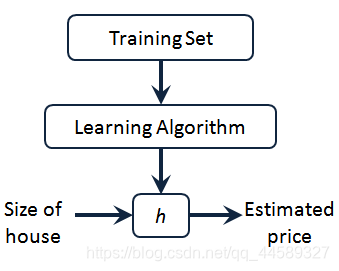
单变量线性回归
符号说明
m代表训练集中实例数据
x代表输入特征/输入变量
y代表目标变量/输出变量
(x,y)代表训练集中的实例
(xi,yi) 代表第
i个观测实例
h代表学习算法解决方案或函数
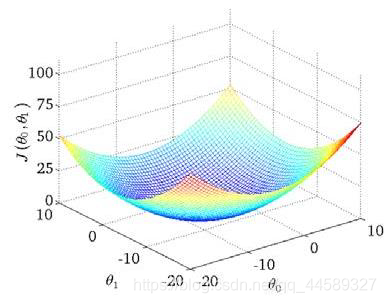
代价函数

代价函数为
J(θ0,θ1)=2m1i=1∑m(hθ(xi)−yi)2
直观理解如下:要确定出
θ0,
θ1及使得
minJ(θ0,θ1)
梯度下降法
θj:=θj−α∂θj∂J(θ)
对
θ赋值,使得代价函数按照梯度下降最快方向进行,一直迭代下去,其中
α为学习率
如果
α很小,需要迭代很多步才能到全局最小,如果很大会跳过局部最优导致无法收敛
梯度下降的线性回归
∂θj∂J(θ0,θ1)=∂θj∂2m1i=1∑m(hθ(xi)−yi)2
当
j=0时:
∂θ0∂J(θ0,θ1)=m1i=1∑m(hθ(xi)−yi)
当
j=1时:
∂θ1∂J(θ0,θ1)=m1i=1∑m((hθ(xi)−yi)xi)
因此有如下算法:
θ0:=θ0−am1i=1∑m(hθ(xi)−yi)θ1:=θ1−am1i=1∑m((hθ(xi)−yi)⋅xi)
对两个参数
θ0与
θ1进行更新,多维空间根据上述公式进行扩展即可。
总结
为什么要用梯度下降法,在进行数据量大的情况下,梯度下降法要比正规方程的方程更加适用