Abstract
尽管最近取得了进展,但航拍图像中的目标检测仍然是一项具有挑战性的任务。航拍图像中的特定问题使得检测问题变得更加困难,例如小目标、密集目标、不同大小和不同方向的目标。为了解决小目标检测问题,我们提出了一个名为 “聚焦和检测” 的两阶段物体检测框架。第一阶段由高斯混合模型监督的目标检测器网络组成,生成构成聚焦区域的目标簇。第二阶段,也是一个目标检测器网络,预测焦点区域内的目标。还提出了不完全框抑制(IBS)方法来克服区域搜索方法的截断效应。结果表明,据作者所知,所提出的两阶段框架在 VisDrone 验证数据集上的 AP 得分为 42.06,超过了文献中报道的所有其他最先进的小目标检测方法。
1. Introduction
目标检测是一项计算机视觉任务,由两个子任务组成,即目标定位和分类。它是基本问题之一,因为许多其他任务都依赖于它,例如图像字幕、目标跟踪、实例分割和场景理解 [1]。因此,它已被研究了很长时间。随着基于深度学习的方法的进步,基于手工特征的方法,如 HOG [2] 和 SIFT [3],已经过时了。 SIFT 和 HOG 特征是低级特征,不能用作分层逐层表示,而深度模型能够将数据表示为抽象表示的分层组合。然而,由于硬件功能的发展,最近的方法变得越来越复杂。在 [4] 中,基于深度学习的方法被定义为各种组件的组合。一般来说,检测网络由主干、颈部和头部组成。在这种情况下,骨干模型是为检测任务提取特征的网络,头部是预测边界框和类别的实际检测模型,颈部位于骨干网络和头部网络之间,融合来自骨干模型不同阶段的特征图。检测头有不同的方法,例如单阶段检测和两阶段检测模型。单阶段检测模型在头部模型中不包含区域生成层 [5],而是直接在密集的位置采样上运行检测。另一方面,两阶段模型利用区域生成网络提取用于边界框回归和分类的目标区域。
空中目标检测可以归类为一般小目标检测问题的一个例子,是一个新兴领域,最近取得了进展。尽管它具有广泛的应用,例如监控、精准农业、军事监控和城市管理 [6,7],但它是最具挑战性的计算机视觉任务之一。早些时候,一些研究提出了为自然图像建立的适应航拍图像的方法 [8,9]。然而,由于这种方法[10],出现了各种困难。首先,在航拍图像中,方向和纵横比可能与自然图像有很大不同。其次,航拍图像中 类内和类间样本的尺度变化 非常严重 [11]。例如,[12] 报告了 MS COCO 和 VisDrone [13] 数据集中“汽车”类的统计数据。它表明,在 VisDrone 数据集中,“汽车”对象的大小方差几乎是 MS COCO 数据集的五倍。第三,航拍图像中的物体小且位置密集。例如,在 VisDrone 检测数据集 [14] 的单个图像中可能存在多达 902 个对象。此外,航拍图像中存在类不平衡问题[14],这使得样本数量较少的类的小目标检测问题更加困难。因此,小目标检测任务需要专门解决上述问题的方法。
区域搜索是一种强大的小目标检测方法,旨在寻找并关注可能包含物体的区域 [15,16]。由于航空图像由密集和小的物体组成,因此我们在本文中专注于空中目标检测问题的区域搜索。为此,我们提出了一个由两个阶段组成的框架,即焦点和检测阶段。在第一阶段,要聚焦的区域由受高斯混合模型监督的检测器确定。第二阶段,由这些主要是目标簇的区域提供数据,预测这些区域内的对象。在合并对这些区域的预测时,NMS 和 提出的 IBS 方法用于消除重叠和截断的边界框。
