博主github:https://github.com/MichaelBeechan
博主CSDN:https://blog.csdn.net/u011344545
Augmentation for small object detection
Mate Kisantal [email protected]
Zbigniew Wojna [email protected]
Jakub Murawski [email protected]
Jacek Naruniec [email protected]
Kyunghyun Cho [email protected]
论文下载:https://arxiv.org/pdf/1902.07296.pdf

摘要:
近年来,目标检测取得了长足的发展。尽管有了这些改进,但在检测小目标和大目标之间的性近年来,物体检测取得了令人瞩目的进展。尽管有这些改进,但在检测小物体和大物体之间的性能仍然存在显着差距。我们在具有挑战性的数据集MS COCO上分析当前最先进的模型Mask-RCNN。我们表明,小地面实况对象与预测锚点之间的重叠远低于预期的IoU阈值。我们猜想这是由于两个因素造成的; (1)只有少数图像包含小物体,(2)即使在包含它们的每个图像中,小物体也看起来不够。因此,我们建议用小物体对这些图像进行过采样,并通过多次复制粘贴小物体来增强每个图像。它允许我们将大型物体上的探测器质量与小物体上的探测器质量进行权衡。我们评估了不同的粘贴增强策略,最终,与MS COCO上的当前最先进的方法相比,我们在实例分割上实现了9.7%的相对改进,在小对象的目标检测上实现了7.1%。
引言
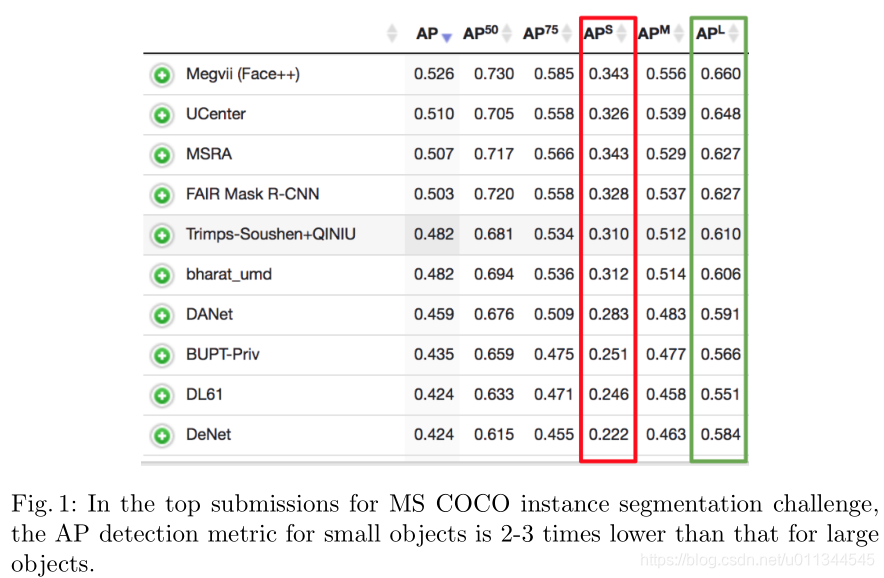
检测图像中的物体是当今计算机视觉研究的基本任务之一,因为它通常是许多现实世界应用的起点,包括机器人和自动驾驶汽车,卫星和航空图像分析,以及器官的定位和大量的医学图像。而物体检测这一重要问题最近经历了很多改进。 MS COCO物体检测竞赛的top-1解决方案,已经从2015年的平均精度(AP)0.373 发展到2017年的0.525(IoU = .50:.05:.95这是一项主要挑战在MS COCO实例分段挑战的背景下,可以在实例分割问题中观察到类似的进展。尽管有这些改进,但现有解决方案通常在小型物体上表现不佳,其中小型物体在MS COCO的情况下如表1中所定义。从小物体和大物体的检测之间的性能的显着差异可以明显看出。例如,参见图1,其列出了MS COCO实例分段挑战的最高排名提交。在实例分割任务中也观察到类似的问题。例如,请参见图2中当前最先进模型Mask-RCNN的样本预测,其中模型错过了大多数小对象。
数据集:http://cocodataset.org/#detection-leaderboard

