
一、概括
针对小目标检测的综述,分析难点、梳理四大类方法、收集数据集、讨论未来研究方向。
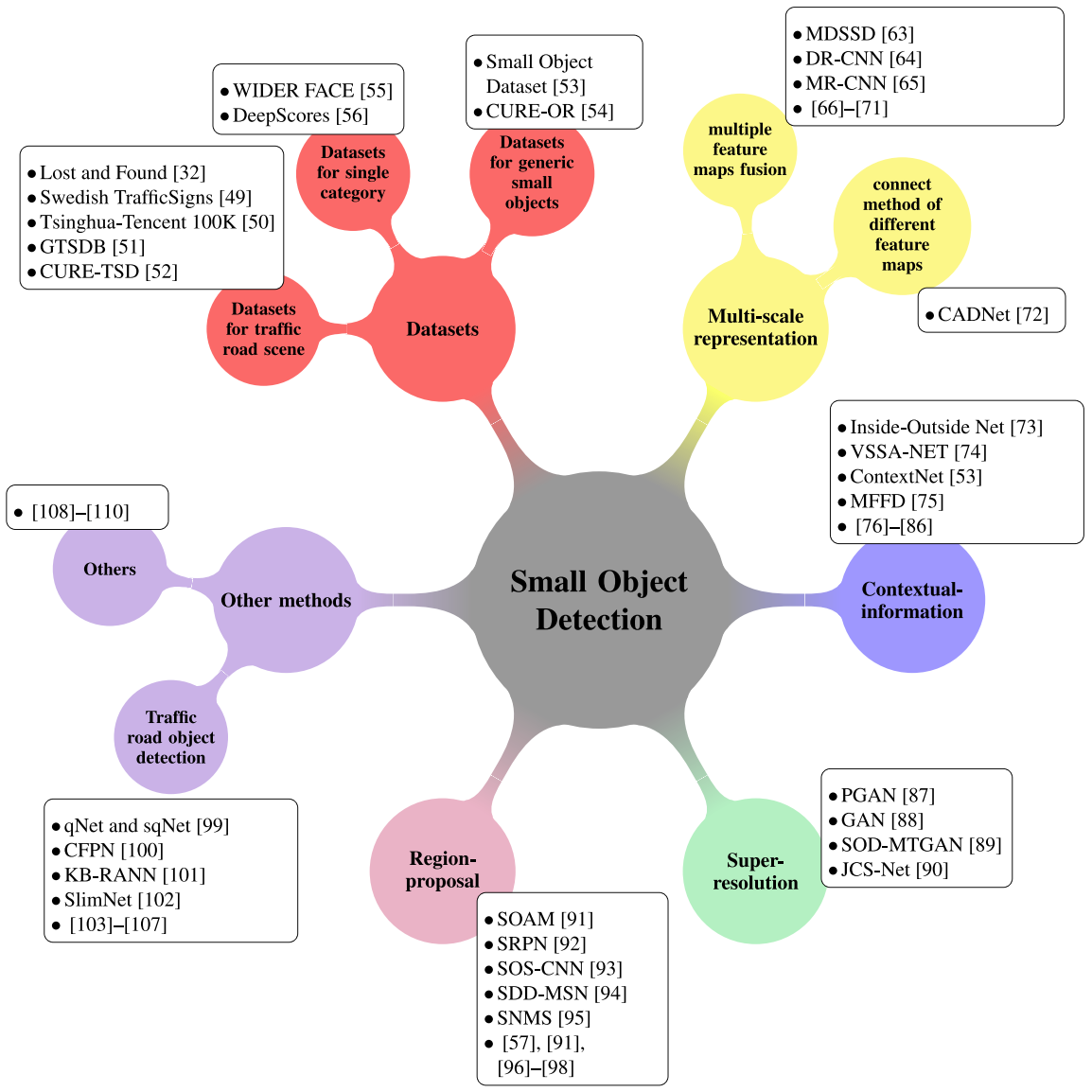
小目标检测问题的四种主要解决方案:多尺度表示、上下文信息、超分辨率和区域提议。此调查还收集了相关的小目标数据集。
二、四项难点
- 小目标覆盖图像面积小,用于目标检测的有效特征少,但是常用检测器对小目标不敏感;
- 小目标散布在图像的各个区域,可能出现在边角,可能与大目标发生遮挡,而且小目标容易受到图像噪声影响;
- 目标检测常用的AP和mAP指标不适用于小目标,小目标的小偏移将导致IoU的大变化;
- 小目标检测的数据集少,大都是简单场景的数据集,缺乏复杂场景中的小目标检测数据集;
三、四大类方法
小目标检测的框架主要分为两种范式,一种是利用手工特征和浅层分类器,检测诸如路障或交通标志等对象,但由于特征提取方法较弱,通常性能不佳。另一种采用深度卷积神经网络(DCNN)提取图像特征,然后修改主流的通用目标检测网络,以达到准确性和计算成本的良好折衷。提出了许多创新方法,显著改善了传统小目标检测的性能。在图3中,展示了小目标检测研究社区的概览。
基于每种方法中使用的核心理论,本工作将小目标检测的研究工作分类为五个类别,即多尺度表示、上下文信息、超分辨率、区域提议和其他方法。每个类别中表现最佳的模型将被详细描述,而其他类似模型将简要说明,以便清楚解释每个类别。
