目录
1.3 Deformable Part-based Model(DPM)
本文只对目标检测的各个方向和阶段进行大致梳理,不涉及或只简要概括算法。在原来论文的基础上,加上了我自己的一些理解。
摘要
在目标检测领域,甚至在计算机视觉领域,2014年可以说是一条很明显的分界线。在2014年以前,提取图像的特征主要是以人工的方式,但在2014年之后,随着深度学习的蓬勃发展,计算机视觉迎来了一波小高潮。本文主要从一下几个方面阐述了目标检测在1990年至2019年期间的发展历程:
- 一些具有里程碑意义的目标检测器
- 目标检测的数据集
- 衡量标准(metrics)
- 一些用于目标检测的基本神经网络模块(blocks)
- 模型加速的方法(加快检测速度)
- 当下(2019年)一些最为先进的目标检测方法
- 目标检测的应用(行人检测、人脸检测、文本检测等)
1 目标检测的主要方法
下面以时间线来梳理各个目标检测方法的大致内容:
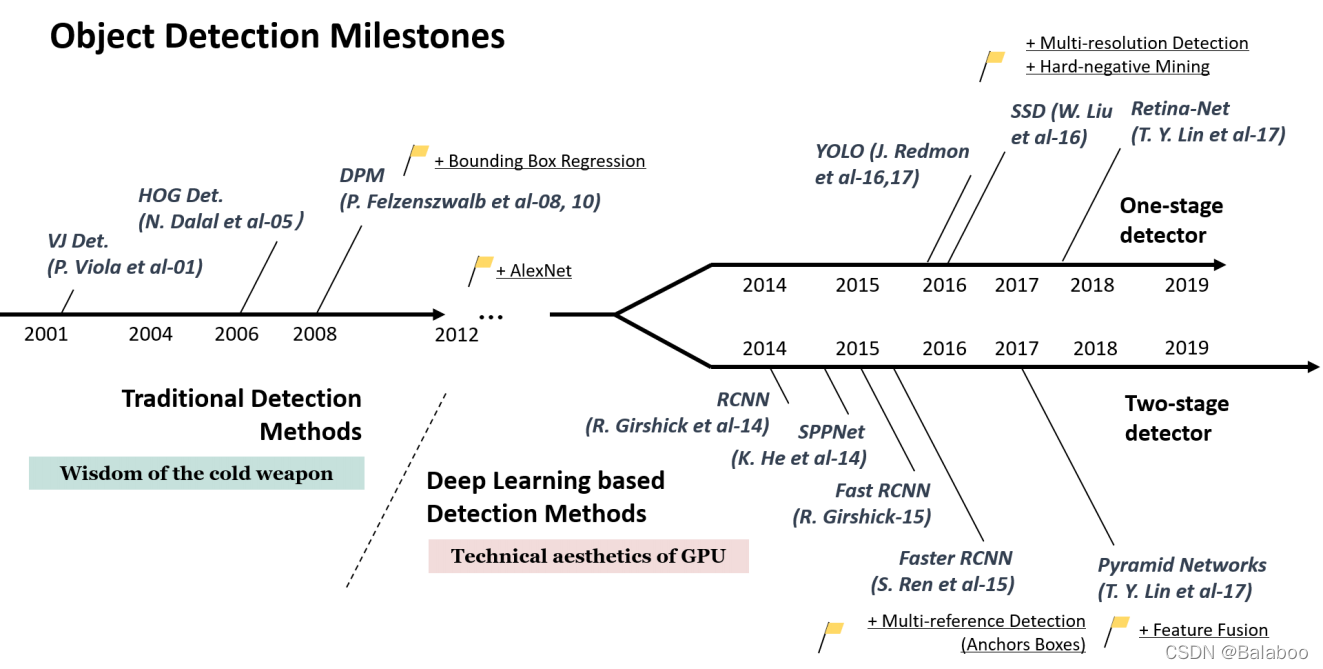
1.1 Viola Jones Detector
1.2 HOG Detector
HOG(Histogram of Oriented Gradients)检测器是用来检测对于物体大小不敏感的特征和形状型下文。为了让检测器对物体的平移、尺度大小、光照等不明显,该检测器大概的计算步骤如下:
- 对输入图片进行灰度化;
- 采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
- 计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
- 将图像划分成小cells(例如6*6像素/cell);
- 统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
- 将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
- 将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
- 最后,使用SVM(支持向量机)对特征进行分类。
1.3 Deformable Part-based Model(DPM)
DPM是传统目标检测方法的天花板,是HOG检测器的延申,DPM分为训练阶段和检测阶段。训练阶段可以看作是将目标分解的过程,检测阶段则是检测一个物体不同部位的集合。DPM算法采用了改进后的HOG特征,SVM分类器和滑动窗口(Sliding Windows)检测思想,具体检测流程可以看参考。DPM也是第一个能够调整先验框的算法。
1.4 RCNN
从RCNN开始,就进入了深度学习的阶段。RCNN的主要思路如下:
- 使用selective search对输入图片生成预选框(object candidate boxes);