我们的贡献如下:
• 我们提出了一个框架,即基于区域搜索的航拍图像中小目标检测的 “Focus&Detect“。
• 我们提出了一种使用高斯混合模型生成目标聚类的方法,其中生成的聚类尺度归一化。
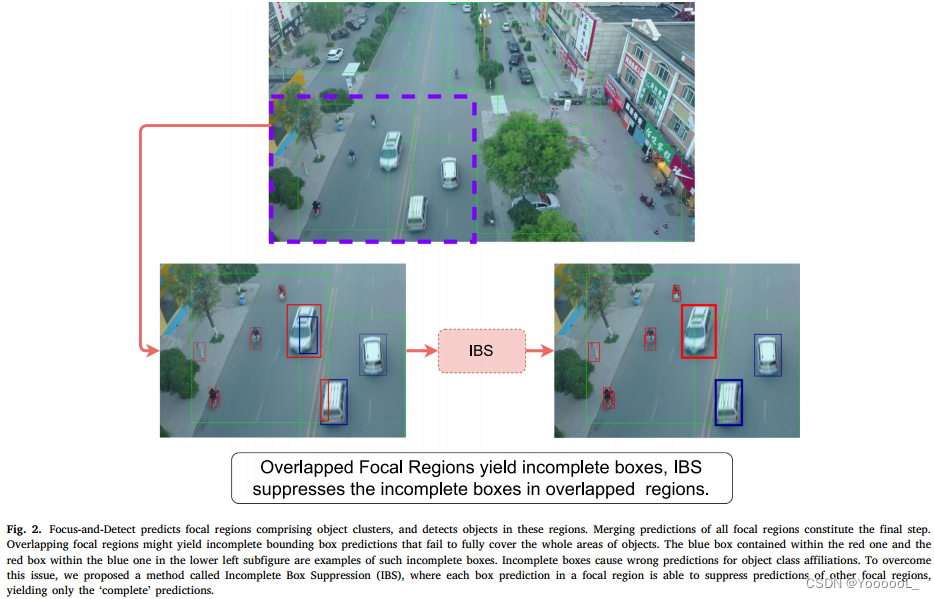
• 我们还提出了“不完整框抑制”(IBS) 方法 来抑制 由重叠焦点区域引起的不完整框。
• 我们提出的方法在 VisDrone 验证集上获得 42.06 AP 分数,在 UAVDT 测试集上获得 54.16 AP@70 分数。据我们所知,我们的方法优于 VisDrone 数据集文献中报道的最先进的小物体检测方法。
2. Related work
在本节中,我们简要回顾了目标检测、小目标检测和航拍图像中目标检测方向的相关工作。
2.1. Object detection
目标检测文献中的最新方法通常采用强大的骨干模型,例如 ResNet [17]、Hourglass [18] 和 ResNeXt [19]。基于特征金字塔网络 [20] 的架构是颈部模型的主要选择。文献中有Faster-RCNN[5]、Mask-RCNN[21]、Cascade-RCNN[22]等多阶段头部模型。 Faster R-CNN 通过区域生成网络 (RPN) 生成候选框。 Mask R-CNN 扩展了 Faster R-CNN 以同时执行检测和分割任务。另一方面,YOLOv3 [23]、SSD [24]、GFL [25] 和 RetinaNet [26] 是单阶段检测器的示例。单阶段检测器省略了候选框阶段,并对密集的位置样本进行检测。
最近的两阶段方法包括基于 RPN [5] 的模块来生成区域建议。Anchor 锚点是目标检测文献中的一个替代概念,代表预定义的边界框,这些边界框将与目标的真值边界框相匹配。一些研究提出了 anchor-free无锚方法 来避免使用锚的计算成本 [27,28]。基于深度学习的目标检测方法的一个关键组成部分是损失函数。它主要由对应于回归和分类损失的两项组成[5]。回归和分类分支是目标检测器的最终模块,它们分别预测目标的定位和分类。最后,非最大抑制 (NMS) 及其变体 [29,30] 在目标检测器的工作流程中发挥了重要作用,因为目标检测器通常会生成大量冗余预测,而 NMS 用于减少冗余。随着这些组件的改进,通用目标检测已经取得了很大进展 [31,32],而小目标检测仍然需要改进才能获得令人满意的检测性能 [4]。采用对中型或大型物体表现足够好的目标检测器,不能对面积小于 32×32 像素的小目标产生足够的性能,如 [33] 中所述。例如,表明最近提出的 DETR [34] 检测性能对于小目标没有达到预期的水平,而 DETR 在 MS COCO [33] 数据集上的性能优于 Faster R-CNN [5]。
2.2. Small object detection
小目标检测任务是一个重要的计算机视觉问题,在自动驾驶、基于无人机的成像和监控等各个领域都有应用。尽管它是众多领域中不同计算机视觉任务的重要工具,但当前方法的性能并未达到预期水平。尽管如此,由于 图像上小目标覆盖区域的信息不足、小目标定位的高可能性 以及 适用于中型和大型目标 等问题,大多数目标检测方法都在与小目标作斗争[1].
