Abstract
最近最先进的检测器通常利用特征金字塔网络 (FPN),因为它具有检测不同尺度对象的优势。尽管由于特征金字塔的设计在目标检测方面取得了重大进展,但在复杂场景中检测低分辨率和密集分布的小目标仍然具有挑战性。为了解决这些问题,我们提出了注意特征金字塔网络,这是一种名为 AFPN 的新特征金字塔架构,它由三个组件组成,以增强小目标检测能力,具体而言:动态纹理注意力、前景感知共同注意力 和 细节上下文注意力。
首先,Dynamic Texture Attention动态纹理注意力 通过 过滤掉冗余语义以突出显示较低层中的小对象 并 放大可信细节以强调较高层中的大对象 来动态增强纹理特征。
然后,探索 前景感知共同注意,通过前景相关的上下文增强对象特征 并抑制背景噪声 来检测密集排列的小对象。
最后,为了更好地捕捉小目标的特征,Detail Context Attention 细节上下文注意力自适应地聚合不同尺度的 RoI 特征的细节线索,以获得更准确的特征表示。
通过在 Faster R-CNN 中用 AFPN 代替 FPN,我们的方法在Tsinghua-Tencent 100K 上的表现与最先进的表现相当。此外,我们在 PASCAL VOC 和 MS COCO 的小类别上都取得了极具竞争力的结果。
1. Introduction
目标检测是计算机视觉的核心任务之一。基于卷积神经网络 (CNN) 的深度学习的最新进展提高了检测器的性能(Dai、Li、He 和 Sun,2016 年;Fu、Liu、Ranga、Tyagi 和 Berg,2017 年;Girshick,2015 年;Girshick, Donahue、Darrell 和 Malik,2014 年;Liu 等人,2016 年;Redmon、Divvala、Girshick 和 Farhadi,2016 年;Redmon 和 Farhadi,2017 年;Ren、He、Girshick 和 Sun,2015 年)推动最先进的技术。在检测器中,特征金字塔网络 (FPN)(Lin 等人,2017 年)是一种简单有效的目标检测两阶段框架。具体来说,FPN (Lin et al, 2017) 是第一种通过整合多层次特征和构建特征金字塔来增强特征表示的方法,其中高级特征用于检测较大的对象,而低级特征用于检测较小的对象。
通过增强具有强语义的多尺度表示,目标检测器的性能得到了显著发展。然而,现有的检测器仍然在使用 FPN 中的特征金字塔在某些(例如,小的、被遮挡的或被截断的)条件下检测物体时遇到问题。在这项工作中,我们专注于通过 缓解三个问题 来提高小目标检测的性能:(1)负责小目标检测的浅层特征包含分散注意力的特征。 (2) 由于高密度分布中过多的背景噪声,用于检测小目标的低级特征的判别力较差。 (3) 小目标的感兴趣区域(RoI) 太小,由于缺乏详细信息而无法识别。
对于第一个问题,利用较低层 进行多尺度特征融合 是一种有效缓解小目标检测问题的方法。 FPN (Lin et al, 2017) 构建特征金字塔,通过自上而下的路径聚合低级和高级特征。 FPN 的一些变体(Amirul Islam, Rochan, Bruce, & Wang, 2017; Ghiasi, Lin, & Le, 2019; Liu, Qi, Qin, Shi, & Jia, 2018b)以自上而下或自上而下的方式探索各种信息传播路径自下而上的方式。然而,由于较低层的区域细节不可靠以及下采样过程中的信息丢失,这些融合方式不适合检测小目标,从而导致性能欠佳。
对于第二个问题,小物体往往密集地排列成一团,这带来了各个物体特征之间的相互干扰。换句话说,属于前景的小物体与背景区域无法区分。最终,它会导致检测器性能下降,尤其是丢失小物体。由于与大物体相比,小物体在图像中只占很小的一部分,因此 突出可能的目标特征并抑制噪声 是 使检测器对高密度小目标更敏感的一种方法。为了减少背景噪声的不利影响 并 强调小目标的前景目标线索,以前的作品(Min, Lee, & Lee, 2021; Wang, Yuan, & Yu, 2017; Yang et al, 2019)使用了 真值边界框的掩码 更有效地 捕捉 复杂背景中小物体的前景特征。然而,这些方法利用了额外标记的掩码数据,这对于准备训练数据来说是劳动密集型的。