- 对每个预选框内的图片进行resize,保证每个图片大小一致;
- 将resize后的图片输入CNN网络(AlexNet)进行特征的抽取;
- 使用SVM对特征进行分类;
- 对预选框进行非极大值抑制;
- 对bbox进行调整(有的预选框可能没有完全框住物体);
1.5 SPPNet
SPPNet主要介绍了一个对输入图片没有尺寸要求的神经网络层——Spacial Pyramid Pool Layer(空间金字塔池化层)。SPPNet可以用于图像分类也可以用于目标检测,这里主要说的是目标检测。在RCNN中的AlexNet要求输入图片的大小必须为224*224,而在SPP层的加入下,则没有了这一限制。SPPNet目标检测的大致思路是:
- 通过selective search生成一系列的预选框;
- 将整张图片输入网络,得到最后的feature map;
- 将步骤1生成的预选框对应至feature map上;
- 在feature map上直接对预选框里的内容使用SPPNet抽取特征;
- 使用SVM对特征进行分类;
- 对预选框进行非极大值抑制;
- 对bbox进行调整;
1.6 Fast RCNN
Fast RCNN又是在RCNN和SPPNet上的延续。Fast RCNN也是使用selective search进行预选框的生成,但是它可以在同一个网络上同时进行特征的提取和bbox的调整,这主要是得益于ROI Pooling层的引入,在网络最后的feature map上加入了ROI Pooling层(类似于1.5中的空间金字塔池化层),直接进行分类和bbox的调整。但是Fast RCNN仍然需要SVM进行分类。
1.7 Faster RCNN
Faster RCNN又是在Fast RCNN的基础上进行改善,主要的变化是引入了RPN(Region Proposl Network),使得网络不再依靠selective search获取预选框,而是直接通过RPN网络生成预选框,其根本原理就是在feature map上生成固定大小的anchors,让网络(全连接层)去判断这些anchors是否包含物体。其他的部分和Fast RCNN差不太多。
1.8 特征金字塔网络
特征金字塔网络(FPN)主要是解决了在不同层的feature map上的语义差异,高层的feature map具有更高的语义(比如属于人、背景等),而底层的feature map可能并没有那么高的语义(比如只关注轮廓、颜色、形状等)。这极大地促进了多尺度目标检测器的发展(例如Yolo)。
1.9 YOLO
