SODA
2022_cite=12_Cheng——Towards large-scale small object detection: Survey and Benchmarks
https://shaunyuan22.github.io/SODA/
小目标检测= small object detection = SOD
-
Datasets:
-
SODA-D: OneDrvie; BaiduNetDisk
-
SODA-A: OneDrvie; BaiduNetDisk
-
-
Codes
The official codes of our benchmark, which mainly includes data preparation and evaluation, are released below.
-
SODA-D Benchmark: SODA-mmdetection
-
SODA-A Benchmark: SODA-mmrotate
文章只是挂在了arxiv上,还没发表在会议或者期刊上。
(1)本文首先回顾了在SOD这个领域经典的小目标识别算法,以及SOD技术的发展演变。(2)然后本文介绍了自己发布的两个专门做SOD任务的数据集SODA-A空中场景和我SODA-D驾驶场景
目前小目标检测领域,学界的研究水平如何?
即使对于领先的检测器,相比于检测正常尺寸的物体,检测小型物体的性能仍然比前者落后很多。 以最先进的检测器之一 DyHead 为例,DyHead 获得的 COCO test-dev set 上小目标的mAP指标仅为 28.3%,明显落后于中型和大型目标的结果(分别为 50.3% 和 57.5%)。
Challenges in SOD tasks
目标检测通用任务上有的那些困难,当然小目标的目标检测也会遇到,比如类内变化intra-class variations, 定位不准确inaccurate localization, 目标检测中的遮挡问题occluded object detection。当然这些在SOD任务上不是重点,重点是SOD独有的这challenges
scarcity,
(1)Scarcity for large-scale dataset tailored for Small Object Detection
(1)专门用于 小目标检测 的大规模数据集仍然不多,比较稀缺——这篇论文就公开了两个大规模的专门做SOD数据集,所以这个问题你不用担心了,已经解决了。
学界目前已经提出的一些为小目标检测量身定制(tailored )的数据集有后面这些,(1)SOD 和 TinyPerson。然而,因为她们数据集的规模太小了,是无法满足CNN模型对数据量的需要的。(数据量过少,都不够参数拟合的,这样训练出来的模型泛化能力差,没有用处)
一些公共数据集包含比较多的小目标,例如 WiderFace、SeaPerson 和 DOTA 等。不幸的是,
[1]这些数据集要么是为二分类检测任务(人脸检测--人脸检测 检测是人脸或者不是人脸 或 行人检测 是行人或者不是行人)而设计的,通常遵循相对一定的模式(识别的模型只需要判断这个小目标,是不是人头那样形状椭圆,图案上椭圆的上部有一点黑棕色;行人识别,只需要判断这个object的形状像不像一个扭曲的大字。这样小目标特征提取器无法学到任何有价值的特征,根据形状直接判断就行了)。
[2]或者其中微小的目标仅分布在几个类别中。比如DOTA数据集中,小目标大多数就是的小型车辆。其他类别的目标就直接没有尺寸较小的目标。那么模型无法学习到各种各样的特征来判断这个小目标的类别,而是会直接把尺寸和相应的类别建立联系,比如你拿过一个小目标来,我不需要从小目标的图片中提取任何的特征,我直接判定这个小目标就是小型车辆,这样准确率是高了,但是我们的小目标提取器并没有学到任何有价值的特征,也就是说我们小目标检测这个特征提取器在这个数据集上训练失败了。
