ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image
Abstract:
由于低分辨率和类似背景的目标,航空图像中小目标的检测仍然是一个难题。随着目标检测技术的最新发展,已经开发出高效和高性能的检测器技术。其中YOLO系列是具有代表性的目标检测方法,轻巧且性能好。在本文中,我们提出了一种通过修改 YOLOv5 来提高航拍图像中小目标检测性能的方法。通过应用第一个有效的通道注意模块对主干进行修改,并提出了通道注意金字塔方法。我们提出了一种有效的通道注意力金字塔 YOLO (ECAP-YOLO)。其次,为了优化小目标的检测,我们去掉了检测大目标的模块,增加了一个检测层来寻找更小的目标,降低了检测小目标的计算能力,提高了检测率。最后,我们使用转置卷积代替上采样。将本文提出的方法与原始 YOLOv5 进行比较,使用 VEDAI 数据集时 mAP 的性能提高了 6.9%,在 xView 数据集中检测小型汽车时提高了 5.4%,在检测小型车辆和小型船舶类别时提高了 2.7% DOTA 数据集,在Arirang数据集中寻找小型车时大约为 2.4%。
1. Introduction
基于深度学习的目标检测领域的研究一直在稳步进行[1]。目标检测一般由多标签分类和边界框回归组成,可分为单阶段检测器和两阶段检测器。在单阶段检测器的情况下,同时执行用于确定目标位置的定位和用于识别对象的分类,而两阶段目标检测 [2-4] 是一种顺序执行这两项的方法。在这方面,单阶段目标检测具有比二阶段目标检测更快的优势。
对于航拍图像来说,一幅图像具有很高的分辨率,为了在深度学习网络中使用一张航拍图像,必须根据深度学习网络的输入大小对图像进行分割。采用单阶段目标检测技术是因为需要相对较高的速度来检测数量增加的图像。有各种深度学习网络,如 SSD [5]、EfficientDet [6] 和 YOLO 系列 [7-10],用于单阶段目标检测。
空中检测是一个具有挑战性的问题,因为它难以在低空间分辨率下检测到像素数量少的目标,并且目标往往与背景信息相似。此外,现有的目标检测方法针对MS COCO数据集[11]和PASCAL VOC数据集[12]等常见物体的检测进行了优化。在本文中,我们旨在优化网络以在空中检测中找到小目标,并 通过使用通道注意力 来提高检测率。对于DOTA数据集[13]、VEDAI数据集[14]、xView数据集[15]和Arirang数据集[16],将现有YOLOv5的结果与提出方法的结果进行了比较。
本文的贡献如下:
我们 将高效通道注意力网络(ECA-Net)[17]应用于 YOLOv5,并提出了一种高效的通道注意力金字塔网络。
使用转置卷积 [18] 而不是通过现有的最近邻插值 [19] 进行上采样。与大目标相比,对小目标使用最近邻插值会导致相对更大的信息损失,因此我们使用转置卷积优化上采样。
在现有的 YOLO 中添加了一个用于检测较小物体的检测层。这使得空中小目标检测能够检测到比传统 YOLO 更小的目标。另外,现有的YOLO预测层是设计用来预测大物体、中物体和小物体的。对于空中小物体检测,通过消除发现大型和中间物体的检测层,减少了不必要的计算功耗。