对于最后一个问题,引入了超分辨率(SR)方法来丰富小 RoI 的表示。当 RoI 池化层提取用于预测最终类别和边界框回归的特征时,RoI 特征会丢失其对检测小尺度对象有用的细节信息。为了增强小尺寸候选框的表示,之前的一些研究 利用了特征级超分辨率(Bai, Zhang, Ding, & Ghanem, 2018; Li et al, 2017; Noh, Bae, Lee, Seo, & Kim , 2019),它 超分辨了候选框的特征,从而提高了小目标检测的准确性。然而,这种方法通过 利用 具有高计算负担的特征生成器 来超分辨 RoI。
根据上述观察,我们提出了一种称为 AFPN 的新型小目标检测器,这是一个简单有效的特征金字塔,它聚合了三个不同的组件来解决上述问题。首先,提出了动态纹理注意,通过过滤掉冗余语义以 突出显示较低层中的小对象 并 放大可信细节以强调较高层中的大对象 来动态增强纹理特征。其次,Foreground-Aware Co-Attention 旨在通过关联前景相关的上下文来突出可能的目标线索,并利用注意力图集中在密集分布的小对象上来抑制无信息噪声。第三,引入细节上下文注意,通过 选择不同的池化分辨率 来自适应地捕获小 RoI 的细节信息,以获得更准确的特征表示。
我们对三个具有挑战性的数据集进行评估:带有小交通标志的Tsinghua-Tencent 100K、带有一般对象的 PASCAL VOC 和 MS COCO。实验结果表明,我们的多尺度测试方法通过有效提升小物体检测,在清华-腾讯 100K 上优于最先进的方法。此外,与多尺度测试方法相比,我们的单尺度测试方法在 PASCAL VOC 和 MS COCO 上实现了相当的性能。
我们论文的主要贡献如下:
• 我们提出了注意力特征金字塔网络 (AFPN),这是一种新的特征金字塔网络,用于检测具有少量像素和密集分布的小目标,具有动态纹理注意、前景感知共同注意、和 细节上下文注意。
• Dynamic Texture Attention 旨在通过过滤掉多余语义以强调较低层中的小对象并增强可信细节以突出较高层中的大对象来生成纹理放大特征。
• 为了解决密集分布的小物体的噪声问题,我们开发了前景感知共同注意,增强与前景相关的特征并抑制无信息区域。
• 对于包含 有限 和 变形信息的小目标,我们引入细节上下文注意力 以自适应地聚合具有不同尺度的RoI 特征的细节线索,以获得更准确的特征表示。
• 我们的方法显著增强了带有 FPN 的 Faster R-CNN 在三个基准数据集上的小目标检测能力:Tsinghua-Tencent 100K(Zhu 等人,2016 年)、PASCAL VOC(Everingham、Van Gool、Williams、Winn 和 Zisserman,2010 年) ), 和 MS COCO (Lin et al, 2014)。当 Faster R-CNN 中的 FPN 被 AFPN 替代时,我们的方法达到了与清华腾讯上最先进的性能相当的水平(Zhu et al, 2016)。此外,我们在用于一般目标检测的 PASCAL VOC(Everingham 等人,2010 年)和 MS COCO(Lin 等人,2014 年)的一小部分上取得了极具竞争力的结果。
2. Related work
2.1. General object detection通用目标检测
目标检测是计算机视觉的核心任务之一,具有广泛的应用(González、Zaccaro、ÁlvarezGarcía、Morillo 和 Caparrini,2020 年;Kim、Kim、Jang 和 Lee,2017 年;Kong、Zhang、Guan 和 Le , 2021; Lee & Kim, 1999; Lee, Kim, & Groen, 1990; Lee & Song, 1997; Lin, Jia, Huang, & Gao, 2021; Liu, Li, Yuan, Du, & Wang, 2021; Wang, Dai, Cai, Sun, & Chen, 2018; Wang, Lu, Zhang, Yuan, & Li, 2022; Yang, Chen, Xiong, Yuan, & Wang, 2022; Zhou & Gu, 2020)。基于深度学习的检测器分为两阶段和单阶段。