多尺度表征(Multiscale Representation):高分辨率的浅层表征利用图像细节进行目标定位,低分辨率的深层表征利用语义信息进行目标分类;多尺度表征结合浅层表征的图像细节和深层表征的语义信息完成目标检测;
上下文信息(Contextual Information):现实世界中的物体与周围环境存在联系,利用这种联系可以提高目标检测的准确率;中大目标能为检测器提供面积足够大的特征区域,但是小目标的特征区域小,需要用周围环境信息补充;
图像超分辨(Super-Resolution):小目标检测的困难根源是小目标覆盖的像素点少,如果可以得到更高分辨率的图像,这个问题就迎刃而解了;通过构建GAN网络,由原始图像生成更高分辨率的图像,对更高分辨率的图像进行目标检测即可;
区域候选(Region Proposal):常用的目标检测方法利用预设锚框(anchor)代替滑窗遍历,提升目标检测效率;但是常用方法针对中大目标设置锚框,不适用于小目标,所以需要针对小目标设置锚框;
3.1 多尺度表示
目标检测包含定位和分类两项任务,高分辨率的浅层特征图包含更多的细节信息,适用于定位任务;
低分辨率的深层特征图提取整体的语义信息,适用于分类任务;
融合浅层特征图和深层特征图,可以完成目标定位任务。
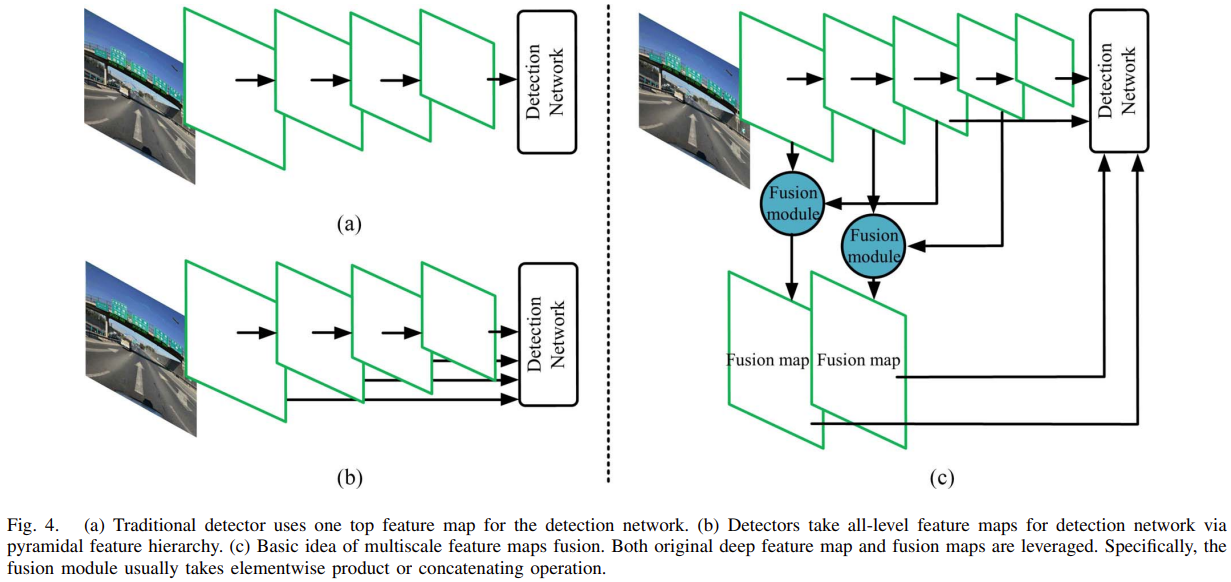
对比目标检测的常用方法、金字塔方法、多尺度表征方法。常用方法使用最深层特征图;金字塔方法使用所有特征图,但运算复杂度高且噪声干扰大;多尺度表征方法改进金字塔方法,选用个别重要的特征图进行特征融合。