本文提出的 ECAP-YOLO 和 ECAPs-YOLO 在 VEDAI 数据集中的平均精度 (mAP) 提高了 6.9%。在 xView 数据集中,小型车类表现出 5.4% 的提升。 DOTA 数据集显示小型车辆和小型船舶类别提高了 2.7%。ARiRang数据集显示小型车的性能提高了约 2.4%。
本文的其余部分组织如下:第 2 节介绍相关工作,第 3 节描述所提出的技术,第 4 节讨论数据集上的实验结果,最后,第 5 节提供结论和未来工作。
2. Related Work
已经进行了许多关于目标检测的研究[1]。其中,YOLO 是一种具有代表性的单阶段目标检测方法。 YOLO 系列目前以 YOLOv4 为代表的已发表论文中,YOLOv5 已上传至 GitHub。 2.1节介绍了YOLO系列,2.2节介绍了注意力模块。
2.1. YOLO Series
YOLO与当时已有的物体检测最大的区别在于,它具有去掉 region proposal区域生成阶段,在分为 区域生成 和 分类 两个阶段的方法中一次进行目标检测的结构。将图像划分为网格区域后,它首先预测每个网格区域中目标可能存在的区域对应的边界框。接下来,计算表示框可靠性的置信度。 YOLOv1 的网络结构基于 GoogLeNet [20],由 24 个卷积层和两个全连接层组成。
YOLOv2已被用于进行各种实验,以解决YOLOv1的低检测率和相当大的定位误差。首先,删除了所有卷积层中使用的 dropout [21],并实施了批量归一化 [22]。 YOLO 的最后一层使用全连接层,但在 YOLOv2 中,它改为卷积层。这确保了无论输入大小如何,都没有关系。
在 YOLOv2 中,使用锚框,通过预测与锚框数量一样多的类和目标的存在或不存在来稳定训练。 YOLOv2 提出了新的 DarkNet-19。
从 YOLOv3 中,预测了三个不同尺度的框。它预测三个不同尺度的框,并以类似于特征金字塔网络的方式提取特征。添加了几个卷积层,输出是一个 3D 张量。在这种情况下,边界框使用多标签分类和二元交叉熵 [23] 损失而不是现有的 SoftMax。骨干网结构采用Darknet-53。训练使用边界框预测 L2 损失。另一个方面是特征图是从头开始取的,进行了上采样特征图和连接。使用这种方法,可以获得语义信息(即前一层)和细粒度信息(即初始层)。这种方法执行两次,同样的设计再执行一次来预测最终尺度的框。因此,第 3 尺度的预测利用了所有先前的层和早期分割的有意义的信息。锚框通过k-means聚类,随机选取9个簇和3个尺度,将簇均匀划分。
YOLOv4 的最大特点是 Bag of Freebies [24] 和 Bag of Specials。网络主干使用 CSPDarkNet-53 [25] 并使用 空间注意力模块 (SAM) [26]、路径聚合网络 (PAN) [27] 和交叉迭代批量归一化 (CBN) [28]。其中SAM、PAN、CBN稍作修改,使用马赛克增强进行增强。
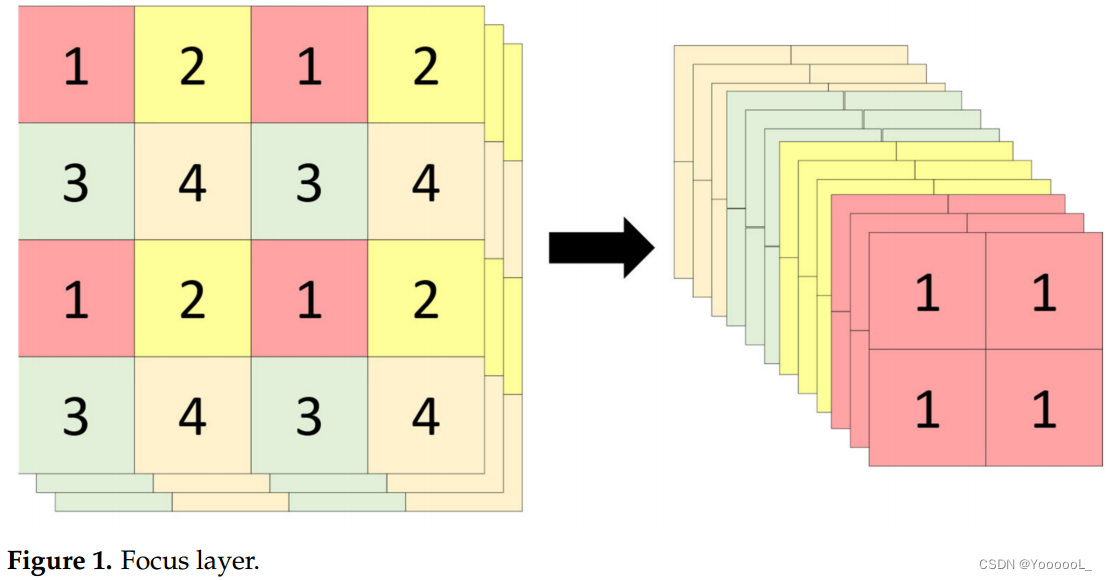
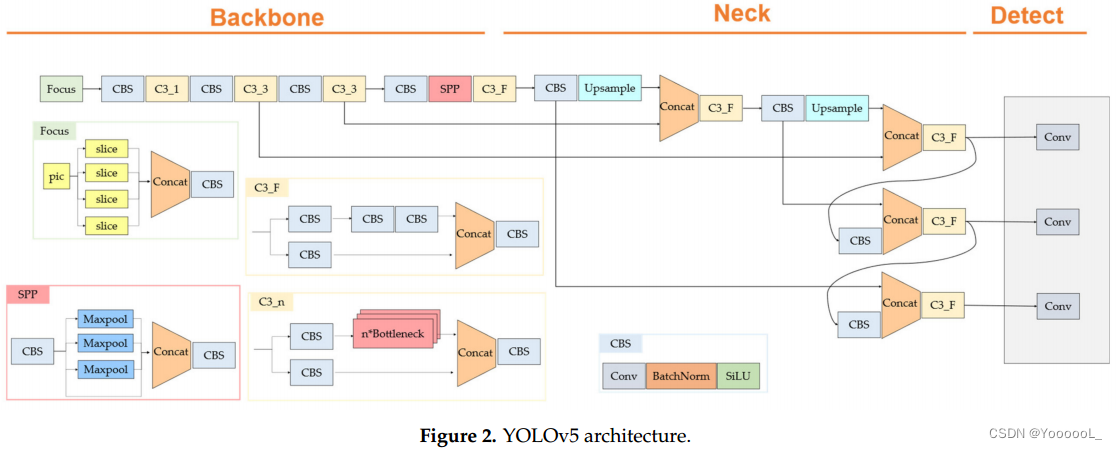