双阶段检测器 (Dai et al, 2016; Girshick, 2015; Girshick et al, 2014; Ren et al, 2015) 集成了用于目标检测的 CNN,取得了出色的性能。 Faster R-CNN (Ren et al, 2015) 提出通过设计一个区域生成网络来生成精细的提案。 R-FCN (Dai et al, 2016) 在池化操作期间引入了与重区域 CNN 的计算相比有效地执行区域完全卷积。 Mask R-CNN (He, Gkioxari, Dollár, & Girshick, 2017) 提议附加一个掩码预测分支,以提高对象检测和实例分割的性能。
与两阶段方法相反,单阶段方法(Lin, Goyal, Girshick, He, & Dollár, 2017b; Liu et al, 2016; Liu, Huang, et al, 2018a; Redmon et al, 2016)被提出用来检测通过使用预定义的锚框直接进行分类和定位来识别对象。 SSD (Liu et al, 2016) 引入了基于多层金字塔特征的多尺度目标检测。浅层和深层特征图分别用于检测小物体和大物体。 RetinaNet (Lin et al, 2017b) 提出了一种焦点损失来处理前景和背景类别之间的不平衡问题。 RFBNet (Liu et al, 2018a) 引入了组合多尺度感受野的多个分支以增强特征表示。
然而,由于目标检测的复杂尺度变化,以前的方法(Fu 等人,2017 年;Kong 等人,2017 年;Lin 等人,2017 年)探索了多尺度金字塔特征的利用。这些方法涉及具有横向连接的额外自上而下路径,并从这些金字塔的相应层检测每个尺度的对象。此外,其他方法(Kim, Kook, Sun, Kang, & Ko, 2018; Kirillov, Girshick, He, & Dollár, 2019; Zhao et al, 2019; Zhou, Ni, Geng, Hu, & Xu, 2018)已经调查特征金字塔的好处,并取得了可喜的成果。 TridentNet (Li, Chen, Wang, & Zhang, 2019) 提出通过具有不同感受野的并行多个分支的架构来产生特定于尺度的特征,从而提高了两阶段检测器的性能。 Kong、Sun、Tan、Liu 和 Huang (2018) 通过组合多尺度特征并将它们重新映射到不同层次来重新配置特征金字塔。
最近引入了无锚检测器(Law & Deng,2018;Tian、Shen、Chen 和 He,2019;Zhou、Wang 和 Krähenbühl,2019;Zhu、He 和 Savvides,2019)以直接回归位置没有预定义锚点的对象以提高计算和内存效率。
同时,最近针对各种多尺度物体进行了实时检测器的研究。 Wang 等人 (2022) 构建了一个包含低光照车牌场景的大规模视频数据集 LSV-LP 用于实际应用。 Liu 等人 (2021) 提出了一种 ABNet,用于从遥感图像中的复杂背景中检测多尺度对象。(ABNet: Adaptive balanced network for multi-scale object detection in remote sensing imagery.) Yang 等人 (2022) 介绍了使用同心掩码实时检测任意形状文本的 CM-Net 拟合任意形状文本轮廓。
尽管多尺度目标检测取得了重大进展,但检测小目标仍然是一个未解决的挑战。因此,仍然需要探索为小目标检测量身定制的检测器。
2.2.小目标检测
由于小目标的检测主要受益于大尺度的特征图,之前的一些小目标检测器采用了超分辨率(SR),大致分为 图像级的SR(Bai et al, 2018; Fookes, Lin, Chandran, & Sridharan, 2012 年;Hu & Ramanan,2017 年)和 特征级 SR(Li 等人,2017 年;Noh 等人,2019 年)。对于 图像级 SR,Hu 和 Ramanan (2017) 提出应用 双线性插值 来实现大规模输入图像。Fookes 等人 (2012) 通过采用 生成对抗网络 (Goodfellow 等人, 2014) 引入了超分辨率人脸图像的生成。然而,这些方法增加了推理时间,因为 输入图像是大规模的并且不可端到端训练。SOD-MTGAN (Bai等人, 2018) 提出 超分辨率 RoIs 而不是超分辨率整个图像;然而,许多 RoI 仍然需要大量计算。