小物体检测在许多下游任务中至关重要。在汽车的高分辨率场景照片中检测小物体或远处的物体是安全地部署自驾车的必要条件。许多物体,例如交通标志或行人,在高分辨率图像上几乎看不到。在医学成像中,早期检测肿块和肿瘤对于进行准确的早期诊断至关重要,因为这些元素很容易只有几个像素。通过在材料表面上可见的小缺陷的定位,自动工业检查还可以受益于小物体检测。另一个应用是卫星图像分析,其中必须有效地注释诸如汽车,船舶和房屋之类的物体。平均每像素分辨率为0.5-5m,这些对象的大小只有几个像素。换句话说,小物体检测和分割需要更多关注,因为在现实世界中部署了更复杂的系统。因此,我们提出了一种改进小物体检测的新方法。

我们专注于最先进的物体探测器,Mask R-CNN [18],在具有挑战性的数据集MS COCO上。我们注意到该数据集关于小对象的两个属性。首先,我们观察到在数据集中包含小对象的图像相对较少,这可能会使任何检测模型偏向于更多地关注中型和大型对象。其次,小物体所覆盖的区域要小得多,这意味着小物体的位置缺乏多样性。我们猜想,当物体检测模型出现在图像的较少探索的部分时,难以在测试时间内推广到小物体。
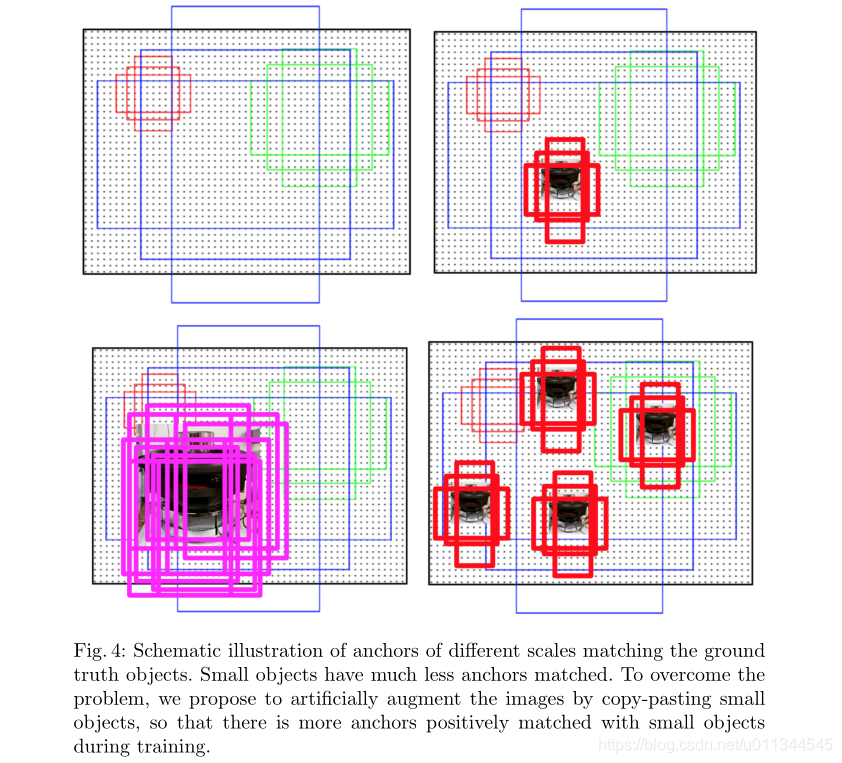
我们通过对包含小对象的图像进行过采样来解决第一个问题。第二个问题是通过在包含小对象的每个图像中多次复制粘贴小对象来解决的。粘贴每个对象时,我们确保粘贴的对象不与任何现有对象重叠。这增加了小物体位置的多样性,同时确保这些物体出现在正确的上下文中,如图3所示。每个图像中小物体数量的增加进一步解决了少量正匹配锚点的问题。我们在第3节中进行了定量分析。总体而言,在MS COCO中与目前最先进的方法Mask R-CNN相比,实例分割的相对改进率为9.7%,小物体的物体检测率为7.1%。
相关工作
目标检测 (Object Detection) :
更快的基于区域的卷积神经网络( Faster region-based convolutional neural network,Faster R-CNN),基于区域的完全卷积网络( Region-based fully convolutional network,R-FCN)和单射击检测器(Single Shot Detector,SSD)是对象检测的三种主要方法,它们根据区域提案是否以及在何处而不同连接。 Faster R-CNN及其变体旨在帮助处理各种对象尺度,因为差异裁剪将所有提议合并为单个分辨率。 然而,这发生在深度卷积网络中,并且所得到的裁剪框可能与对象不完全对齐,这可能在实践中损害其性能。 SSD最近扩展到解卷积单发探测器(Deconvolutional Single Shot Detector,DSSD),它通过解码器部分中的转置卷积对SSD的低分辨率特征进行上采样,以增加内部空间分辨率。 类似地,特征金字塔网络( Feature Pyramid Network,FPN)利用解码器类型的子网络扩展 Faster R-CNN。

实例分割(Instance Segmentation):
实例分割不仅仅是对象检测,还需要预测每个对象的精确掩码。 多任务网络级联(Multi-Task Network Cascades,MNC)[9]构建了一系列预测和掩模细化。 完全卷积实例感知语义分割(Fully convolutional instance-aware semantic segmentation,FCIS)[23]是一个完全卷积模型,它计算每个感兴趣区域共享的位置敏感分数图。 [14],也是一种完全卷积的方法,学习像素嵌入。 Mask R-CNN [18]扩展了FPN模型,其分支用于预测掩模,并为对象检测和实例分割引入了新的差分裁剪操作。
小目标(Small objects):
检测小物体可以通过增加输入图像分辨率[7,26]或通过融合高分辨率特征与低分辨率图像[36,2,5,27]的高维特征来解决。 然而,这种使用较高分辨率的方法增加了计算开销,并且没有解决小物体和大物体之间的不平衡。 [22]而是使用生成对抗网络( Generative Adversarial Network,GAN)在卷积网络中构建特征,这些特征在交通标志和行人检测的上下文中的小对象和大对象之间难以区分。 [12]在区域提案网络中使用基于不同分辨率层的不同锚定比例。 [13]通过锚尺寸的正确分数来移动图像特征以覆盖它们之间的间隙。 [6,33,8,19]在裁剪小对象提案时添加上下文。
识别检测小物体的问题
在本节中,我们首先概述了MS COCO数据集和我们实验中使用的对象检测模型。 然后,我们讨论MS COCO数据集的问题以及训练中使用的锚匹配过程,这有助于小对象检测的难度。
MS COCO:
我们试验了MS COCO检测数据集[25]。 MS COCO 2017检测数据集包含118,287个用于训练的图像,5,000个用于验证的图像和40,670个测试图像。 来自80个类别的860,001和36,781个对象使用地面实况边界框和实例掩模进行注释。
在MS COCO检测挑战中,主要评估指标是平均精度(average precision,AP)。 通常,AP被定义为所有召回值的真阳性与所有阳性的比率的平均值。 因为对象需要被定位和正确分类,所以如果预测的掩模或边界框具有高于0.5的交叉结合( intersection-over-union,IoU),则正确的分类仅被计为真正的正检测。 AP分数在80个类别和10个IoU阈值之间取平均值,均匀分布在0.5和0.95之间。 指标还包括跨不同对象尺度测量的AP。 在这项工作中,我们的主要兴趣是关于小物体的AP。
Mask R-CNN:
对于我们的实验,我们使用[16]中的Mask R-CNN实现和ResNet-50 backbone,并调整[17]中提出的线性缩放规则来设置学习超参数。我们使用比[16]中的基线更短的训练计划。我们使用0.01的基本学习率训练分布在四个GPU上的36k迭代模型。为了优化,我们使用随机梯度下降,动量设置为0.9,权重衰减,系数设置为0.0001。在24k和32k迭代之后,在训练期间,学习率按比例缩小0.1倍。所有其他参数保留在[16]的基线Mask R-CNN + FPN + ResNet-50配置中。
在我们的调查中,网络的区域提案阶段尤为重要。我们使用特征金字塔网络( feature pyramid network,FPN)来生成对象提议[24]。它预测了相对于五个尺度(32, 62, 122 , 256, 512)^2和三个纵横比(1, 0.5, 2)的十五个锚箱的对象建议。如果锚具有高于0.7的IoU对抗任何地面实况框,或者如果它具有针对地面实况边界框的最高IoU,则锚接收正标签。

Small object detection by Mask R-CNN on MS COCO
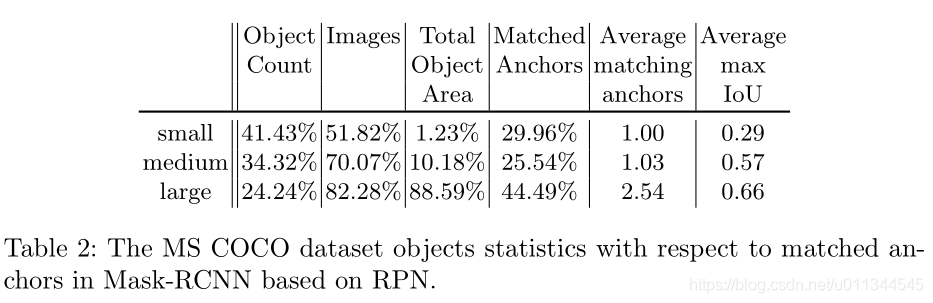
在MS COCO中,训练集中出现的所有对象中有41.43%是小的,而只有34.4%和24.2%分别是中型和大型对象。 另一方面,只有约一半的训练图像包含任何小物体,而70.07%和82.28%的训练图像分别包含中型和大型物体。 请参阅表2中的(Object Count and Images)对象计数和图像。这确认了小对象检测问题背后的第一个问题:使用小对象的示例较少。
通过考虑每个尺寸类别的总对象面积(Total Object Area),可以立即看出第二个问题。 仅有1.23%的带注释像素属于小对象。 中等大小的对象占用面积的8倍以上,占总注释像素的10.18%,而大多数像素,82.28%被标记为大对象的一部分。在该数据集上训练的任何探测器都没有看到足够的小物体情况,包括图像和像素。
如本节前面所述,来自区域提案网络的每个预测锚点如果具有最高的IoU具有地面实况边界框或者如果其具有高于0.7的任何地面实况框的IoU,则接收正标签。这个过程非常适合大型物体,因为跨越多个滑动窗口位置的大型物体通常具有带有许多锚箱的高IoU,而小物体可能仅与具有低IoU的单个锚箱匹配。如表2所列,只有29.96%的正匹配锚与小物体配对,而44.49%的正匹配锚与大物体配对。从另一个角度来看,它意味着每个大对象有2.54个匹配的锚点,而每个小对象只有一个匹配的锚点。此外,正如平均最大(Average Max IoU )IoU度量标准所揭示的那样,即使是小物体的最佳匹配锚箱通常也具有低IoU值。小物体的平均最大IoU仅为0.29,而中型和大型物体的最佳匹配锚点分别为IoU,0.57和0.66的两倍。我们在图中说明了这种现象。 5通过可视化几个例子。这些观察结果表明,小型物体对计算区域建议损失的贡献要小得多,这使得整个网络偏向于大中型物体。
过采样和增强(Oversampling and Augmentation)
我们通过明确解决上一节中概述的MS COCO数据集的小对象相关问题,提高了对象检测器在小对象上的性能。 特别是,我们对包含小对象的图像进行过度采样并执行小对象增强,以鼓励模型更多地关注小对象。 虽然我们使用Mask R-CNN评估所提出的方法,但它通常可用于任何其他对象检测网络或框架,因为过采样和增强都是作为数据预处理完成的。
Oversampling(过采样)
我们通过在训练期间对这些图像进行过采样来解决包含小对象的相对较少图像的问题[4]。 这是一种轻松而直接的方法,可以缓解MS COCO数据集的这一问题并提高小对象检测的性能。 在实验中,我们改变过采样率并研究过采样的影响,不仅对小对象检测,而且对检测中大对象。
Augmentation(增强)
除了过采样之外,我们还引入了专注于小对象的数据集扩充。 MS COCO数据集中提供的实例分割掩码允许我们从其原始位置复制任何对象。 然后将副本粘贴到不同的位置。 通过增加每个图像中的小对象的数量,匹配的锚的数量增加。 这反过来又改善了小对象在训练期间计算RPN的损失函数的贡献。