在 YOLOv5 的情况下,它由一个 CBS 块组成,该块包含一个焦点层、卷积、批量归一化、SiLU [29] 和一个 C3 块网络。焦点层就像从空间到深度的转换。(有点像)焦点层如图1所示。这有助于降低2D卷积运算的成本,降低空间分辨率,增加通道数。总体架构如图2所示。
2.2. Attention Module
Jie Hu 等人发表了 Squeeze-and-Excitation Network (SE-Net) [30]。这篇论文的作者提出了挤压和激励的思想,SE-Net 由一个总结每个特征图的全部信息的挤压操作 和 一个缩放每个特征重要性的激励操作组成。这就是所谓的压缩和激励块,相对于参数的增加,模型的性能提升非常大。这样做的好处是模型的复杂性和计算负担不会显著增加。
Qilong等人提出了Efficient Channel Attention Network[17],现有的基于self-attention的CNN模型有助于提高性能,但模型复杂度高。在 SE-Net 的情况下,避免降维 对于训练通道注意力很重要。我们发现 跨通道交互 可以显著降低模型的复杂性,同时保持性能。在ECA-Net的情况下,克服了性能和复杂度之间的权衡,少量参数表现出明显的性能提升效果。他们提出了一种通过高效的一维卷积进行局部跨通道交互而无需降维的方法。 SE-Net如图3a所示,ECA-Net如图3b所示。
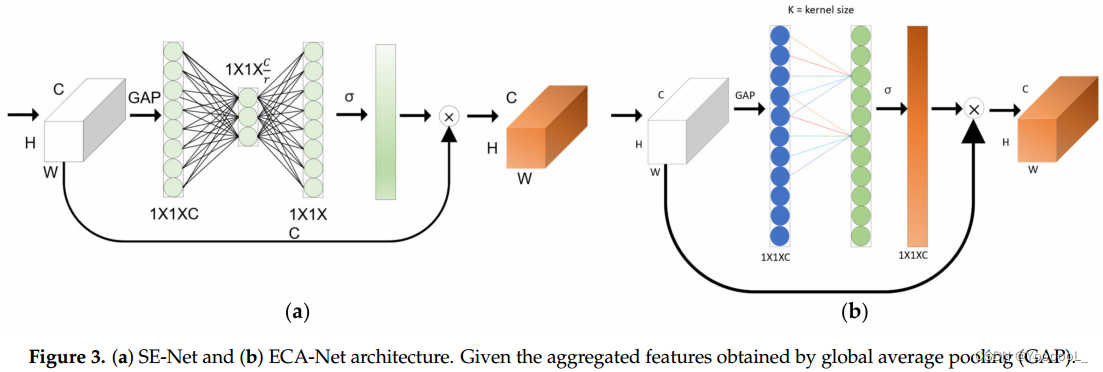
在ECA-Net的情况下,表示为等式(1),其中k表示核大小,C1D表示一维卷积,σ是sigmoid函数。
![]()
3. Proposed Methods
空中小目标检测考虑了三个因素。首先,检测器应该针对小目标进行优化,不应该有不必要的检测。此外,小目标在深度学习网络端应该有很少的信息损失。在本节中,我们提出了高效通道注意力金字塔 YOLO (ECAP-YOLO) 来满足这一点,并在解释了检测层变化、转置卷积和高效通道注意力金字塔之后描述了 ECAP-YOLO 的结构和内容。
3.1. Proposed Method Overview
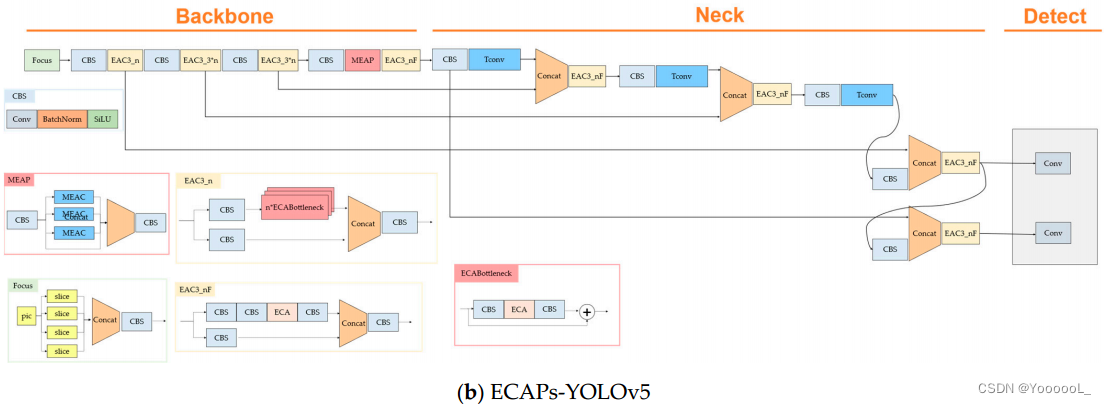
ECAP-YOLOv5 模型使用 EAC34、MEAP 和从现有 YOLOv5 到转置卷积的上采样应用。然后,我们提出了两种情况:ECAPYOLO,其中检测层检测中间物体、小物体和更小的物体; ECAPs-YOLO,它由一个检测层组成,可以发现小物体和更小的物体。 3.2 节描述了转置卷积,3.3 节描述了应用的高效通道注意力,3.4 节描述了高效通道注意力金字塔,3.5 节描述了变化检测层。总体架构如图 4 所示。

3.2. Using Transposed Convolution
在本文中,我们提出了一种 使用转置卷积 而不是通过最近邻插值方法进行上采样 的方法。使用最近邻插值法的上采样方法是一种使用相邻像素填充空白的上采样方法。但是在小目标的情况下,由于像素数比较少,如果只做上采样,周围的背景信息会混杂。转置卷积是一种旨在学习如何以最佳方式对网络进行上采样的方法。转置卷积不使用预定义的插值方法,并且可以在上采样期间进行学习。它可以学习如何在对特征图进行上采样时执行它。在这方面,语义分割的解码器恢复了原始图像大小。本文利用转置卷积 减少特征图中小目标上采样时的信息损失,学习上采样方法。