与图像级 SR 不同,特征级 SR 直接对特征进行超分辨率。 Perceptual GAN (Li et al, 2017) 通过缩小小目标和大目标的表示差异来丰富小物体的特征。 Noh 等人 (2019) 研究了特征级 SR 的改进,并提出在训练过程中对小规模目标 RoI 使用直接监督。 EFPN (Deng, Wang, Liu, Liu, & Jiang, 2021) 被提出来扩展特征金字塔网络,以利用为检测小目标量身定制的具有高分辨率的额外金字塔层级。
尽管现有方法 利用额外的网络(生成器和鉴别器)进行对抗性训练,通过两步训练过程提高了小目标的检测性能,但对抗性训练可能不稳定。
另一种改进小目标检测的方法是 使用真值框的掩码。 SCRDet (Yang et al, 2019) 提出了一种有监督的像素注意方法,通过使用目标掩码 来抑制降低小型空中目标检测的噪声。 Wang et al (2017) 引入了带掩码的锚点注意力,以突出小脸区域的特征。 ACNet (Min et al, 2021) 提出了用于小痤疮acne检测的掩码感知多注意力,以强调前景痤疮线索并减少背景噪声的不利影响。尽管用于抑制背景噪声的掩码提高了小物体检测的性能,但是生成真值掩码需要昂贵的劳动力并且是一项耗时的任务。
2.3. 用于目标检测的上下文利用
在目标检测中,之前的一些方法已经通过经验证明了上下文在小目标检测中的重要性。正如 Liu et al (2016) 所证明的那样,高级特征包含足够的语义来检测大目标,但包含较少的细节信息来检测小目标,而低级特征提供的细节信息足以捕获小目标,但小目标的语义较少。因此,许多方法(Bell、Zitnick、Bala 和 Girshick,2016 年;Fu 等人,2017 年;Lin 等人,2017 年;Qi 等人,2022 年;Shrivastava、Sukthankar、Malik 和 Gupta,2016 年;Xiang、Zhang、Yu , & Athitsos, 2018) 使用额外的层通过集成低级细节和高级语义来增强上下文信息。同时,另一种方法是在 RoI 池化期间考虑周围区域以提取上下文信息。 Zagoruyko 等人 (2016) 提议使用每个 RoI 的四个视野来捕获围绕对象的不同级别的上下文信息。 Cai、Fan、Feris 和 Vasconcelos (2016) 介绍了增加 RoI 的填充率以获得更大的池化区域。 Hu 和 Ramanan (2017) 提出了池化 RoIs 周围区域用于人脸检测,因为这有助于了解人体的存在。最后,几种方法(Chen、Papandreou、Kokkinos、Murphy 和 Yuille,2017 年;Hamaguchi、Fujita、Nemoto、Imaizumi 和 Hikosaka,2018 年;Yu 和 Koltun,2015 年;Zhao、Shi、Qi、Wang 和 Jia,2017 年)提出利用 空洞卷积 和 混合卷积 进行小目标检测,因为它们扩大了感受野,可以有效地覆盖小目标而无需任何额外的计算成本。在本文中,我们建议更好地利用这些特性来提高检测小目标的性能。
3. 提出的方法
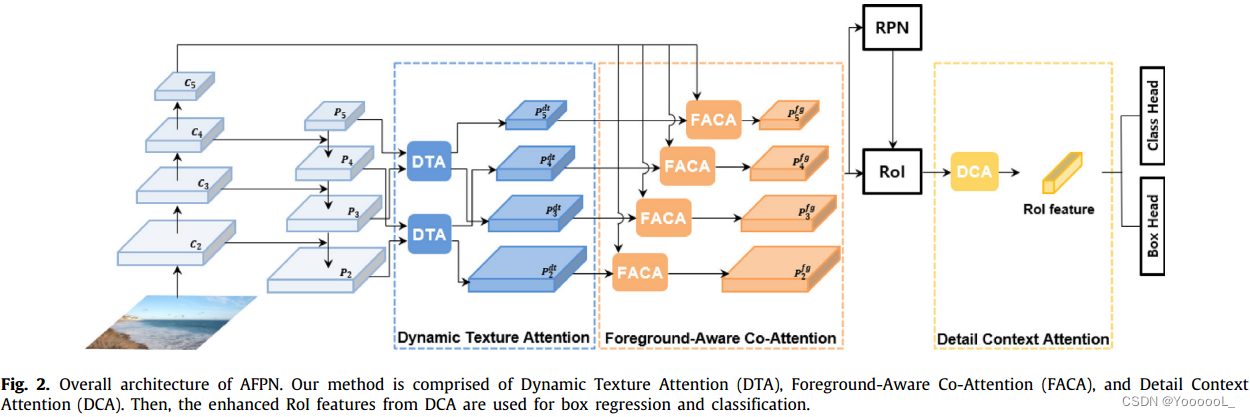
AFPN 的概述如图 2 所示。根据 FPN (Lin et al, 2017) 的设置,特征 {C2, C3, C4, C5} 表示用于构建特征金字塔的特征层次结构。此外,{P2, P3, P4, P5}分别表示输入图像中步长为4、8、16、32像素的金字塔特征,![]() 是 使用 动态纹理注意 (DTA)(第 3.1 节)从特征金字塔生成的纹理增强特征,
是 使用 动态纹理注意 (DTA)(第 3.1 节)从特征金字塔生成的纹理增强特征,![]() 是 使用 前景感知共同注意力(FACA)(第 3.2 节)进行前景相关上下文增强后的特征。这些特征通过 RPN 生成 RoI。然后,细节上下文注意(DCA)(第3.3节)对每个RoI进行RoI池化,以生成更好的RoI特征,用于后续的边界框分类和回归。以下小节详细介绍了 AFPN 的三个组成部分。
是 使用 前景感知共同注意力(FACA)(第 3.2 节)进行前景相关上下文增强后的特征。这些特征通过 RPN 生成 RoI。然后,细节上下文注意(DCA)(第3.3节)对每个RoI进行RoI池化,以生成更好的RoI特征,用于后续的边界框分类和回归。以下小节详细介绍了 AFPN 的三个组成部分。
3.1.动态纹理注意力