概括来说,我们希望训练实用的数据集,具备下面这个特征,我们希望小目标在数据集中的数量要尽可能的多,并且相对均匀的分布于多个类别。这样我们可以去评估 在 多个类别上SOD算法分数,并对这个分数进行优化,最后使得这个训练出来的小目标识别模型能够提取各种类别的多样化的特征,进而实现在多个类别上更好的分类。
作者收集的数据集的特色
SODA-D——驾驶场景。包括2.4万张高质量交通图和9个类别的27w个实例。这个数据集是融合的两个数据集整合出来的,一个是MVD这个公开数据集,一个是作者自己收集的数据集。MVD数据集是专门用于对街景进行像素级理解的数据集。作者自己收集的数据集是用车载摄像机和手机拍摄的。然后作者对这个两个被融合的数据集里面的图片进行了精心挑选,仅仅选用高质量、小目标比较多的那些驾驶场景的图片。
SODA-A——空中飞行场景。包括2.5K张高分辨率的航拍图,并对9个类别的80w个实例进行了注释。这个图片是作者从Google Earth这软件中提取的高分辨率图像
这个数据集是学术界首次尝试 大规模基准测试 。上面这两个数据集都为了多类别的SOD量身定制(专门为了小目标这个场景,在标注上做了很多特别的操作;图片的选取也是专门挑的object比较小的那种拿过来,尺寸大的目标非常少)了大量注释实例。
同时作者将目前学界最主流的这些小目标检测的方法,在作者提出的这两个数据集上做了测试,评估了这些SOD算法的性能。
小目标识别的特征提取器,提取出来的特征是低质量的,原因有下面三个
(2)Information loss caused by sub-sampling 因下采样引发的信息丢失
——下采样引发信息损失——在backbone主干网络,这个特征提取器,使用了下采样。这个下采样的初衷是为
-
尺寸比较大的object:特征提取器里使用下采样是合适。尺寸大的object,他们的信息本身就十分充足,丢失掉这点信息损失,不会对他们识别的精度带来明显的下降。同时下采样的过程中,可以提取到一些图片的高维特征,这反而带来的信息增益,使得在特征提取器中加入下采样,反而会提高识别的精度。
-
尺寸比较小的object:进行下采样会带来如下的这些负面影响。在下采样的过程中,feature map的尺寸变小了,也就是特征图的空间分辨率降低了(本来就很小的图片,变得更加模糊了)。在下采样downsampling之前,小目标本身在照片上的面积就小,在做完下采样以后,尺寸变得更加的小。小目标的objec尺寸比较小,本身像素点的个数就比尺寸大的object要少,传递的信息也自然少。本来就为数不多的一些信息,在下采样的过程里又进一步损失掉了一些。信息变少了,识别的分数也就降低了
(3)Noisy feature representation噪声特征表示
本身噪声很多:小目标通常具有低分辨率和低质量的外观,因此很难通过区分其扭曲结构来学习小目标图片的特征表示,进行特征提取。
周围的东西又引入一些噪声:小目标的区域特征容易被背景和其他实例污染,进一步给学习到的特征表示引入了噪声。
提取到的特征是低质量的,里面混入了大量噪声,自然garbage in, garbage out,最后的performace能好才怪呢!
(4)Low tolerance for bounding box perturbation(扰动) 识别框扰动低容忍度
这个challenge主要针对的是识别过程里这个定义这一步,和分类那一步没有关系。
定位作为检测的主要任务之一,在大多数检测范式中被表述为回归问题。
其中定位分支被设计为输出边界框偏移量或目标大小(前面那个指的是什么?你说或,到底是取哪个?),通常交集比联合(IoU)度量为用于评估准确性。(你告诉我你怎么用IoU评估的,把评估过程写在下面具体是怎么做的,你去查一查,写在下面) 然而,定位小目标比大目标更难。
目标的预测框的轻微偏差(沿对角线方向 6 个像素)导致 IoU 显着下降(下降了67.5%) )。 同时,更大的方差(比如 12 个像素)进一步加剧了这种情况,对于小目标,IoU 下降到 8.7%。 也就是说,与较大的目标相比,小目标对边界框扰动的容忍度较低,加剧了回归分支的学习。