3.3. Efficient Channel Attention Applied
高效的通道注意力以低成本实现性能提升。这被应用于 YOLOv5 以确定最佳定位以提高性能。 YOLOv5 的高效通道注意力修改的 C3 块在总共四个区域进行了应用和测试,并选择了最佳性能。本章介绍了从 C3 块修改而来的高效通道注意力 C3 (EAC3) 块。在本文中,采用并使用了EAC34。在EAC3_n中,n表示重复一个块的次数。在EAC3_F中,F没有使用瓶颈结构。EAC31、EAC32、EAC33 和 EAC34 根据 ECA-Net 的位置进行分类。
首先,EAC31 块在求和出现在瓶颈结构之前添加了有效的通道注意力。 EAC3_F EAC3 块的结构如图 5 所示。

第二个 EAC32 在 C3 模块完成后 使用高效的通道注意力。EAC32 的结构如图 6 所示。

第三个 EAC33 是高效的通道注意力进入 C3 模块的一部分而没有瓶颈。 EAC33 模块的结构如图 7 所示。

在 EAC34 的最后一个情况中,瓶颈结构中的卷积模块之间使用了高效的通道注意力。根据4.1节的测试结果,ECA4记录的mAP最高,采用EAC34。 EAC34 的结构如图 8 所示。

3.4. Efficient Channel Attention Pyramid
现有的 YOLOv5 使用空间金字塔池化 (SPP) 网络 [31]。在本文中,我们旨在使用通道注意力来改进 SPP。首先,我们提出了有效的通道注意力金字塔(EAP)。我们通过 应用 ECA-Net 而不是现有的最大值池化层来创建金字塔模型。至于卷积核大小,和现有的YOLOv5的SPP layer一样,设置kernel size为5,9,13然后通过concating进行CBS层。 EAP 的结构如图 9 所示。
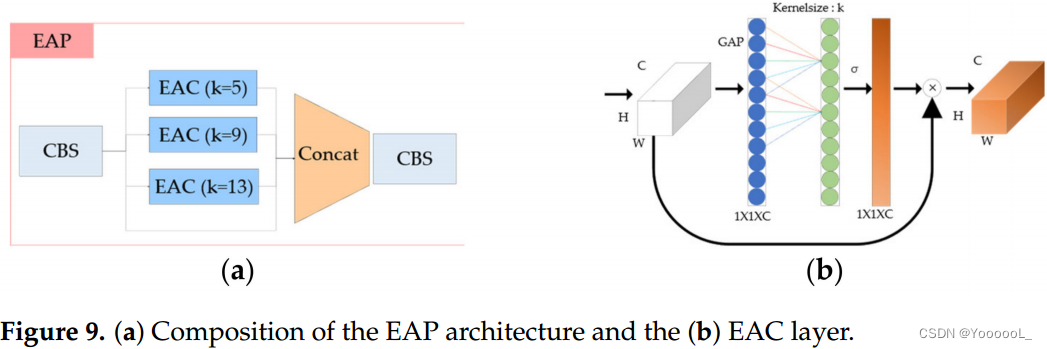
其次,我们提出了 最大值池化高效通道注意力金字塔网络(MEAP)。在 MEAP 的情况下,在有效的通道注意力中 使用全局最大池化 (GMP) 而不是全局平均池化。至于kernel size,和现有的YOLOv5的SPP layer一样,设置kernel size为5,9,13然后通过concating进行CBS层。 EAP 的结构如图 10 所示。
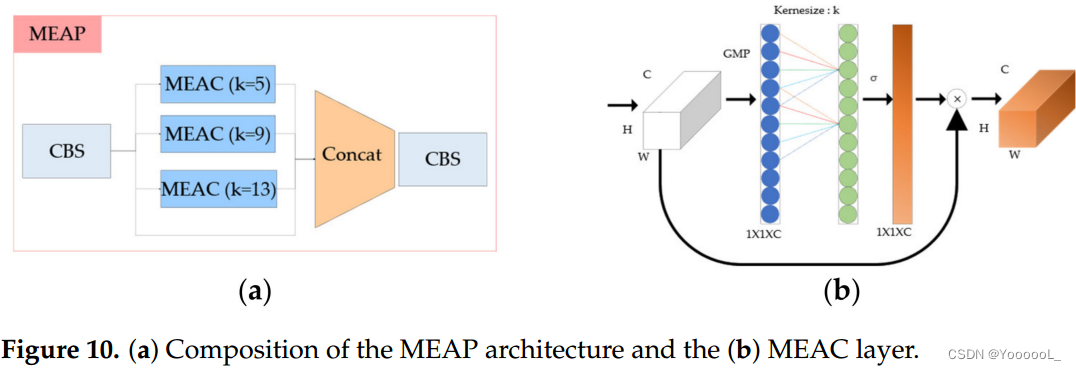
第三,我们提出了 空洞高效通道注意力金字塔网络 (AEAP)。在空洞空间金字塔池化 [32]的情况下,与一般的卷积不同,使用了空洞卷积。在空洞卷积的情况下,内核之间有一个空间。这在与卷积相同的计算成本下提供了更宽的感受野,并且可以确认特征被更密集和突出地提取。使用了 空洞有效通道注意力。在现有的高效通道注意力中进行全局平均池化后,一维卷积的内核大小是固定的,步长是不同的,以创建一个金字塔结构。 EAP 的结构如图 11 所示。
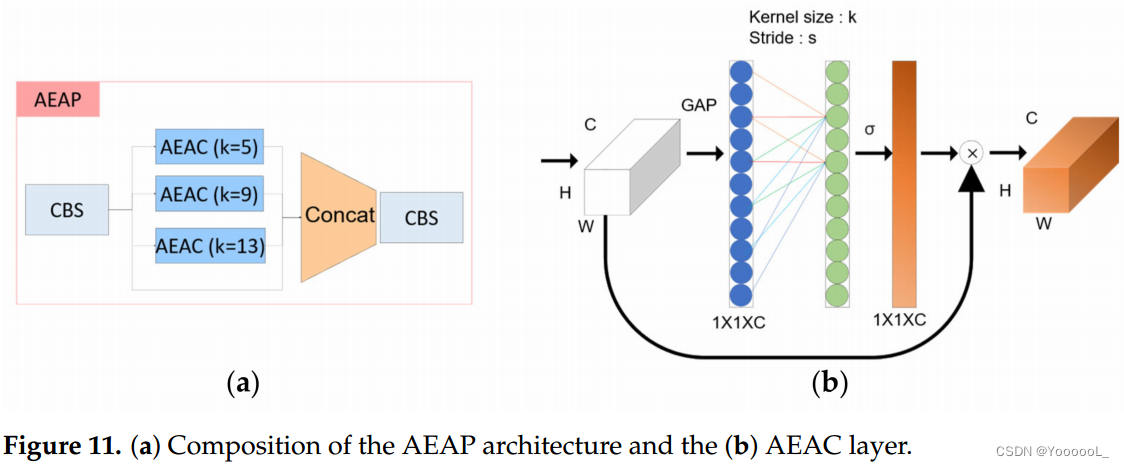
之所以选择 MEAP,是因为根据本文第 4.1 节中描述的实验结果,确认在应用 MEAP 时可以获得最高性能。
