课程老师:吴恩达
课程视频:网易云课堂-吴恩达机器学习 (最原始版本在Coursera)
二、单变量线性回归
1. 模型描述
1.1. 训练集
在课程中,学习的第一个机器学习算法是线性回归(linear regression)。
课程开始还是以一个例子开头,介绍了什么是监督学习:给定一堆房子大小和售价的数据,让机器预测其它房子大小的售出价格。
课程还提到了有监督学习中会有训练集。还有一些与其相关的名词。
- training set:指用来训练机器的带有答案的数据集。如上述例子的房价数据。
- m:训练样本的数目
- x's :输入变量/输入特征
- y's :输出变量/目标变量
- (x,y):一个训练样本
- (x^(i), y^(i)):表示第i个训练样本

1.2. 监督学习的流程
我们向学习算法提供训练集(喂数据),例如房价数据。
学习算法的任务是输出一个假设函数。函数的作用是将房子的大小作为输入变量,尝试输出相应房子的预测y值。
假设函数:这个函数通常用h来表示。一般称为hypothesis。有时等式左侧简写为h(x)。以下是线性回归的假设函数。
\[ h_θ(x)=θ_0~+θ_1~x \]
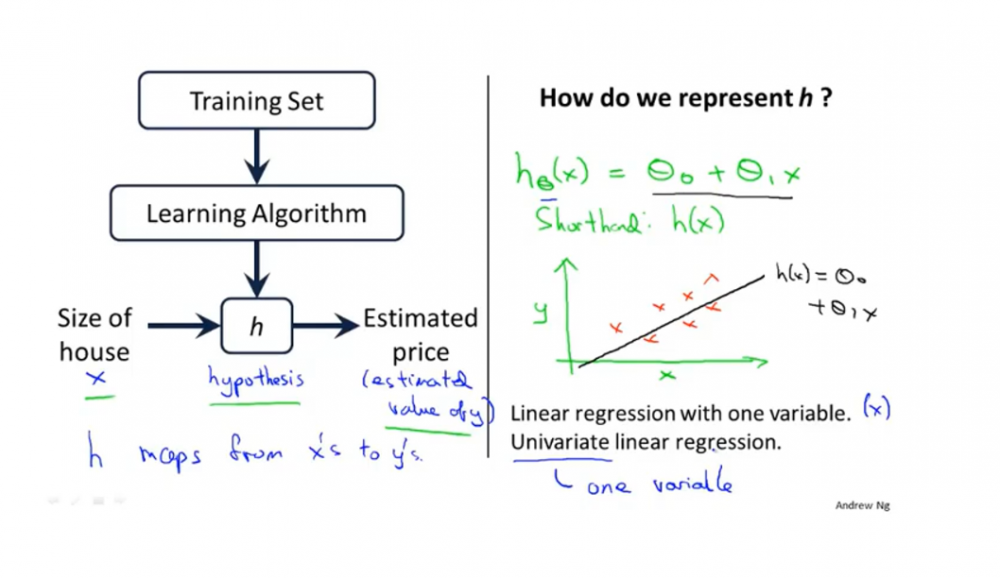
1.3. 线性回归模型
\[ h_θ(x)=θ_0+θ_1x \]
当我们的假设函数是线性函数时,如上图所示,上述模型可以叫做线性回归(linear regression),或者叫做一元回归函数,或者叫做单变量线性回归(univariate linear regression)。
2. 代价函数
2.1. 什么是代价函数
前面说了机器实际上说通过假设函数来预测其它数据的,故对于上述的线性回归模型,当选择不同的$ θ_0 $ 和$ θ_1 $时,模型效果肯定是不一样的。如下图所示,三种不同参数的线性效果不一样。
$ θ_0 $ $ θ_1 $ 也被叫做参数。