小目标本身就小,退让同样的量,但是退让的这个量在 小目标这个尺寸上,损失的I占U的比重更大。为啥因为基数小。相当于分子相同(同样一个识别框的偏移/误差的一个绝对量),分母越小的那个(object尺寸越小),损失掉的精度越多
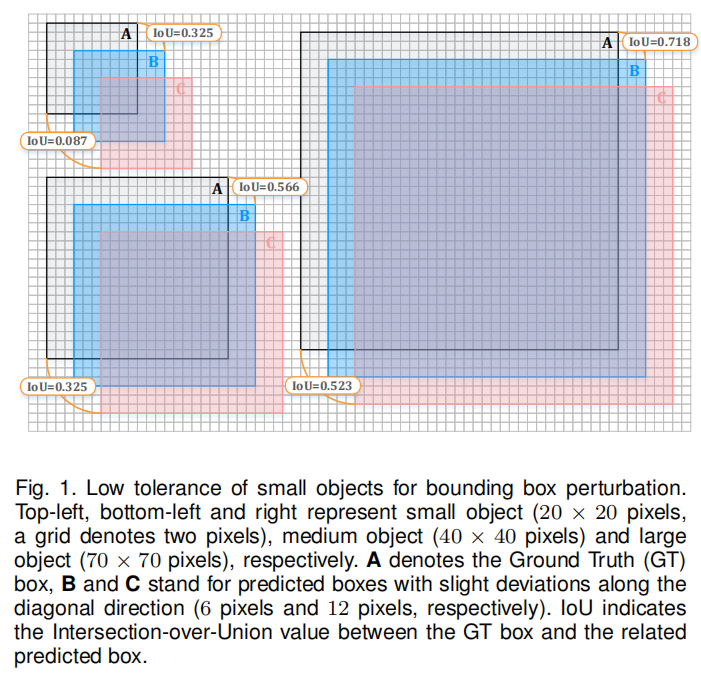
上面这个图什么意思,我来解释一下
下面这个格子,一个格子代表2个pixel,左上角这个小目标的尺寸是20×20 pixels。左下角这个 不大不小的目标尺寸是40×40 pixels,右边这个很大的目标的尺寸是70×70 pixels
这三种size的目标,都是由黑框、蓝色正方形阴影和红色正方形阴影组成的。黑框表示Ground Truth,B框和C框都是predicted boxes。只不过B框相比A框向右和向下都偏移了6个pixel,然后C框又在B框的基础之上向右向下都偏移了6pixel。
注意哦,这里是做了控制变量,三个目标 两次移动的的方向相同,移动的像素值相同都是6个像素。三个半目标唯一不同的就是他们的尺寸。这里我们来考察,不同大小object,识别框便宜同样多少的像素值以后,分类的误差会提高多少?这里分类的误差,我们粗糙的用(1-IoU)来表示。我这样表示的理由是,既然IoU表示定位争取的部分,那1-IoU不就是分类错误的部分吗?
| IoU |
||
| 右下6个像素 |
右下12个像素 |
|
| 大 |
0.718 |
0.523 |
| 中 |
0.566 |
0.325 |
| 小 |
0.325 |
0.087 |
| 因识别框偏移,损失掉的精度(1-IoU) |
||
| 右下6个像素 |
右下12个像素 |
|
| 大 |
0.282 |
0.477 |
| 中 |
0.434 |
0.675 |
| 小 |
0.675 |
0.913 |
识别框向右下方偏移6个像素,大型目标损失的精度为28.2%。中型目标精度损失更多,是43.4%(是大型目标损失的1.54倍)。小型目标的精度损失更加大,为67.5%(是最大型目标的2.39倍)
如果向右下方偏移更多的像素,那么小型目标损失的精度也还是比大型目标要多
识别框向右下方偏移12个像素,大型目标损失的精度为47.7%;中型目标精度损失比大型目标要多,为67.5%;小型目标的精度损失比中型目标要多,为91.3%
为了解决上面这三个问题,学界为了解决这三个问题,他们提出的解决方案可以被归纳成六 类:数据操作方法、尺度感知方法、特征融合方法、超分辨率方法、上下文建模方法和其他方法。
-1-Data Manipulation
(效果上不好)——默认都会用
Problem address:微小尺寸的目标仅占当前数据集中的非常小的一部分,大尺寸目标在整个数据集中占据主导。这就导致了在训练模型的过程中,模型着重提高大尺寸样本的识别精度,小尺寸目标识这一任务并没有得到有效而充分的训练,自然小尺寸样本识别的表现performance比起大尺寸样本要差很多。 这种现象被我们称为,目标尺度级别的样本不平衡(Data inbalance)。
Solution:解决这个问题最直接的方案是,增加小尺寸目标在训练集中的数量,这样可以通过增加正样本来鼓励检测器更好地优化小尺寸的目标的识别性能。
Limitation:数据集的数据量大小上的不同,数据集的样本的object尺寸上的均衡程度的不同,会导致这种功能方法在不同数据集上带来的改进和提高的程度是不同的,inconsistent performance improvement between datasets of different volumes。也就是说,你的这个方法可能在一些数据集上(样本object尺度极度不平衡),性能提高了很多,但是换到另一个数据集上(样本object尺度本身挺平衡的),性能提高十分有限。概括来说,这种方法可迁移性transferability不是很好。使用这个方法提高模型精度的多少很大程度上取决于你使用的数据集是什么情况。The performance gain obtained by the manipulationbased methods is dataset-dependent