3.5. Change Detect Layer
在 YOLO5 中,预测有 3 个检测层。它们分别检测小物体、中物体和大物体。中型和大型目标不需要空中目标检测,因此消除它们可以减少不必要的功耗。在检测层中添加了一个检测层,用于检测非常小的目标。如果添加检测层,则在较大的网格单元中执行检测,从而可以检测较小的对象。与现有检测器模型相比,这增加了计算量,但能够检测更小的目标。
4. Experimental Results and Discussion
在本文中,损失函数和与学习相关的参数等训练方法的执行方式与现有的 YOLOv5 相同。对于实验数据,使用了 VEDAI 数据集、xView 数据集、DOTA 数据集和 Arirang 数据集。图 12 描绘了 YOLOv5 学习方法的示例。在本节中,在解释了每个数据集的特征和组成之后,我们测试了现有的 YOLOv5 和提出的方法,并对结果进行了整理和分析。 YOLOv5 有四个模型:YOLOv5s、YOLOv5m、YOLOv5l 和 YOLOv5x。模型分为深度倍数和宽度倍数。 YOLOv5s的深度倍数在YOLOv5l的基础上是0.33,宽度倍数是0.50倍。 YOLOv5m在YOLOv5l的基础上深度倍数为0.67,宽度倍数为0.75。 YOLOv5x,深度倍数为1.33倍,宽度倍数为1.25倍,同样基于YOLOv5l。本文使用的 YOLOv5 是 YOLOv5l 模型。为了训练参数,应用了与现有 YOLOv5 相同的方法和参数。
至于评价方法,评价从精确率、召回率、F1-score和mAP进行。使用等式(2)计算精度和召回率。 TP、FP、TN、FN分别代表真正样本、假正样本、真负样本、假负样本。使用等式(3)计算 F1 分数。
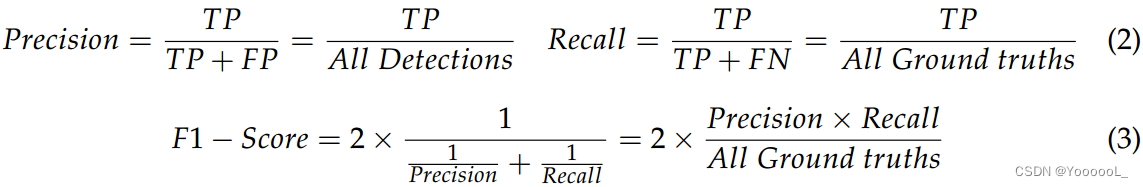
4.1. VEDAI Dataset
VEDAI 数据集 [14] 共包含 1200 张图像、3757 个实例、空间分辨率为 25 厘米、分辨率为 512 × 512、目标尺寸为 8-20 像素宽,共有 3757 个实例。在实验中,数据集由九个类别组成(即汽车、卡车、皮卡、拖拉机、露营车、船、货车、飞机和其他实例),除了这些被设置为其他。 998 个训练数据、124 个验证数据和 124 个测试数据被随机分配。 VEADI 数据集使用 512×512 分辨率的 RGB 数据进行了测试。
修改检测器以针对小目标优化 YOLOv5。在表 1 中,可以观察到根据检测层变化的性能,这与现有的 YOLOv5 不同。在这里,YOLOv5 的检测层一共改为三层。首先,在 YOLOv5 中添加了一个检测层来检测非常小的、小的、中等的和大的目标。其次,添加检测层后,去除大目标检测层,配置如图4a所示,进行实验。第三,将第二种方法中的中间检测层去除,如图4b所示配置两个检测层,然后进行测试。实验结果可以看出,YOLOv5中的第二种方法表现出最好的结果,mAP为29.8%。
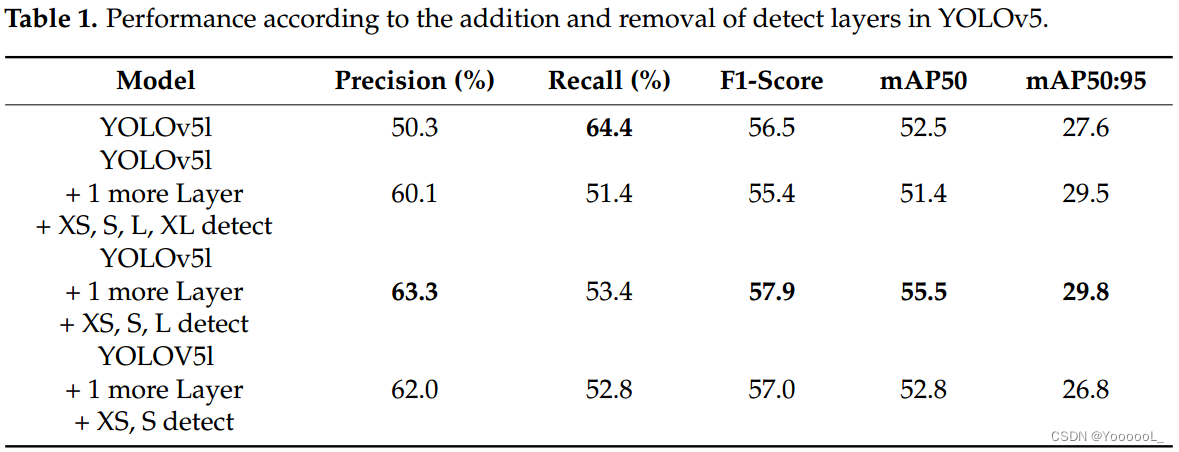
表 2 显示了每个注意力位置的性能结果。当测试 EAC3、EAC32、EAC33 和 EAC34 时,mAP50 显示出 EAC34 的最佳结果,并得到应用。