在将对象粘贴到新位置之前,我们对其应用随机转换。 我们通过将对象大小改变±20%并将其旋转±15°来缩放对象。 我们只考虑非遮挡对象,因为粘贴不相交的分割遮罩与中间不可见的部分通常会导致不太逼真的图像。 我们确保新粘贴的对象不与任何现有对象重叠,并且距图像边界至少五个像素。
在图4中,我们以图形方式说明了所提出的增强策略以及它如何在训练期间增加匹配锚点的数量,从而更好地检测小物体。
Experimental Setup(实验参数设置)
Oversampling
在第一组实验中,我们研究了包含小物体的过采样图像的影响。 我们改变了两个,三个和四个之间的过采样率。 我们创建了多个图像副本,而不是实际的随机过采样,这些图像与小对象脱机以提高效率。
Augmentation
在第二组实验中,我们研究了使用增强对小物体检测和分割的影响。 我们复制并粘贴每个图像中的所有小对象一次。 我们还用小物体对图像进行过采样,以研究过采样和增强策略之间的相互作用。
我们测试了三种设置。 在第一个设置中,我们用带有复制粘贴的小对象的小对象替换每个图像。 在第二个设置中,我们复制这些增强图像以模拟过采样。 在最终设置中,我们保留原始图像和增强图像,这相当于用小对象对图像进行过采样两倍,同时用更小的对象扩充复制的副本。
Copy-Pasting Strategies
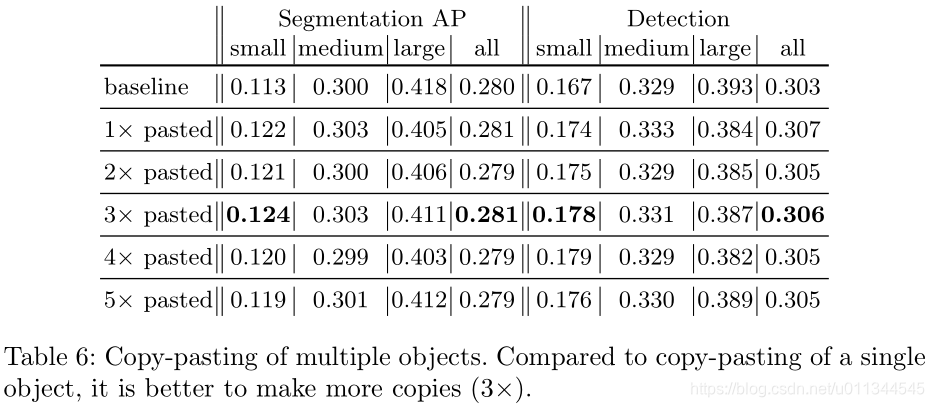
有不同的方法来复制粘贴小对象。 我们考虑三种不同的策略。 首先,我们在图像中选择一个小对象,并在随机位置复制粘贴多次。 其次,我们选择了许多小物体,并在任意位置复制粘贴这些物体一次。 最后,我们在随机位置多次复制粘贴每个图像中的所有小对象。 在所有情况下,我们使用上面第三个增强设置; 也就是说,我们保留原始图像和增强副本。
Pasting Algorithms
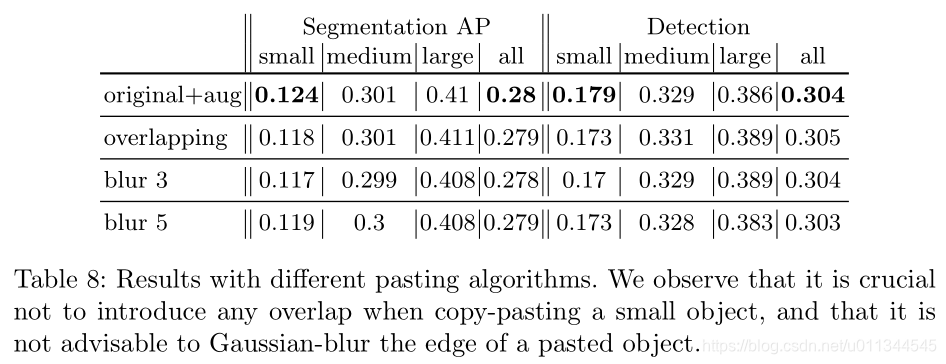
粘贴小对象的副本时,有两件事需要考虑。 首先,我们必须确定粘贴的对象是否会与任何其他对象重叠。 虽然我们选择不引入任何重叠,但我们通过实验验证它是否是一个好策略。 其次,是否执行额外的过程来平滑粘贴对象的边缘是一种设计选择。 我们试验具有不同滤波器尺寸的边界的高斯模糊是否可以帮助比较没有进一步处理。
Result and Analysis
Oversampling
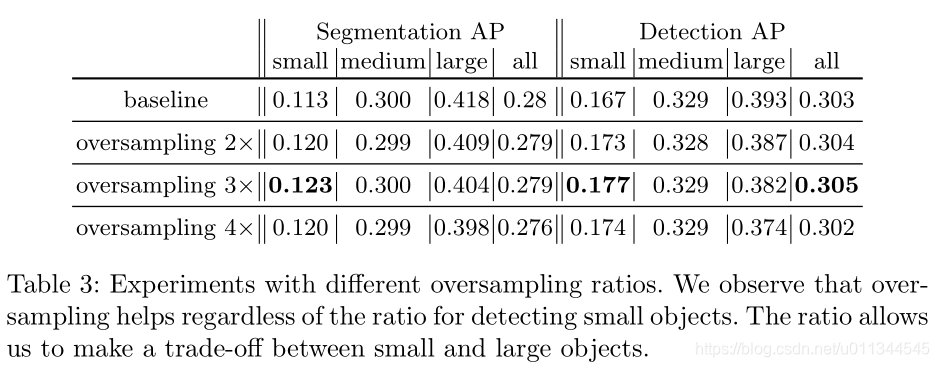
通过在训练期间更频繁地对小物体图像进行采样(参见表3),可以改善小物体分割和检测上的AP。 通过3倍过采样观察到最大增益,这使小物体的AP增加1%(相当于8.85%的相对改善)。 虽然中等对象尺度上的性能受影响较小,但是大对象检测和分割性能始终受到过采样的影响,这意味着必须基于小对象和大对象之间的相对重要性来选择该比率。
Augmentation
在表4中,我们使用所提出的增强和过采样策略的不同组合来呈现结果。当我们用包含更多小对象(第二行)的副本用小对象替换每个图像时,性能显着下降。当我们将这些增强图像过采样2倍时,小物体的分割和检测性能重新获得了损失,尽管总体性能仍然比基线差。当我们在增强验证集上而不是原始验证集上评估此模型时,我们看到小对象增强性能(0.161)增加了38%,这表明训练有素的模型有效地过度拟合“粘贴”小物体但是不一定是原来的小物件。我们认为这是由于粘贴的伪影,例如不完美的对象遮罩和与背景的亮度差异,这些神经网络相对容易发现。通过将过采样和增强与p = 0.5(original+aug)的概率相结合来实现最佳结果,原始对象与增强小对象的比率为2:1。这种设置比单独过采样产生了更好的结果,证实了所提出的粘贴小物体策略的有效性。
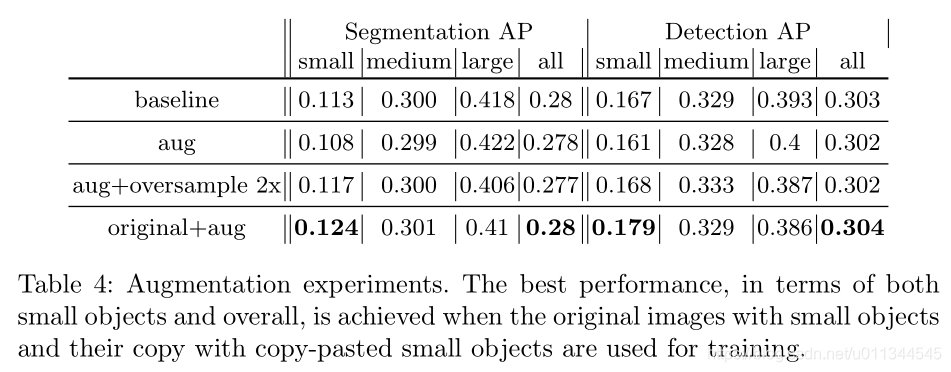
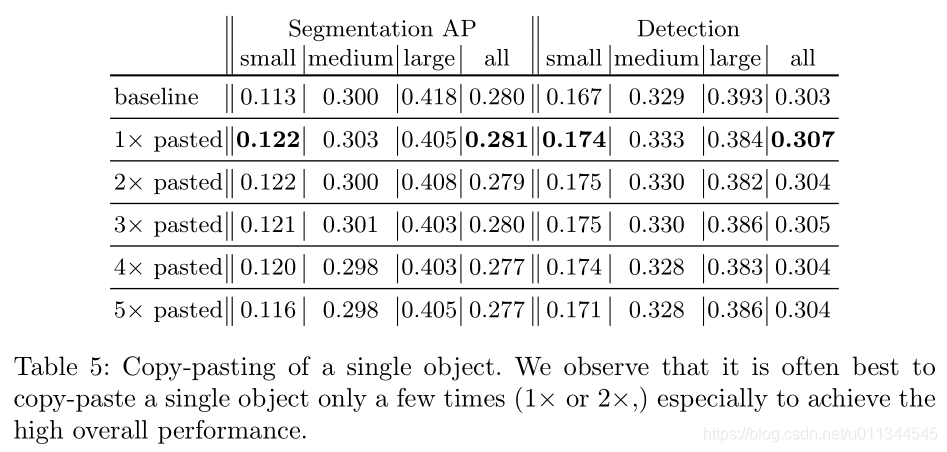
Copy-Pasting strategies

Pasting Algorithms
Conclusion(结论)
我们研究了小物体检测的问题。我们发现小物体平均精度差的原因之一是训练数据中缺少小物体的表示。对于现有的现有技术的物体检测器尤其如此,该物体检测器需要存在足够的物体以使预测的锚点在训练期间匹配。我们提出了两种策略来扩充原始的MS COCO数据库来克服这个问题。首先,我们展示了在训练过程中对包含小物体的图像进行过采样,可以轻松提高小物体的性能。其次,我们提出了一种基于复制粘贴小对象的增强算法。我们的实验证明,与通过掩模R-CNN在MS COCO上获得的现有技术相比,小物体的实例分割相比改善了9.7%,物体检测为7.1%。如实验所证实的,所提出的一组增强方法提供了对小物体和大物体的预测质量之间的权衡。
References
- Abouelela, A., Abbas, H.M., Eldeeb, H., Wahdan, A.A., Nassar, S.M.: Automated
vision system for localizing structural defects in textile fabrics. Pattern recognition
letters 26(10), 1435–1443 (2005) - Bell, S., Lawrence Zitnick, C., Bala, K., Girshick, R.: Inside-outside net: Detecting
objects in context with skip pooling and recurrent neural networks. In: Proceedings
of the IEEE conference on computer vision and pattern recognition. pp. 2874–2883
(2016) - Bottema, M.J., Slavotinek, J.P.: Detection and classification of lobular and dcis
(small cell) microcalcifications in digital mammograms. Pattern Recognition Let-
