我们的第一个机器学习算法——线性回归算法。有时我们把这个算法也称为Batch梯度下降算法,每一步下降都遍历了整个训练集的样本。
模型描述
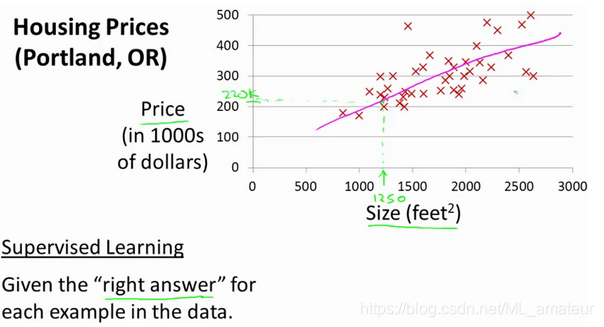
在监督学习中我们有一个数据集,这个数据集被称训练集。
假使我们回归问题的训练集(Training Set)如下表所示:

- 符号定义:
m表示训练样本的数量
x表示输入变量(或者特征)
y表示输出变量(预测的目标变量)
(x,y)表示一个训练样本
(x(i),y(i))表示第i个训练样本(i指的是索引,表示第i个训练样本)
h代表学习算法的解决方案或函数也称为假设(hypothesis)
- 监督学习算法的工作流程:

在房价预测的例子中,提供一个训练集,学习算法的任务是输出一个函数,通常用h表示。 h表示假设函数,作用是把房子的大小作为输入变量,房子的价格作为输出变量,h根据输入的x值来得出y值。因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
对于假设h我们可以用一条直线描述,用线性函数预测房价值:
代价函数
 我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距就是建模误差(modeling error)。
我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距就是建模误差(modeling error)。
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数,平方误差代价函数是解决回归问题最常用的手段。
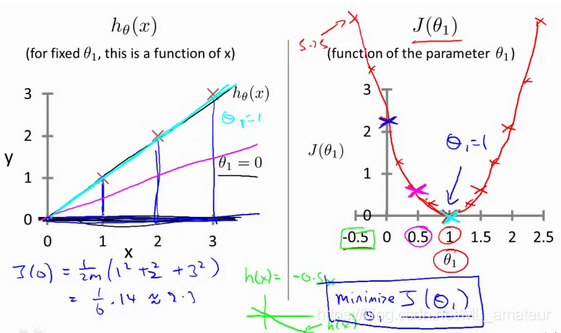
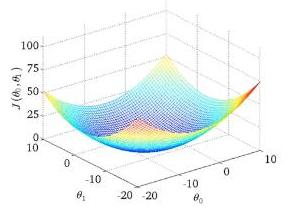
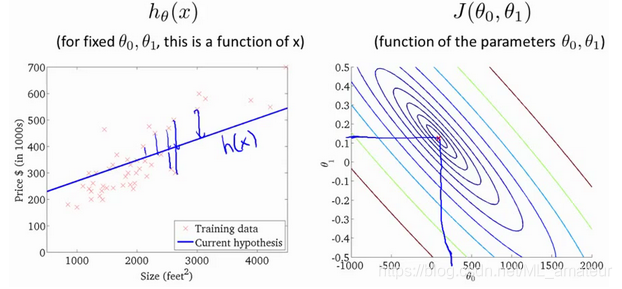
梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数J的最小值。梯度下降不仅被用在线性回归上,还被广泛应用于机器学习的众多领域。

- 符号定义
:=这个符号表示赋值运算符
α是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,用来控制梯度下降
- 关于学习率α
1.如果α(学习速率)太小,则梯度下降法会收敛的很慢;
2.如果α太大,则梯度下降法每次下降很快,可能会越过最小值,最终会导致无法收敛甚至发散。
3.如果你的参数已经处于局部最低点,那么梯度下降法更新其实什么都没做,它不会改变参数的值。这也解释了为什么即使学习速率α保持不变时,梯度下降也可以收敛到局部最低点。
线性回归的梯度下降
梯度下降和代价函数结合得到线性回归算法,它可以用直线模型来拟合数据。

对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:

将上面的结果应用到梯度下降算法中,就得到了线性回归的梯度下降算法:
