的碗底,这是一个凸函数,从碗底往上依次J变大,这个形状就像一个碗
左图的点是一些已知数据,要做的就是尽可能贴合他们,即使得J最小
蓝线为线性模型,包含参数seta1和seta2
目标:使得蓝线尽可能拟合数据
过程:通过seta1 seta2不断接近底部,代价函数达到最小,那么拟合的效果就达到最小,对应左边有一个最佳拟合直线
如下图为最终结果

3.2 总结
显然这个方法用到了所有的数据,因为J是根据所有的数据求来的,适用于较大的数据集
悬念:还可以用高等代数的正规划方程组的方法求得最佳参数,此时不需要遍历整个训练集的样本
4.正则化方程组(用于求得最佳参数)
这个方法可以一次性求得最佳参数,不需要经过迭代,是数值线性代数里面的直接法而不是迭代法。

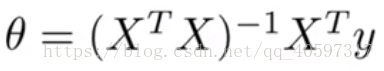
当特征小于10000时比较适合
这是观看吴恩达网易云机器学习系列做的笔记
图片来源于视频课件