-1.1-Oversampling-based augmentation strategy
基于过采样的增强策略
Kisantal 等人采用了一种增强策略,通过复制一个小目标,将被复制的这小目标随机变换粘贴到同一图像中的不同位置。
RRNet 引入了一种名为 AdaResampling 的自适应adaptive增强策略,它遵循和Kisantal相同的理念。它的主要改进在于,在采样的过程sample process中,(1)使用“先验分割图prior segmentation map ”(我也不知道是啥?先不管他),来确定要粘贴到的最合适的位置valid positions 。(2)我们会对被粘贴pasted 的object做一个尺寸上的调整scale transformation,比如这张图上的小目标比较少,我们就把粘贴过来的object的尺寸调小一点,这样尺寸小的目标就多了,样本就变得均衡了。反之把粘贴过来的object,粘贴过来的时候把尺寸调大。这样做的好处是,是可以进一步弱化 目标尺度大小的样本不均衡
在 Yolov4 中,提出了一种新的数据增强策略 Mosaic 来增强原始数据,它将多个(例如 4 个)图像拼接成一个新的样本。 由于原始图像通常被缩小到更小的尺寸,因此该操作在实践中提高了小目标的数量。
-1.2-Automatic augmentation scheme
遵循这种范式的方法探索了几种预定义增强策略的最佳组合。 Zoph 等人认为,借用分类任务的现成增强技术对检测的贡献很小,因此他们将增强过程建模为离散优化问题,并寻找预设增强操作的最佳组合。
为此,利用基于强化学习的有效搜索技术来探索最佳参数。 然而,在如此大的搜索空间中搜索,导致计算量开销很大。 为了缓解这种情况,Cubuk 等人仅使用单个失真幅度联合优化(???)了所有操作,同时保持概率参数一致。
-2-Scale-aware methods 根据目标的尺寸大小进行分流
无论是多级表示还是特定的训练方案都力求小目标和中大型目标的 一致 性能增益。然而,分治范式将不同大小的目标映射到相应的尺度级别可能会使检测器感到困惑(是映射到相同尺度吗?),因为单层的信息不足以做出准确的预测(啊??哪里有单层?预测什么?)。另一方面,用于促进多尺度训练的定制机制通常会引入额外的计算,从而阻碍端到端优化。
-2.1-Multi-scale detection in a divide-and-conquer fashion分而治之
简介:用对应尺度scale的目标检测器,来识别不同深度和层级的特征the features at different depths or levels。分而治之,尺寸极其小的object,就用专门的“极小”目标检测器来识别;尺度有点小的object就用专门的“有点小”目标检测器来识别。把识别这个任务分成多个尺度的子任务,每个目标检测器负责一个尺度。
HyperNet 提出这样一个assumption假设:感兴趣区域 (RoI,Regin of Interest) 的信息分布在骨干网络的所有层上。既然分布在很多地方,那RoI这一部分信息需要你进行良好的组织。基于这个assumption,为了对分布在backbone上各个地方分布着的RoI信息进行一个整合和捕捉,作者通过连接concatenate和压缩compress 那些“由粗到细coarse-to-fine ”的特征feature,最后整合出一个Hyper Feature。这个Hyper Feature保留了关于目标进行推理和判定的一些信息, Hyper Features retains the reasoning of small objects. (和小目标有啥关系??)