FPN 将固有的特征层次结构用于不同分辨率的特征图。为了聚合多尺度上下文,FPN 通过自上而下路径中的横向连接将高级语义和低级细节结合起来。假设有两个金字塔层,一个较低层 F(i) 和一个较高层 F(i+2) (i = 2, 3)。在特征金字塔网络中,浅层的特征F(i)和深层的特征F(i+2)分别负责检测小物体和大物体。然而,较低级别的层 F(i) 仍然包含具有不可靠区域细节的噪声,这将导致小目标检测的次优性能。同时,较高层 F(i+2) 包含一些小物体的信息。由于高级特征负责大目标,检测器可能会将小目标的歧义语义与大目标混淆。
因此,我们提出 动态纹理注意(DTA)通过 减少冗余语义 来 动态放大纹理信息 以强调较低层中的小目标 并增加可信细节以突出较高层中的大对象,从而提高检测小目标的性能。具体来说,通过 设计 DTA 来融合 F(i+2) 和 F(i),我们 去除了削弱浅层 F(i) 中小对象特征的大目标特征,并 增加小目标的可信细节,补充深层 F(i+2) 中的大目标特征。为了实现这一点,我们用小目标从 F(i) 中减去 F(i+2),并将 F(i) 添加到 F(i+2)。
一方面,在浅层的特征中准确表示小目标具有挑战性。由于过多的背景噪声,较低级别的特征对检测小目标的判别性较低。虽然标准的空洞卷积能够在不增加核参数的情况下获得更大的感受野大小,但它 仍然受到膨胀卷积的输出具有固定感受野大小的限制。为了解决这个问题以更好地表示较低的特征,我们提出 利用具有不同扩张率的扩张卷积 来动态控制较低层中小目标的感受野,通过 学习注意力分数 来决定具有多个感受野的通道的重要性。因此,我们增强了低层中小目标的特征表示,以便 在 DTA 中的减法和求和操作之前 以较少的噪声正确编码。
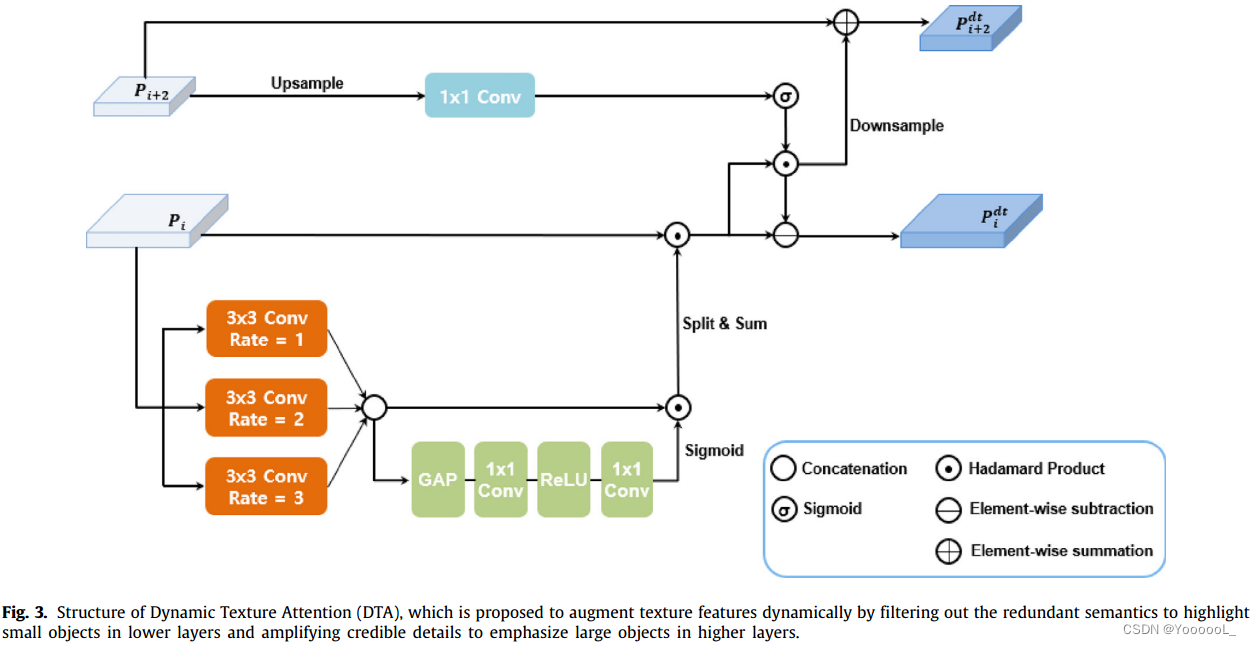
所提出的 DTA 的结构如图 3 所示。该组件有两个输入特征:一个是低层特征图 Pi,另一个是高层特征图 Pi+2。这些输入用于生成 DCA 的低级输出特征图。我们可以生成过滤后的特征图
如下:
![]()
其中 Pd 表示浅层的增强特征,通过动态利用各种扩张率的扩张卷积更准确地表示小物体,Ps 表示注意力图,以抑制信息丰富的高分辨率特征中分散注意力的低分辨率特征。
具体来说,特征图 Pd 是通过 将注意力分数 α 应用于级联特征 Pcat 产生的,级联特征 Pcat 利用通过具有不同扩张率 (r = 1, 2, 3) 的空洞卷积的输出聚合得到。在通过 Hadamard 乘积将注意力权重应用于 Pcat 之后,将其拆分并与逐元素求和相结合。 Pd 公式为:
![]()
其中 ψ(·) 表示顺序拆分和逐元素求和的操作。注意力分数表明通道的重要性,通过通道注意力考虑感受野(Hu, Shen, & Sun, 2018)如下:
![]()
其中 W1 ∈ R C/r*C 是第一个 1×1 卷积层的可学习权重,W2 ∈ R C*C/r 是第二个 1×1 卷积层的可学习权重。 Pavg(·)、δ(·)、σ(·)分别表示平均池化、ReLU函数、sigmoid函数的运算。减小比设置为 r = 16。
为了得到语义注意力图 Ps ,对特征图 Pi+2 进行上采样以达到与 Pi 相同的大小。(原文章这里有错误)。之后,上采样的特征图通过 1×1 卷积层和 sigmoid 函数产生 Ps,如下所示:
![]()
其中 ϕ 由顺序的双线性上采样、1×1 卷积层和 sigmoid 函数组成。
更高层的输出特征图 定义如下:

其中 D 表示下采样操作,以保持与 Pi+2 一致的空间分辨率。 动态纹理注意力进行后,得到特征![]() ,送往前景感知共同注意力。
,送往前景感知共同注意力。
3.2.前景感知共同注意力
由于 密集排列的小目标的分布,将前景小目标与背景区分开来具有挑战性,因为 背景的大量噪声压倒了前景小物体。此外,由于在现实世界中 复杂的场景中小目标通常只包含几个像素,因此 提取与相似形状或外观的背景不同的前景特征 用于小目标检测具有挑战性。由于 更大的类内方差,这个问题会导致 将不感兴趣的背景错误分类到前景类中。因此,削弱非目标区域并增强目标线索至关重要。为了 更有效地 捕捉复杂背景下 小目标的线索,提出了 前景感知共同注意力(FACA)通过 将与场景相关的上下文相关联 来 增强前景特征辨别力。此外,我们 添加了一个额外的分支来减少噪声 并 通过自适应选择具有丰富空间细节的特征图 来略微改善目标信息。
核心思想如图4所示。我们 首先对特征通道的重要性进行建模,并 重新校准它们以相应地抑制噪声。然后,我们明确定义前景和场景之间的关系,并使用 隐场景嵌入与前景特征相关联。该关系被用于增强特征以 增加前景和背景特征之间的差异,从而改善对小目标的前景特征辨别。