为了解决小物体检测的信息不足问题,[35 Towards precise supervision of feature super-resolution for small object detection] 使用超分辨率技术来提高 Faster R-CNN 的性能,而 [36] 在遥感图像上使用超分辨率 GAN。
增加输入的分辨率可以为小物体产生更好的性能。因此,还提出了一些简单的方法,例如使用图像金字塔作为输入来提高检测小人脸的性能 [37]。然而,这些方法不能有效地扩展。
在[38]中,提出了一种双流网络,它利用多尺度表示和注意力机制。另一项研究 [39] 除了从 SSD 模型获得的多尺度表示之外还使用上下文信息。 Pan 等人 [40] 提出了一种多尺度特征融合方案来改进 SSD 模型上的小目标检测。在另一项研究 [41] 中,SSD 模型通过特征融合和膨胀卷积进行了修改,提高了检测性能。
另一方面,一些方法专注于使用各种技术改进区域提议阶段,例如 改进锚 [42] 和 增加小目标的样本 [43]。在 [44 HybridNet: A fast vehicle detection system for autonomous driving] 中,作者提出了一种混合模型,该模型 同时使用区域建议 和 密集检测头 来提高性能。
2.3. Object detection in aerial images
空中图像构成了目标检测最困难的情况之一,因为它们主要包含小目标,不同类别的样本数量之间存在很大差异 以及 类间和类内的高尺度方差。为了缓解这些困难,先前提出了许多方法。例如,在[45]中 针对类不平衡问题 提出了一种自适应增强方法,称为AdaResampling。在[46]中,提出了一种 hard chip mining硬芯片挖掘方法 作为航拍图像的数据增强。此外,[11 Spatial attention for multi-scale feature refinement for object detection]提出了对获取多尺度特征的改进,以减少尺度方差对目标检测的影响。
由于航拍图像主要由小而密集的物体组成,因此一些方法侧重于改进区域搜索 [15,16,46–51]。例如,[48]提出了 基于tiling平铺的方法 来实时检测航拍图像中的行人和车辆。在 [16] 中,困难的聚类区域是使用均值偏移算法确定的,以提供给目标检测器。 [50 AMRNet: Chips augmentation in aerial images object detection] 提出了三种基于裁剪的增强方法,即马赛克增强、自适应裁剪和 掩码重采样。在 [12] 中,提出了一种基于 FPN [20] 的自适应图像裁剪方法来解决航拍图像中的尺度挑战。 [47]构造密度图以确定要裁剪的区域。然后将这些裁剪以及整个图像提供给目标检测器。 [15]利用聚类来获得图像裁剪。在用这些裁剪馈入目标检测器之前,该方法通过确定目标的适当比例来重新缩放它们,以避免性能下降。与 [15,47] 相反,我们的方法仅利用预测区域,而不是对整个图像进行检测。此外,[47] 使用密度图生成感兴趣区域,这不会直接对对象尺度进行归一化。 [15] 利用子网络来预测检测到的集群的规模,这意味着额外的计算。另一方面,高斯混合模型提供了跨预测区域的尺度归一化,无需额外计算,因为将预测区域的大小调整为固定大小,会产生每个混合分量的均值偏移以及边界框的归一化结果。
与之前的研究不同,我们建议使用高斯混合模型(GMM)进行区域搜索。此外,我们提出了不完整框抑制 (IBS),以抑制在 GMM 监督下由第一个检测器生成的重叠区域内的不完整框。图 2 展示了所提出的 IBS 方法的贡献。
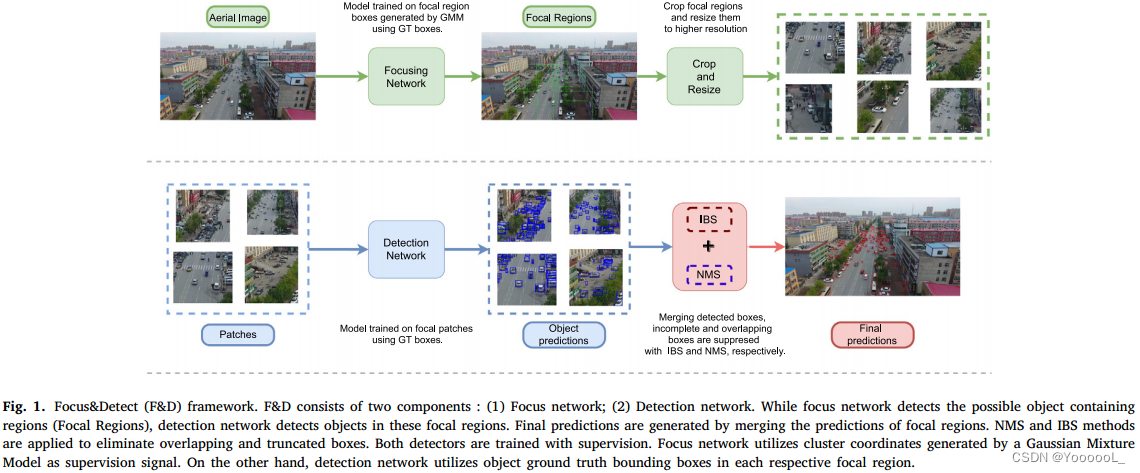
3. Focus-and-detect
3.1. Overview
一般来说,航拍图像上的目标检测性能受到小目标、目标视角变化、遮挡和截断的阻碍。使用高分辨率图像作为输入是解决小物体检测问题的最简单方法之一。不幸的是,高分辨率图像给深度神经网络带来了无法承受的计算成本。使用聚焦机制和提高焦点区域的分辨率具有这种简单方法的优点,但计算成本较低。如图 1 所示,航空图像的检测包括两个阶段:检测由目标簇组成的焦点区域的焦点网络,检测焦点区域中物体的检测网络。合并预测后应用后处理方法。具体来说,我们提出了不完整框抑制 (IBS) 机制来抑制来自重叠焦点区域的不完整框。我们还使用标准的非最大抑制 (NMS) 在合并预测框后抑制重叠框。