ters 21(13-14), 1209–1214 (2000) - Buda, M., Maki, A., Mazurowski, M.A.: A systematic study of the class imbalance
problem in convolutional neural networks. arXiv preprint arXiv:1710.05381 (2017) - Cao, G., Xie, X., Yang, W., Liao, Q., Shi, G., Wu, J.: Feature-fused ssd: fast
detection for small objects. In: Ninth International Conference on Graphic and
Image Processing (ICGIP 2017). vol. 10615, p. 106151E. International Society for
Optics and Photonics (2018) - Chen, C., Liu, M.Y., Tuzel, O., Xiao, J.: R-cnn for small object detection. In: Asian
conference on computer vision. pp. 214–230. Springer (2016) - Chen, X., Kundu, K., Zhu, Y., Berneshawi, A.G., Ma, H., Fidler, S., Urtasun, R.:
3d object proposals for accurate object class detection. In: Advances in Neural
Information Processing Systems. pp. 424–432 (2015) - Cheng, P., Liu, W., Zhang, Y., Ma, H.: Loco: Local context based faster r-cnn for
small traffic sign detection. In: International Conference on Multimedia Modeling.
pp. 329–341. Springer (2018) - Dai, J., He, K., Sun, J.: Instance-aware semantic segmentation via multi-task net-
work cascades. In: Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition. pp. 3150–3158 (2016) - Dai, J., Li, Y., He, K., Sun, J.: R-fcn: Object detection via region-based fully
convolutional networks. In: Advances in neural information processing systems.