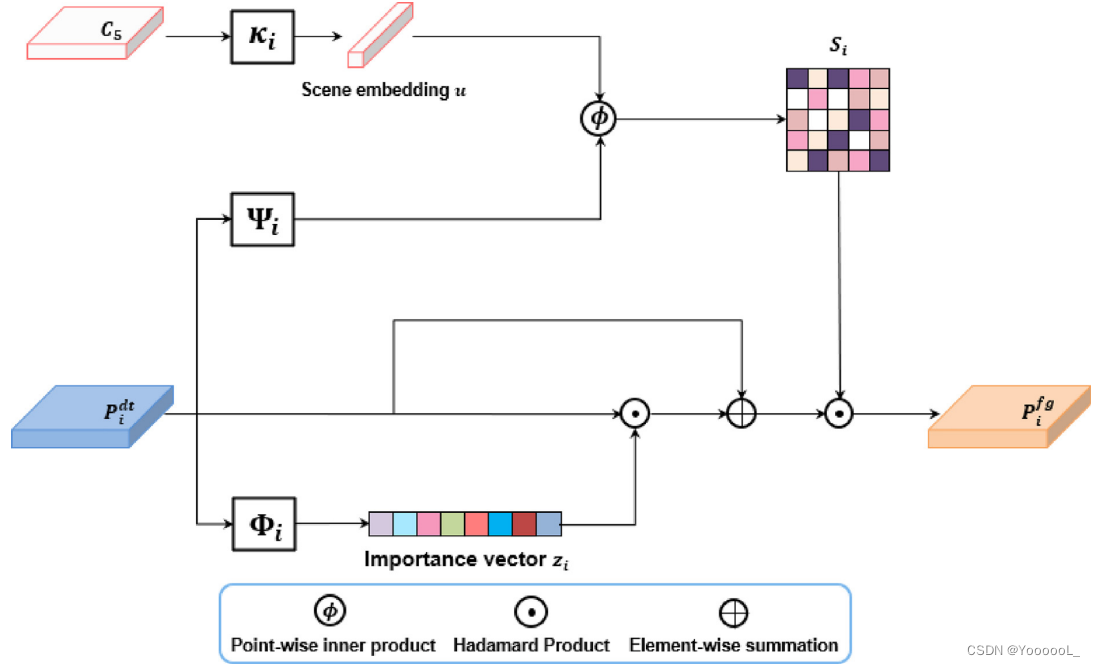
如图 4 所示,使用特征图 ,FACA 生成一个新的特征图
。
通过使用 重要性向量 zi 和 相似度图 Si 对特征图
进行加权来确保。重要性向量 zi 的公式如下:

其中 Φi 表示顺序的 1×1 卷积操作和 sigmoid 函数,其设计用于 选择具有丰富空间细节的特征通道并 抑制特征中的噪声。
相似度图 Si 表示前景和场景表示之间的关系矩阵。为了对齐这些表示,需要两个投影函数来分别学习场景和前景。首先,![]() 是
是 由 φi 变换后的特征图,如下所示:

其中 Ψi 表示投影操作,包括顺序的 1 × 1 卷积层、批量归一化和 ReLU 函数。
为了计算相似度图 Si ,需要 嵌入了场景上下文的一维向量 u 与细化后的特征图 ![]() 进行计算。在C5上利用η计算 场景嵌入向量u,如下:
进行计算。在C5上利用η计算 场景嵌入向量u,如下:

其中 η 表示利用 1×1 卷积层进行前景相关场景表示的投影操作。通过投影函数 Ψi( ) 和 η 的输出,可以通过等式(9).获得相似图 Si。

其中 κi 表示相似度估计函数和 sigmoid 函数。为了计算复杂度的简单性和效率,前一个函数通过逐点内积来执行。
为了增强前景-场景相关的特征 并 抑制背景噪声,FACA 的总输出定义如下:

3.3. 细节上下文注意力
细化的特征随后被传递到生成区域建议的 RPN。由于将特征和proposals作为输入,执行 RoI Align 模块以提取特征以预测最终类别和边界框的回归。通常,池化操作在初始实现时以固定分辨率 7 进行。小目标的识别需要更多的上下文信息,而固定的池化分辨率可能会导致在 RoI 池化过程中丢失大量上下文信息。这种类型的信息丢失 可能是 包含有限和失真信息的小 RoI 的严重问题,很容易导致次优的检测性能。因此,将特定注意力 分配给 具有上下文细节的局部特征 的自适应注意力机制可以帮助 维护小目标的上下文信息。为此,我们提出了 Detail Context Attention (DCA)。我们根据经验选择 7、11 和 15 三种分辨率,而不是使用固定分辨率 7,并执行并行池化操作以获得更全面的特征表示。特别是对于小目标,较大的分辨率往往会强调具有局部细节的上下文信息,从而以灵活简单的方式缓解信息丢失的问题。因为每个生成的特征都包含不同级别的详细信息和语义信息,所以我们打算 有效地集成从不同的 RoI 池化大规模创建的特征。因此,采用注意力机制来自适应地聚合池化结果。
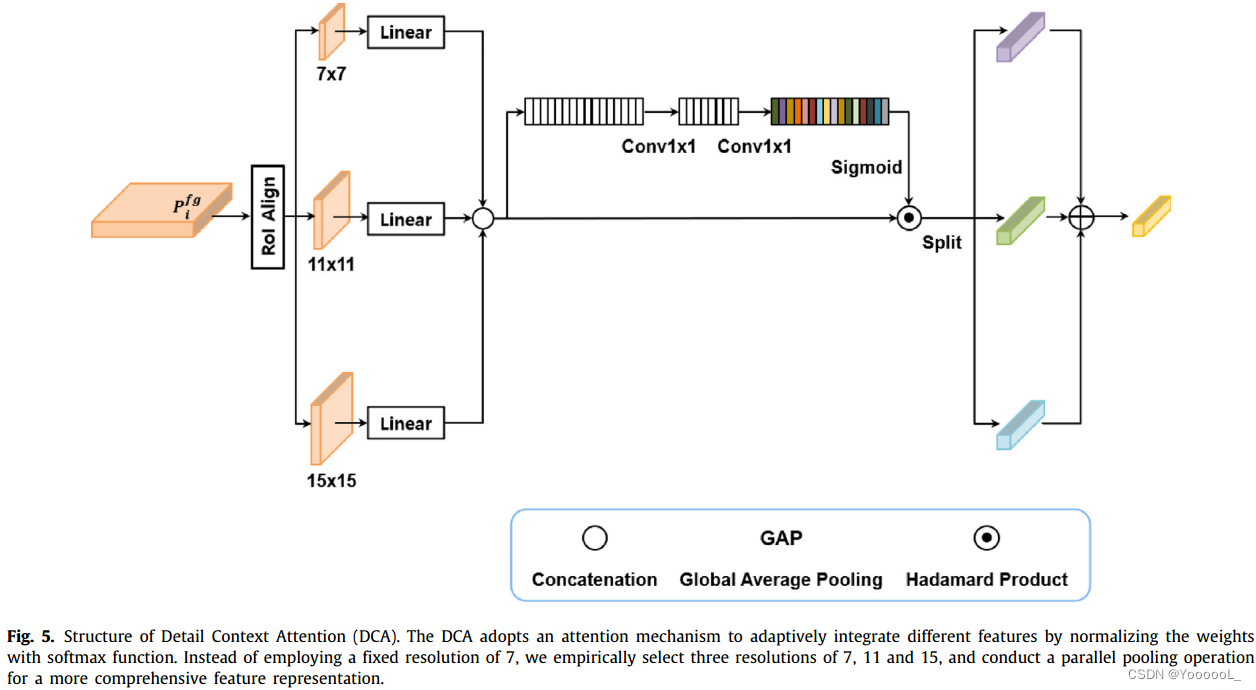
如图 5 中所述,我们首先使用 线性运算 提取每个嵌入向量,然后对向量执行 concatenation连接运算。之后,为连接的向量添加一个注意分支。该分支学会使用自适应的参数 创建增强的 RoI 特征,以改进各种分辨率的 RoI 区域内特征的 significance measurement 显著性测量。最后,我们通过对生成的权重应用 softmax 归一化操作来平衡每个 RoI 向量的贡献。最终输出向量通过加权求和与三个 RoI 向量聚合。
4. Experiments
4.1. Datasets and evaluation metrics
Tsinghua-Tencent 100K.
交通标志检测的大型基准,存在由天气和复杂背景引起的严重照度变化问题,就像在现实世界中一样。训练集有 6K 图像,测试集有 3K 图像,与图像大小 2048×2048 相比,存在非常小的目标对象。以与 MS COCO(Lin 等人,2014)相同的方式,数据集根据像素分辨率分为三个尺度:小子集(面积≤)、中子集(
<面积≤
)和大子集(面积>
)。小型、中型和大型物体的比例分别为 42%、50% 和 8%。因此,Tsinghua-Tencent 100K (Zhu et al, 2016) 是展示小目标检测性能的合适基准。
根据 Zhu 等人 (2016) 的协议,我们对 45 个类进行了评估,包括 221 个类中的 100 多个实例。与 Zhu et al (2016) 仅报告关于大小的召回率和准确性相反,我们进一步报告 F1 分数作为两个评估指标之间的平衡。如果 与真值框的IoU ≥ 0.5,则检测结果被认为是正确的。
PASCAL VOC.