- 多尺度特征融合(Multiple Feature Maps Fusion): MDSSD, DR-CNN, MR-CNN;
- 研究特征层融合的方式(Connect Method of Different Feature Maps): CADNet
3.2 上下文信息
小目标检测的根本难点在于其覆盖范围小,检测器能感知到的信息有限。对于任意目标,他们存在于特定场景或者与特定目标共存,因此利用小目标的上下文信息,补充小目标提供的有限特征。上下文信息方法利用小目标与其他目标或者背景之间的关系,提升小目标检测的准确率。
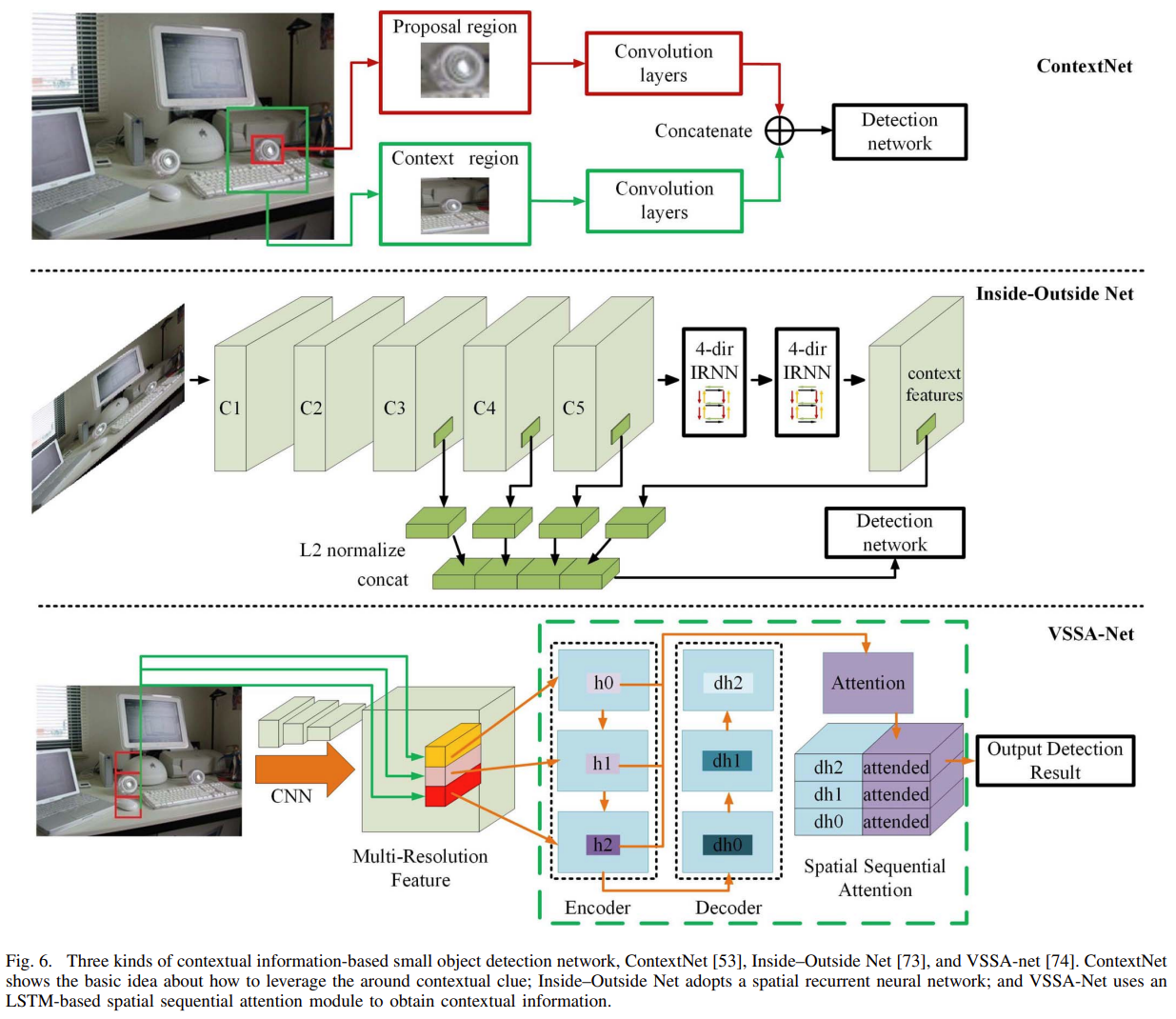
- ContextNet:针对小目标检测,利用上下文信息改进R-CNN;网络通过Proposal Region Module编码小目标候选区域的上下文信息,通过Context Region Module编码相同中心的更大上下文信息,再合并小目标的候选区域和包含更多上下文信息的区域,得到包含上下文信息的小目标区域特征,利用该特征进行目标检测;
- Inside-Outside Net:首先通过多层卷积获得多层级特征,然后利用IRNN模块获取上下文信息,合并多层级特征和上下文信息,最后对合并特征进行目标检测;
- VSSA-Net:首先通过多层卷积获取多尺度特征,然后将多尺度特征输入Encoder-Decoder结构,利用注意力机制向特征加入上下文信息,最后进行目标检测;
3.3 图像超分辨率
由于小目标有限的图像覆盖区域会影响检测效果,可以通过图像超分辨率强化包含小目标的低分辨率图像,得到更高分辨率图像,对高分辨率图像进行目标检测即可。