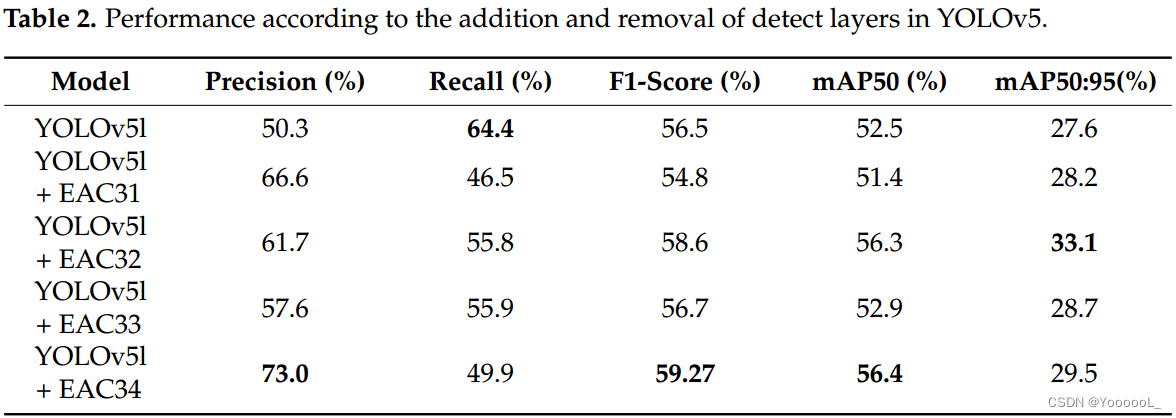
表 3 显示了通过将 EAP、AEAP 和 MEAP 应用于现有 YOLOv5 测试的每个注意力金字塔的性能。在 EAP 的情况下,如图 9 所示,它是一种简单地将具有不同内核大小的通道注意力堆叠为金字塔的方法,内核大小分别为 5、9 和 13。在 AEAP 的情况下,如图在图 11 中,使用了扩大到 2、4 和 6 大小的卷积,同时将内核大小保持在 3。在 AEAP2 的情况下,内核大小保持为 3,并使用大小为 5、9 和 13 的扩张卷积。如图 10 所示,MEAP 与现有的 EAP 相同,但使用了全局最大池化和内核大小为 5、9 和 13 的一维卷积,而不是全局平均池化。表 3 显示 AEAP 具有最好的 mAP50。
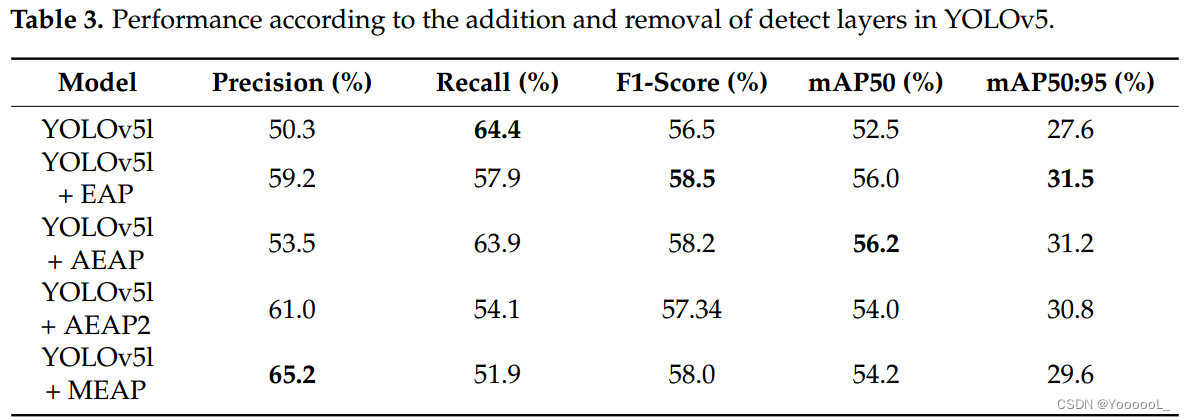
最后,根据所提出的技术的融合结果进行了测试。表 4 显示了结果。使用已有的YOLOv5l和YOLOv5x进行实验,转置卷积,使用注意力金字塔,加检测层找小目标,去掉检测层找大目标,最后,第三种情况找中型目标。这是移除检测层时的情况。表 4 显示 ECAP-YOLOv5l 具有最好的 mAP50。与现有的YOLOv5l相比,ECAP-YOLOv5l的mAP50提高了6.2%,ECAPs-YOLOv5l的mAP50提高了3.5%。
VEDAI 数据集的类别精度和平均精度如表 5 所示。对于汽车,当使用 AEAP 时,它显示最高的 mAP50 为 86.7%。对于卡车,YOLOv5x 为 59.4%,表明 mAP50 最高。皮卡显示最高的 mAP50 与 ECAP-YOLOv5l 为 77%。对于使用 AEAP 的 ECAPs-YOLOv5l,拖拉机和露营车的 mAP50s 最高,分别为 72% 和 61.3%。对于船,ECAP-YOLOv5l 为 35%,表明 mAP50 最高。对于vans,在YOLOv5中使用转置卷积进行上采样的情况为54.7%,表明mAP50最高。对于飞机,使用 EAP 的 ECAPs-YOLOv5l 显示最高的 mAP50 为 92%。在另一类中,YOLOv5x 的 mAP50 最高,为 40.7%。
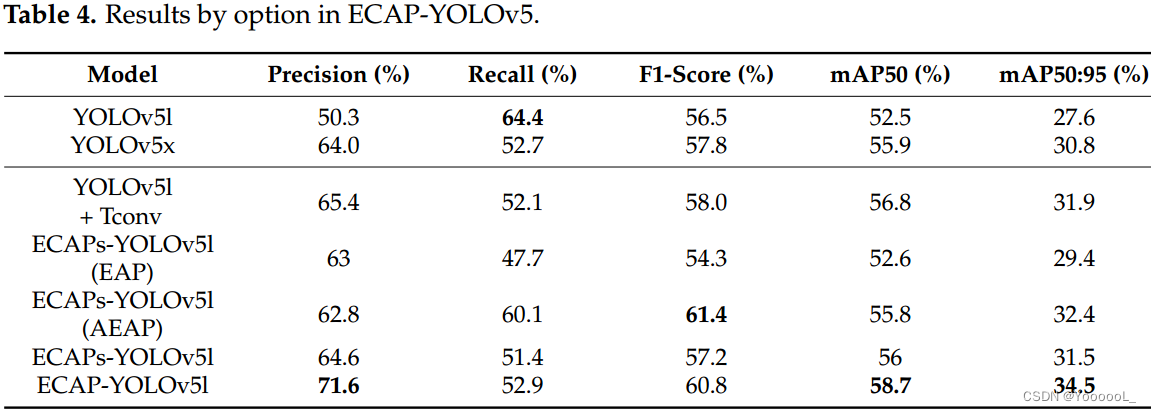
所提出的方法与其他方法进行了比较,如表 6 所示。为了进行比较,使用了 YOLOR [33] 和 YOLOX [34]。在 GFLOP 中,YOLOv5l 最小,但 ECAPs-YOLOv5l 参数最小,为 33.6M。在召回的情况下,YOLOv5l是最高的,但是证实了精度、F1-Score、mAP50 和 mAP 50:95 在 ECAP-YOLOv5l 中表现出高性能。
如图 13 所示,YOLOv5l 检测到未找到的目标并执行更准确的分类。在第一张图片中,一个被错误分类为皮卡的物体被发现是一艘船,并找到了这个物体。第二幅图像进行了额外的飞机检测,第三幅图像进行了汽车的准确分类和货车的额外检测。
4.2. xView Dataset