PASCAL VOC 由 20 个不同的目标类别组成。 VOC 2007 训练集有 5K 张图像,VOC 2007 测试集有 5K 张图像,VOC 2012 训练集包含 11K 张图像。训练是使用VOC 2007和VOC 2012的训练集进行的。评估是在PASCAL VOC 2007的测试集上进行的。为了评估,我们使用[email protected]度量,它表示与真值框匹配的 IoU ≥ 0.5时的平均精度AP。与 MS COCO 一样,我们也根据物体的大小将 PASCAL VOC 结果分为三个不同的组:AP-S(小)、AP-M(中)和 AP-L(大)。
MS COCO.
MS COCO 2017 由 80 个目标类别组成。COCO 训练集包含 115K 个图像,COCO val 集包含 5K 个图像,COCO test-dev 集包含 20K 个图像。对于 MS COCO,标准 COCO 风格的平均精度 (AP) 测量应用于所有呈现的结果,其中包括 [email protected]:.95(IOU 阈值为 0.5 至 0.95 的 AP)、[email protected](IoU 阈值为 50% 的 AP)和 [email protected](IoU 阈值为 75% 的 AP)。我们还根据尺度报告结果:AP-S(小)、AP-M(中)和 AP-L(大)。
4.2.实施细节
我们的框架使用在 ImageNet 上预训练的 ResNet-50、ResNet-101 和 ResNeXt101 主干。我们使用动量为 0.9 和权重衰减为 0.0001 的 SGD 优化器。我们在 Tsinghua-Tencent 100K (Zhu et al, 2016)、PASCAL VOC (Everingham et al, 2010) 和 MS COCO (Lin et al, 2014) 上进行了实验。
在Tsinghua-Tencent 100K 实验中,我们在 2 个 GPU 上训练了我们提出的方法,每个 mini-batch 总共有两个图像(每个 GPU 一个图像)。所有模型都训练了 36 个时期,初始学习率为 0.0025,然后每 10 个时期减少 10 倍。除了用于数据扩充的水平图像翻转以缓解类不平衡之外,我们还利用颜色抖动将每个类扩充到大约 1000 个实例,用于不同类的奇数个数。为了更好地概括,我们在训练期间使用了未包含在 45 个类别评估中的标签。该模型在训练拆分上进行训练,并在测试拆分上进行测试。在单尺度测试中,我们将图像调整为 1600 × 1600。
在 PASCAL VOC 和 MS COCO 实验中,我们使用两个 GPU(每个 GPU 两个图像)训练检测器 12 个时期,初始学习率为 0.025,如果没有特别说明,在 8 个和 11 个时期后分别将其减少 0.1。仅执行水平图像翻转以进行数据增强。该模型在 train split 上进行训练,并在 test-dev split 上进行测试。 single-scale 测试使用调整大小为短边 800 像素和长边小于 1333 像素的图像,同时保持纵横比。
4.3.性能比较
Tsinghua-Tencent 100K.
在表 1 中,我们的方法与Tsinghua-Tencent 100K测试数据集上的最新方法进行了比较。我们观察到 我们的方法超越了大多数最先进的方法。与使用 ResNet-101 主干的 Faster R-CNN w/ FPN 相比,单尺度 AFPN 将小类别的准确率和召回率分别提高了 5.5% 和 4.1%。更重要的是,我们的多尺度 AFPN 在 F1 分数方面超越了之前所有最先进的方法。特别是,我们的方法在小尺寸物体的 F1 得分方面超过了第一最佳目标检测器:88.6% vs.88.7%。此外,我们的方法在中型(2.5% 召回率和 0.9% 准确率)和大型(4.0% 召回率和 1.4% 准确率)目标上提供了适度的整体增益。这些结果证明了 AFPN 在更准确地分类和定位小尺度目标方面的出色性能。
PASCAL VOC 和 MS COCO。
表 2 总结了我们的方法与 PASCAL VOC 测试和 COCO test-dev 的基线和最先进方法的性能比较。我们发现,所提出的 AFPN 在小型、中型和大型物体上具有相似的趋势,具有更好的性能,如表 1 所示。此外,观察到整体检测性能随着稳定性的提高而相对提高,而小目标检测性能显着提高。
如表 3 所示,我们的方法与其他最先进的单尺度通用检测器在 COCO test-dev split 的 APS 上进行了比较。尽管小目标在 COCO 中比在清华-腾讯 100K 中占据更少,但 AFPN 提高了小目标的检测性能。通过 用 AFPN 代替 FPN,使用 ResNet-50 作为主干的 Faster-RCNN 达到 22.0 APS,这表明 Faster R-CNN 与 FPN w/ Res-Net50 相比提高了 1.0 个点。此外,AFPN 仍然可以通过更好的骨干网络实现不可忽视的性能。具体来说,我们使用 ResNet-101 和 RexNeXt-101 进行特征提取的方法分别将小目标检测性能提高了 1.8% 和 1.3%。它证明即使有更好的主干,AFPN 也可以不断提升性能。最后,我们在 Mask R-CNN 和 Libra R-CNN 上评估 AFPN。通过将 FPN 替换为 AFPN,使用 ResNet50、ResNet-101 和 ResNeXt101 的 Mask RCNN 分别提高了 0.9、1.4 和 1.3 APS。当 Libra R-CNN 配备 AFPN 而不是 FPN 时,AFPN 在 ResNet-50、ResNet101 和 ResNext-101 上的提升分别达到 1.1、1.3 和 1.4 APS。如表 3 所示,AFPN 在各种主干和检测器上的性能不断提高。它展示了 AFPN 的泛化和鲁棒性能力。此外,我们的方法不仅优于 FPN 的变体(例如 PANet Liu 等人,2018b 和 Libra R-CNN Pang 等人,2019),而且优于小目标检测器(例如 SOD-MTGAN Bai 等人,2018 年和 Noh 等人,2019 年)。我们还超越了最先进的多尺度测试检测方法的小目标检测性能(例如,GraphFPN Zhao et al, 2021, AugFPN Guo et al, 2020, R(Det)2 Li & Wang, 2022 , TridentNet Li 等人, 2019, FSAF Zhu 等人, 2019, 和 RPDet Yang 等人, 2019a 等)。