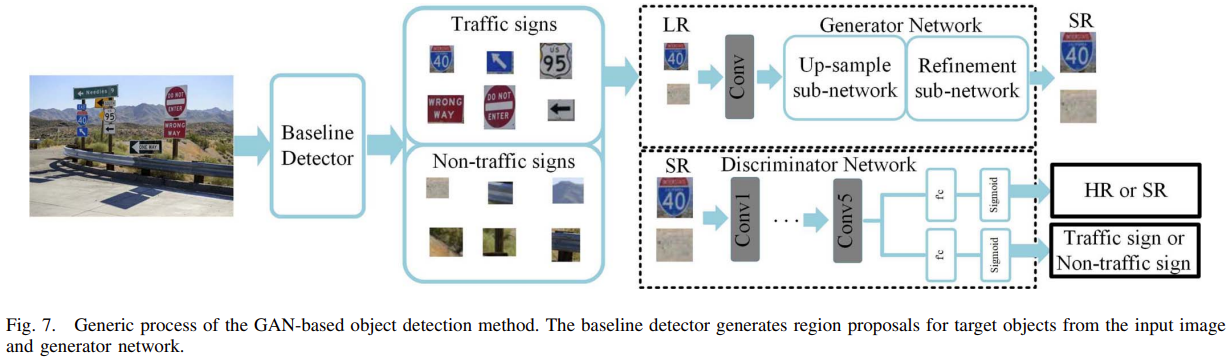
结合上图,使用GAN方法将低分辨率图像恢复成高分辨率,首先通过Baseline Detector从输入图像得到包含小目标和不包含目标的区域,GAN中的Generator根据包含小目标的区域生成高分辨率图像,Discriminator比较生成高分辨率图像和不包含目标区域,得到具备超分辨率能力的GAN。基于GAN的方法首先生成包含小目标的高分辨率图像块,然后检测这些高分辨率图像块。
- 基于图像超分辨率的方法(Super-Resolution Method): Perceptual GAN, GAN, SOD-MTGAN, JCS-Net
3.4 区域候选
区域候选的目的是生成潜在的检测框,Faster RCNN之前的目标检测通过滑窗法或者选择搜索法生成检测框;Faster RCNN利用先验信息预设锚框(anchor box),然后通过RPN(Region Proporal Network)调整锚框的位置和尺寸,从而使得锚框和真值框(anchor box & GT box)足够贴合。RPN在Faster RCNN中起到目标定位的作用。
四、相关数据集
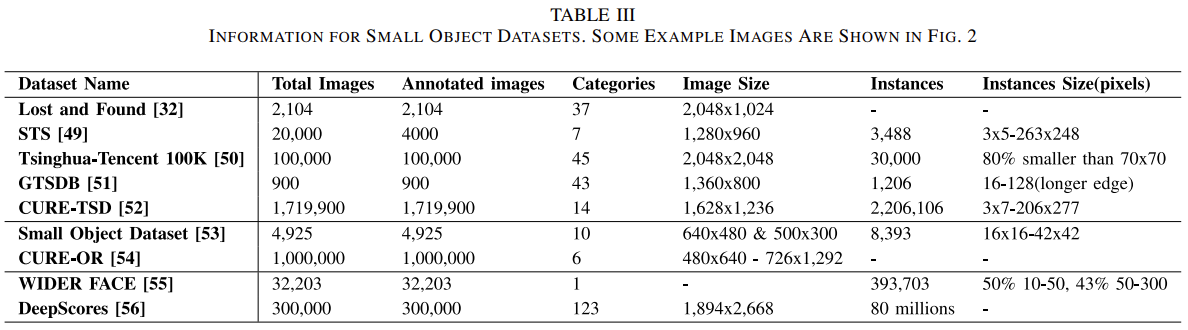
- 道路交通数据集:Lost_and_Found | STS(瑞典) | Tsinghua-Tencent 100K | GTSDB(德国波鸿) | CURE-TSD;
