前言:
吴恩达第二章单变量线性回归笔记
模型描述:
字符表示:
m=数据集数量
x=input(自变量)
y=output(因变量)
给出一定量的数据集关于,构建出相应(x,y)的位置.根据算法得到相应的拟合函数(即下图蓝线)

代价函数:
Hypothesis(目标拟合函数):
Parameters(参数):
CostFunction(计算误差):
Goal(目标):
由 我们可以绘制出如下等高线图
三个坐标分别为

如何获得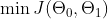 ? 梯度下降算法
? 梯度下降算法
重复以下步骤
repeat until convergence{
for(j=0 and j=1)
}
Correct Simultaneous update(正确的更新方式):
α:为learning rate,用来控制下降时的速率
应同时更新
根据高等数学下偏导数知识:
总结:
- 根据该算法,一步一步算出误差最小时的
和
,来得到理想的拟合函数。理想状态下当
取最小值时,误差时最小的,即当
和
两者为0的时候取到最小值。
- 由于该算法是一个个测试
- 若α太大,可能会导致离最低点越来越远。
- 若α太小,得到最低点用的时间可能会很长