pp. 379–387 (2016) - Deshmukh, V.R., Patnaik, G., Patil, M.: Real-time traffic sign recognition system
based on colour image segmentation. International Journal of Computer Applica-
tions 83(3) (2013) - Eggert, C., Zecha, D., Brehm, S., Lienhart, R.: Improving small object proposals
for company logo detection. In: Proceedings of the 2017 ACM on International
Conference on Multimedia Retrieval. pp. 167–174. ACM (2017) - Fang, L., Zhao, X., Zhang, S.: Small-objectness sensitive detection based on shifted
single shot detector. Multimedia Tools and Applications pp. 1–19 (2018) - Fathi, A., Wojna, Z., Rathod, V., Wang, P., Song, H.O., Guadarrama, S., Murphy,
K.P.: Semantic instance segmentation via deep metric learning. arXiv preprint
arXiv:1703.10277 (2017) - Fu, C.Y., Liu, W., Ranga, A., Tyagi, A., Berg, A.C.: Dssd: Deconvolutional single
shot detector. arXiv preprint arXiv:1701.06659 (2017) - Girshick, R., Radosavovic, I., Gkioxari, G., Dollár, P., He, K.: Detectron. https:
//github.com/facebookresearch/detectron (2018) - Goyal, P., Dollár, P., Girshick, R.B., Noordhuis, P., Wesolowski, L., Kyrola, A.,
Tulloch, A., Jia, Y., He, K.: Accurate, large minibatch sgd: Training imagenet in
1 hour. CoRR abs/1706.02677 (2017) - He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Computer Vision
(ICCV), 2017 IEEE International Conference on. pp. 2980–2988. IEEE (2017) - Hu, P., Ramanan, D.: Finding tiny faces. In: Computer Vision and Pattern Recog-
nition (CVPR), 2017 IEEE Conference on. pp. 1522–1530. IEEE (2017) - Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A., Fathi, A., Fischer, I.,
Wojna, Z., Song, Y., Guadarrama, S., et al.: Speed/accuracy trade-offs for modern
convolutional object detectors. In: IEEE CVPR. vol. 4 (2017) - Kampffmeyer, M., Salberg, A.B., Jenssen, R.: Semantic segmentation of small ob-
jects and modeling of uncertainty in urban remote sensing images using deep con-volutional neural networks. In: Proceedings of the IEEE conference on computer
vision and pattern recognition workshops. pp. 1–9 (2016) - Li, J., Liang, X., Wei, Y., Xu, T., Feng, J., Yan, S.: Perceptual generative adver-
sarial networks for small object detection. In: IEEE CVPR (2017) - Li, Y., Qi, H., Dai, J., Ji, X., Wei, Y.: Fully convolutional instance-aware semantic
segmentation. In: 2017 IEEE Conference on Computer Vision and Pattern Recog-
nition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. pp. 4438–4446 (2017) - Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature
pyramid networks for object detection. In: CVPR. vol. 1, p. 4 (2017) - Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P.,
Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference
on computer vision. pp. 740–755. Springer (2014) - Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.:
Ssd: Single shot multibox detector. In: European conference on computer vision.
pp. 21–37. Springer (2016) - Menikdiwela, M., Nguyen, C., Li, H., Shaw, M.: Cnn-based small object detection
and visualization with feature activation mapping. In: 2017 International Confer-
ence on Image and Vision Computing New Zealand, IVCNZ 2017, Christchurch,
New Zealand, December 4-6, 2017. pp. 1–5 (2017) - Modegi, T.: Small object recognition techniques based on structured template
matching for high-resolution satellite images. In: SICE Annual Conference, 2008.
pp. 2168–2173. IEEE (2008) - Nagarajan, M.B., Huber, M.B., Schlossbauer, T., Leinsinger, G., Krol, A.,
Wismüller, A.: Classification of small lesions in dynamic breast mri: eliminating the
need for precise lesion segmentation through spatio-temporal analysis of contrast
enhancement. Machine vision and applications 24(7), 1371–1381 (2013) - Ng, H.F.: Automatic thresholding for defect detection. Pattern recognition letters
27(14), 1644–1649 (2006) - Ouyang, W., Wang, X.: Joint deep learning for pedestrian detection. In: Proceed-
ings of the IEEE International Conference on Computer Vision. pp. 2056–2063
(2013) - Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detec-
tion with region proposal networks. In: Advances in neural information processing
systems. pp. 91–99 (2015) - Ren, Y., Zhu, C., Xiao, S.: Small object detection in optical remote sensing images
via modified faster r-cnn. Applied Sciences 8(5), 813 (2018) - Sermanet, P., LeCun, Y.: Traffic sign recognition with multi-scale convolutional
networks. In: Neural Networks (IJCNN), The 2011 International Joint Conference
on. pp. 2809–2813. IEEE (2011) - Wojna, Z., Ferrari, V., Guadarrama, S., Silberman, N., Chen, L.C., Fathi, A.,
Uijlings, J.: The devil is in the decoder. arXiv preprint arXiv:1707.05847 (2017) - Yang, F., Choi, W., Lin, Y.: Exploit all the layers: Fast and accurate cnn object
detector with scale dependent pooling and cascaded rejection classifiers. In: Pro-
ceedings of the IEEE conference on computer vision and pattern recognition. pp.
2129–2137 (2016)