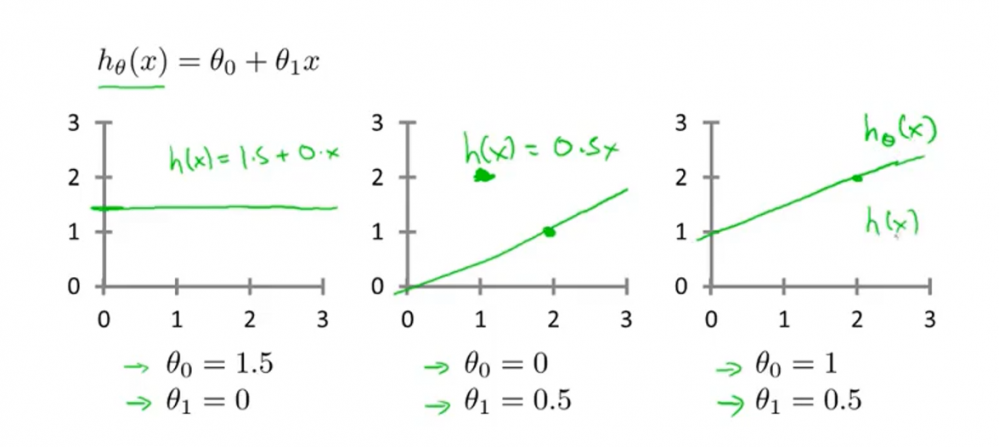
故现在的问题是如何去决定这两个参数,使得将训练集\(x^i\)输入该函数后,函数输出的y值能与训练集\(y^i\) 的值尽量接近。这里用到了均方误差的作为判断标准,该值越小,说明该参数能让假设函数越接近正确结果。公式如下:
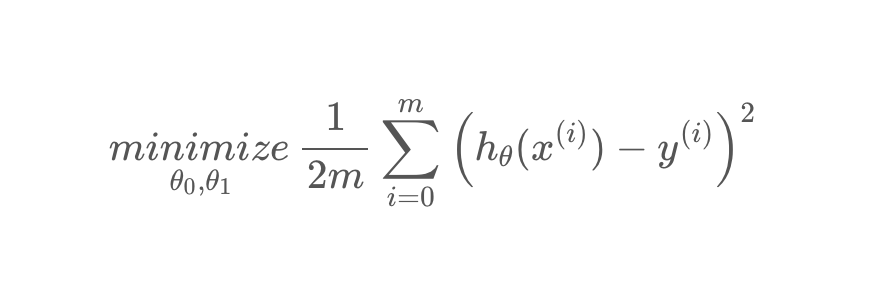
m:训练集数
1/2:为了后面方便计算。
更准确的写法如下,其实这就是代价函数:
视频中老师并没有提及代价函数的具体定义,但我认为代价函数可以理解为一个求出代入某参数的假设函数的误差性的函数。也就是其作用是算出在该参数的作用下,假设函数预测的准确程度。
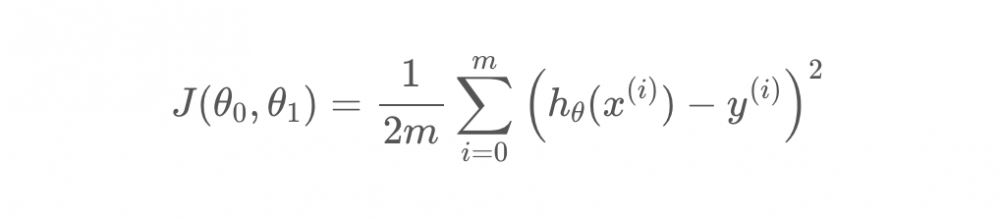
而我们的目标就是找到某参数,使代价函数最小:
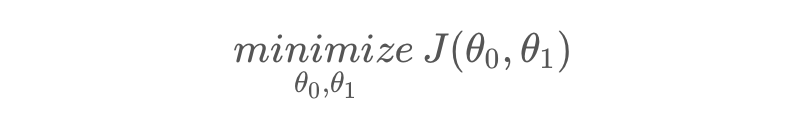
2.2. 代价函数和假设函数
以下小节内容仍基于线性模型讨论。
- 假设函数是关于两个参数的函数,其作用得到输入值x对应的预测值y。
- 代价函数是也是关于两个参数的函数,其作用是对代入两个具体参数值的假设函数进行判断,判断假设函数的输出值偏离正确值的程度。我们最后一般会选择使代价函数最小对应的参数值
2.2.1. 例子
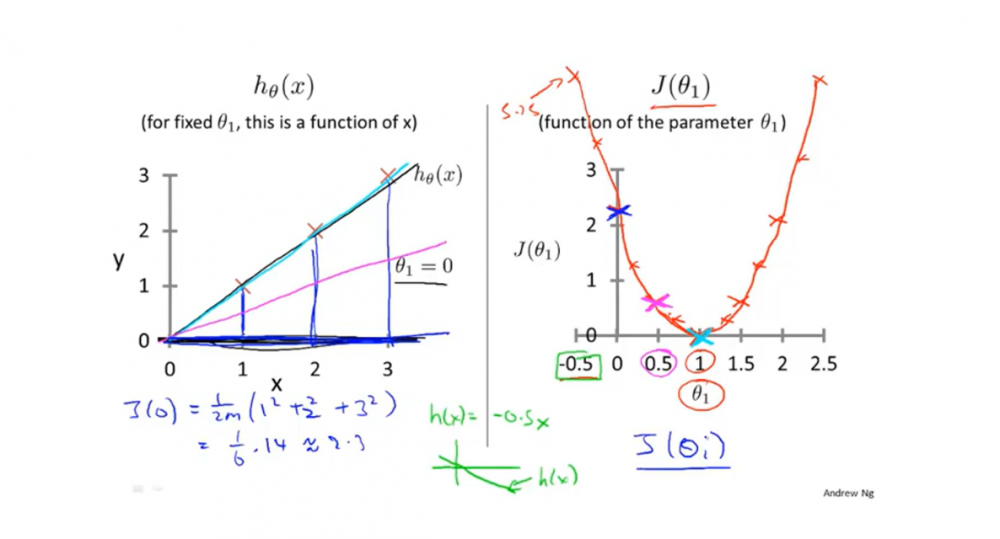
以下例子是基于\(h_θ(x)=θ_0+θ_1x\)假设函数,并且为了更容易让读者明白其区别。老师使\(θ_0 = 0\),简化了函数。
从下面例子可以看出,当\(θ_1\)取不同值时,可以得出不同的代价函数值,而代价函数值最小时(这里例子最小是0),假设函数预测值误差最小。
未完待续。。。学习中
本文博客:http://www.cnblogs.com/toulanboy/
笔记参考