xView 数据集 [12] 由 WorldView-3 卫星拍摄,地面采样距离为 0.3 m。 xView 数据集总共包含 60 个类和超过 100 万个对象。在本文中,仅确定了 60 个类中的一个小型汽车类来检测小目标。图像被裁剪为 640 × 640 大小,有 10% 的重叠。作为实验的结果,如表 7 所示,所提出的方法与现有的 YOLOv5l 相比,mAP50 分别提高了 9.4% 和 8%。
从图 14(a1,b1) 中的图像可以看出,所提出的方法 更好地检测了图像左侧的差异。此外,可以确认它很好地检测到中间的车辆。在图 14(a2,b2) 中,已确认对齐车辆的检测效果更好。在图 14(a3,b3) 中,现有的 YOLOv5l 遗漏了密集汽车的部分,但证实所提出的方法能更好地检测密集物体。在图 14(a4,b4) 中,还证实了所提出的技术可以更好地检测密集物体。
4.3. DOTA Dataset
DOTA图像采集自中国资源卫星数据与应用中心提供的Google Earth、GF-2和JL-1卫星,以及CycloMedia B.V.提供的航拍图像。DOTA由RGB图像和灰度图像组成。 RGB 图像来自 Google Earth 和 CycloMedia,而灰度图像来自 GF-2 和 JL-1 卫星图像的全色波段。
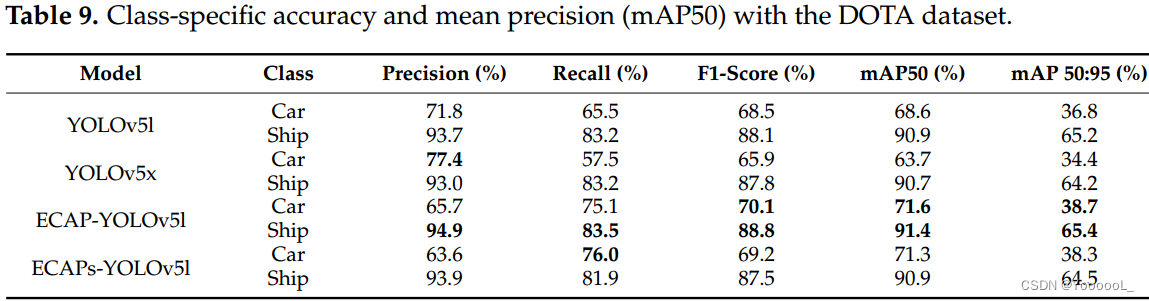
对于 DOTA 数据集 [9],灰度图像来自 GF-2 和 JL-1 卫星图像的全色波段。 DOTA数据集从800×800到20,000×20,000像素,本文使用DOTAv1.5。 DOTAv1.5 使用与 DOTAv1.0 相同数量的图像。 DOTAv1.0 包含 1441 个训练数据集和 458 个验证数据集。数据共包含 403,318 个实例,有 16 个类,即飞机、轮船、储罐、棒球场、网球场、篮球场、田径场、港口、桥梁、大型车辆、小型车辆、直升机、环岛、足球球场、游泳池和集装箱起重机。原样使用现有的训练集,将验证集随机分成两半,使验证集和测试集各为229。只有两个类别(即小型车辆和船舶)用于检测小型目标。对于训练,数据被水平裁剪 640 像素和 10% 重叠。训练结果如表8所示。对于ECAPs-YOLOv5l,mAP相比YOLOv5l提高了2.1%。与 YOLOv5l 相比,ECAP-YOLOv5 增加了 2.7%。
如图15(a1,b1)所示,YOLOv5ls没有检测到,但是ECAP-YOLOv5s检测到了。在图 15 的剩余图像中,可以看出所提出的方法可以很好地检测到密集目标。
在表 9 中,与汽车的 YOLOv5l 相比,ECAPs-YOLOV5l 的 mAP 增加了 3.9%,ECAPYOLOV5l 的 mAP 增加了 4.3%。对于船舶,ECAPs-YOLOV5l 下降了 0.3%,ECAP-YOLOV5l 上升了 1.2%。
4.4. Arirang Dataset
在Arirang数据集 [13] 的情况下,通过将原始卫星图像预处理为使用Arirang 3/3A 卫星图像数据集创建的数据集,它作为处理过的patch(1024 × 1024 大小)提供。共有小船、大船、民用飞机、军用飞机、小型汽车、公共汽车、卡车、火车、起重机、桥梁、油罐、大坝、运动场、直升机停机坪、环岛等16个类别。它由 132,436 个对象组成,按类别分类的对象数如表 10 所示。