- 通用场景数据集:Small Object Dataset | CURE-OR;
- 单一类别数据集:WIDER FACE(多种社交场合下的人脸) | DeepScores(音谱符号);
五、未来研究方向
- 评价指标(Novel Metric for Small Object Detection): 常用的AP/mAP实际上是PR曲线积分,不反应PR曲线变化趋势,也无法反映bbox覆盖目标的紧密程度;对于小目标,定位精度和bbox覆盖紧密度很重要,轻微偏移都将影响IoU;考虑到小目标对定位精度的要求,可将预测值和真值的中心位置作为评价指标;
- 弱监督学习(Weakly Supervised Object Detection): 小目标检测的数据集不足,不足以支撑通用模型的监督学习;可以尝试使用数据依赖性不高的学习方法;
- 权威数据集(Small Object Datasets): 缺乏针对小目标检测的通用数据集;
- 结合多种方法(Combination of Multiple Kinds of Methods): 可以组合上述四种方法优化;
- 视频中的小目标检测(Small Object Detection in Videos): 现有目标检测方法处理单张图像;相比单张图像,视频包含时序信息,可以通过光流、LSTM研究目标在视频中运动的是时空相关性;
- 目标检测框架(High Precision or Real-Time Detection Framework): 平衡目标检测的准确性和实时性;不同应用场景的侧重点不同;