YOLO至今一共有V1-V5五个版本,前三个版本为同一个作者(这个作者叫Joseph Redmon,很有个性,有兴趣可以去查一下),YOLO的主要特点就是快,精度略逊色于Faster RCNN。YOLO主要思想是将图片分成许多不同尺度的小网格(YOLOv3中是将图片分成了三个尺度:13*13、26*26、52*52),在每个不同尺度的小格内直接预测小格内的物体种类以及bbox的位置。但是YOLO的不足就在于对于一些小目标的检测效果极差,但后续版本的YOLO也进行了改进。
1.10 SSD
SSD(Single Shot MultiBox Detector)主要引入了Multi-reference和Multi-resolution来解决小目标检测精度差的问题,基本思想就是预先生成一些列不同大小的anchors(锚框),在训练阶段对anchors进行调整。
1.11 RetinaNet
RetinaNet主要提出了一种新的损失函数——focal loss,这种损失函数能够让网络更加关注一些更难的样本。
2 目标检测的数据集以及衡量标准
2.1 目标检测数据集
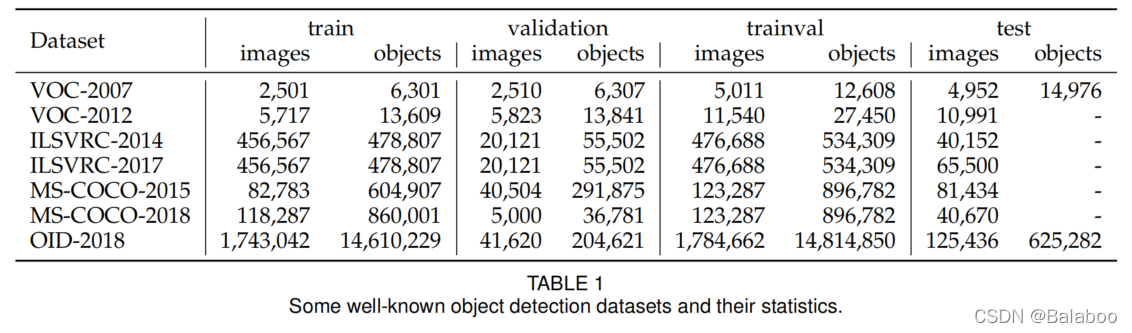
一下是一些主流的数据集,另外这篇综述论文还介绍了一些小众的数据集(比如交通信号灯、文本等)这里就不列举了。
2.2 目标检测衡量标准
如何衡量一个目标检测算法的好坏呢?在2014年以前,主要是使用FPPW(false positives per-window),但在2014年以后,主要使用的是mAP。
3 模型加速的方法
模型加速主要涵盖以下几个方面:
- 共享feature map(对整张图只提取一次特征,在最后的feature map上进行检测)
- 减轻分类时的计算量(主要是讲如何减轻SVM的计算量,现在基本上不用SVM了)
- 使用级联检测(Cascaded Detection)
- 减枝和量化(对神经网络进行裁剪或者近似)
- 轻量化网络设计(设计一个参数量更少、运算简便的网络)
- 数值加速(numerical acceleration)(图像积分、在频域中进行计算、矢量量化、)
- 对全连接层进行低秩分解
4 目标检测近期的成果
4.1 主干网络
目标检测效果的好坏很大程度上依赖于主干网络的好坏,自2015年以后,很多优秀的主干网络都被发明了出来,例如:AlexNet, VGG, GoogLeNet, ResNet, DenseNet, SENet等
4.2 特征融合
4.3 不再使用滑动窗口
例如YOLO算法,并没有依赖于滑动窗口进行检测,而是直接利用feature map进行多尺度检测。
4.4 目标定位上的进步
很多优秀的目标检测算法在检测完成之后会对bbox进行调整,也针对这一调整设计了一些损失函数。
4.5 使用语义分割来帮助目标检测
4.6 让模型对目标的旋转和大小变化更加鲁棒
4.7 让模型从零开始训练
这里主要是说很多时候使用预训练好的模型进行fine tuning可能效果并没有从零开始训练好,因为预训练使用的数据集和你自己训练的数据集可能存在很多差异。
4.8 对抗训练
这里主要是讲了一下GAN网络