本文只使用小汽车作为小目标检测的数据,对输入图像进行1024 × 1024的学习。Arirang数据集的实验结果如表11所示。与YOLOv5l相比,ECAPs-YOLOv5l中的mAP50提高了4.4%,ECAP-YOLOv5l中的map 50提高了4.8%。E与 YOLOv5l 相比,ECAPS-YOLOv5 中的 mAP 为 2.4%,ECAP-YOLOv5l 中为 2%。
可以看出,在图 16 所示的图像中,所提出的方法可以更好地检测到小型汽车。在图 16(a1,b1) 中的图像中,可以看出左上角的对齐差异被更好地检测到。在图 16(2,3) 图像中,现有的 YOLOv5l 遗漏了小汽车部分,但证实提出的方法能更好地检测密集目标。
4.5. Discussion
我们想讨论实验结果。首先,从表1可以看出,当Vedai数据集改为提出的方法的现有YOLOv5检测层时,空中小目标检测的mAP增加了。通过将 ECA-Net 应用于 YOLOv5,确认获得了 55.5% 的 mAP50。从表 2 中可以看出,当按图 8 所示排列时,获得了 56.4% 的最高 mAP。如表 3 所示,已确认应用 AEAP 时获得了最高的 mAP。然而,当将 ECAP-YOLOv5l 与其他注意力金字塔进行比较时,如表 4 所示,已确认 MEAP 显示出最高的 mAP。将所提出的方法与其他方法进行了比较。这可以在表 6 中看到。对于召回率,YOLOv5l 的召回率高于 ECAP-YOLOv5l。 YOLOv5l 的精度较低。这表明 YOLOv5l 发现了更多的真值,但精度较低,导致更多的虚警。然而,可以看出 ECAP-YOLOv5l 在考虑 mAP 时表现出更好的性能。比较图 13(a3,b3),在 YOLOv5l 中没有发现 van,但在提出的方法中发现了。还有,在YOLOv5l识别为皮卡时,所提出的方法识别为轿车,表现更好。
5. Conclusions and Future Works
在本文中,我们介绍了 YOLO 系列并修改了用于空中小目标检测的 YOLOv5 网络。至于修改方法,通过应用第一个有效通道模块来改变主干,并提出了各种通道注意力金字塔。提出了通道注意力金字塔,并对高效通道注意力金字塔网络、空洞高效通道注意力金字塔网络、最大值池化高效通道注意力金字塔网络进行了测试。其次,为了优化小目标的检测,去掉了检测大目标的模块,增加了一个检测层来寻找更小的目标,从而降低了检测小目标的计算能力,提高了检测率。最后,使用转置卷积而不是使用现有的最近邻插值来执行上采样。
作为所提出方法的结果,VEDAI 数据集的 mAP 为 6.9%,xView 数据集中小型汽车的 mAP 为 6.7%,DOTA 数据集的小型车辆和小型船舶类为 2.7%,大约为 2.4%在Arirang数据集中的小型车类中,表现出了性能的提升。
所提出的技术是一种基于 EO 的航拍图像目标检测技术。EO 在夜间、雾中和云中很难检测到物体。然而,如果红外辐射传感器、合成孔径雷达传感器、激光雷达传感器、高光谱传感器等各种异构传感器一起使用,则有望不仅在上述环境中表现出强大的性能,而且整体性能也会更好。