4.4.消融研究
基线设置。
作为基线,我们使用 Faster R-CNN with FPN (Lin et al, 2017) with RoI align。为了公平比较,我们使用相同超参数的设置进行了消融实验。
动态纹理注意力的影响。
如图 1 所示,我们可以观察到 FPN 遗漏了小物体,这是目标检测的主要问题之一。尽管 FPN 的较低层负责检测小物体,但这些层仍然包含用于小目标检测的噪声和不可靠的细节特征。 DTA 可以生成小目标的可信细节特征,从而导致更准确的小物体检测。从表 4 可以看出,DTA 在小规模类别上将基线方法的准确性提高了 1.7%,召回率提高了 1.8%。这些结果表明,DTA 可以通过减少冗余语义来吸引对浅层中小对象的注意。具体来说,为了抑制浅层中大对象的冗余区域,DTA 通过利用空洞卷积从较低层的增强特征表示中获益。
空洞卷积不同扩张率的影响。
为了进一步评估不同扩张率表示小目标的有效性,我们进行了明确的实验来证明详细的性能。准确表示特征图中的小目标以抑制多余的语义信息非常重要。在空洞卷积的帮助下,我们可以增强小物体的特征表示,使其更易于检测。在表 5 中,仅利用空洞卷积在性能上几乎没有差异。为了准确表示小物体,我们考虑了从 1 到 5 的各种扩张卷积,以利用 3×3 卷积核调整小物体的感受野。结合 1、2 和 3 的扩张率的注意机制,可以实现最佳性能。原因可能在于,对于浅层小物体调整感受野时不需要大扩张率 4 和 5 的扩张卷积,这意味着 小目标对局部细节的上下文更敏感。
前景感知共同注意的影响。
表 4 显示,FACA 将小物体的召回率和准确率分别提高了 0.8% 和 1.1%。 FACA 有利于强调可能的对象区域并减少噪声的影响。特别是,当 FACA 与 DTA 结合时,它在小规模类别上表现出更大的性能提升幅度,分别为 1.5% 和 1.3%。我们推断前景场景关系图更好地从与前景上下文具有更高相关性的增强特征生成。因此,FACA验证了削弱背景噪声和加强前景特征的有效性,尤其是对于小物体。
细节上下文注意力的影响。
如表 4 所示,DCA 显示了聚合 RoI 细节上下文的有效性,这有利于检测小物体。该方法在小规模类别上实现了 87.8% 的召回率和 81.5% 的准确率,比基线高出 1.4% 和 1.4%。此外,我们可以观察到 DCA 在提高检测小物体的能力方面更有效,因为前面提出的组件会生成判别特征。具体来说,将从并行分支产生的 RoI 特征与对来自不同比例的 RoI Align 的级联特征图进行通道注意相结合。通过考虑全局利用注意力机制的细节上下文的重要性,可以获得不同级别的细节特征来支持预测过程。因此,与保留小物体细节信息的基线相比,具有 DCA 的 AFPN 取得了显着的进步。
不同 RoI 合并分辨率的影响。
在这里,我们评估了没有 DTA 和 FACA 的不同分辨率的 RoI 池化的效果。表 6 显示了三种合并分辨率的结果。表 6 中的结果表明,对于 7、11 和 15 三种分辨率,DCA 不断将基线提高 83.1% 至 83.2%、83.5% 和 83.7%。从结果中可以看出,仅使用更大的池化分辨率就可以提高性能。然而,当组合由两种以上分辨率产生的特征时,可以获得更好的性能。这表明不仅更大的分辨率倾向于集中在细节信息上,而且采用的注意机制自适应地融合了池化特征。
4.5.定性结果
在图 6 中,以绿色矩形表示的边界框表示所提出的 AFPN 在 Tsinghua-Tencent 100K、PASCAL VOC 和 MS COCO 上的检测结果。据观察,我们的方法成功检测了几乎所有目标,尤其是小规模目标。它演示了我们的方法如何有效地检测小物体。尽管我们的检测器在这些具有挑战性的场景中准确地检测到小物体,但图 6 说明了检测数据集中未标记的微小物体的一些失败案例,这表明微小物体检测的性能仍有改进的潜力。
5.结论
我们提出了注意特征金字塔网络 (AFPN),这是一种新的特征金字塔结构,具有三个组件以增强小目标检测能力,具体而言:动态纹理注意力、前景感知共同注意力和细节上下文注意力。首先,Dynamic Texture Attention 通过过滤掉冗余语义来动态增强纹理特征以突出显示较低层中的小对象并放大可信的细节以强调较高层中的大对象。然后,前景感知共同注意通过选择具有丰富空间细节的特征并通过前景相关上下文增强对象特征来检测密集排列的小对象。最后,为了更好地捕捉小物体的特征,Detail Context Attention 自适应地聚合了具有不同尺度的 RoI 特征的细节线索,以获得更准确的特征表示。实验表明,我们的方法在 Tsinghua-Tencent 100K 上达到了最先进的性能,在 PASAL VOC 和 MS COCO 上取得了极具竞争力的结果。此外,三个基准的实验验证了我们的方法在检测小物体方面是有效的。对于未来的研究,我们打算扩大我们的工作,用有限数量的小物体来解决当前的数据集。小目标数量不足会导致性能下降。此外,人工增强小目标非常耗时且远非完美。因此,我们将致力于开发一种使用生成对抗网络 (GAN) 的数据增强方法,该方法似乎可以以更高的时间效率和更低的成本生成更自然的图像。