Yang 充分利用了scale-dependent pooling (SDP) 来选择合适的特征层proper feature layer用于后续的小目标池化操作 for subsequent pooling operation 。
MS-CNN 在不同的中间层at different intermediate layers ,生成候选区域推荐generates object proposals ,每个中间层都专注于一定比例范围内的目标,each of which focuses on thee objects within certain scale ranges, ,从而使得小目标的感受野达到最优enabling the optimal receptive field for small objects. 。
Liu发明了 Single Shot MultiBox Detector (SSD) 来检测高分辨率特征图上的小目标。(SSD是什么,在术语解释里面写了)SSD算法结合了多个不同分辨率大小的feature map的预测,有利于处理多尺度的目标。
DSFD(Dual Shot Face Detector) 这个算法完成的任务是识别不同尺寸大小的人脸to detect the faces of variou scales。这个模型使用了一个two-shot detector。two-shot detector(应该翻译成双分支网络,作者也称模型为dual shot dector,整个网络由两个子网络串行起来的,一个子网络叫一个shot,合起来叫two shot或dual shot)这两个shot之间用特征增强模块feature enhancement module 来连接的connected by。DSFD为并行双预测分支组成,训练阶段两条分支都作预测,而测试阶段仅使用第二条分支(特征增强分支)为什么使用双分支呢?作者提到可以将第一条预测分支看成是一种辅助监督,使得特征更符合人脸检测(个人理解:第一条分支可看成一种特征约束)。
https://blog.csdn.net/silence2015/article/details/106268010/
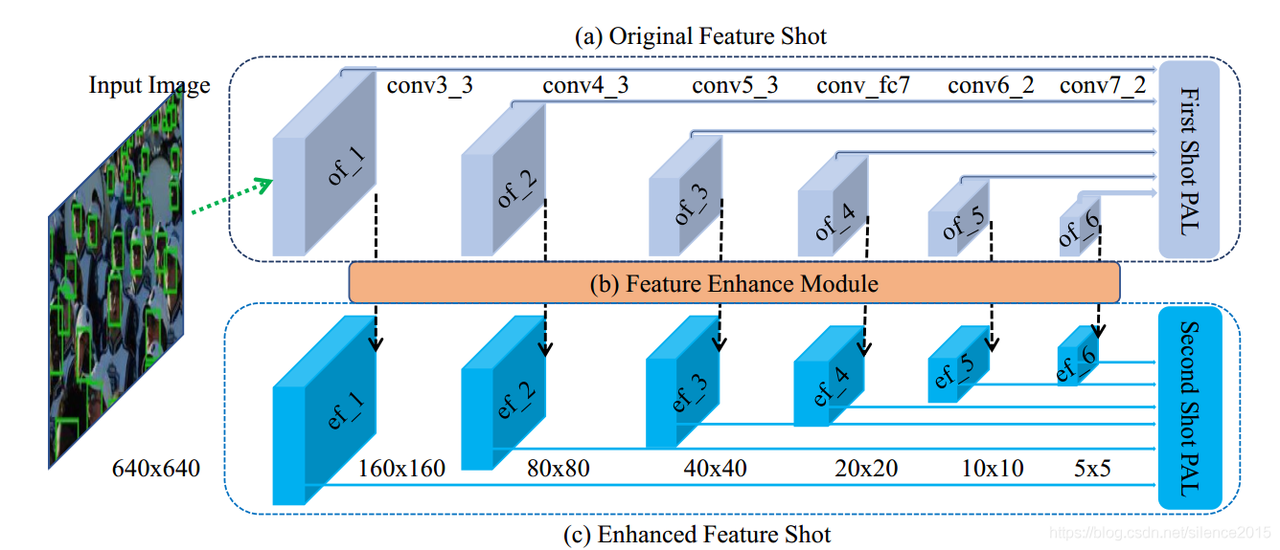
——————这里以后,没看过论文的英文原文————————
YOLOv3 通过添加并行分支来进行多尺度预测,其中高分辨率特征负责小目标。 M2Det 构造多级特征金字塔来检测对象。
此外,已经广泛探索了结合尺度检测器进行多尺度检测。 Li 等人构建了并行子网络,其中专门学习小型子网络以检测小型行人。 SSH 训练了多个人脸检测器,每个人脸检测器都使用一定的尺度范围的人脸图片进行训练,比如这个检测器训练20个像素长宽的人脸,另一个检测器训练10像素长宽的检测器。这些检测器放在一起,共同组成了多尺度检测器,用来处理尺度变化极大的人脸数据集。
TridentNet 构建了一个并行的多分支架构,其中每个分支都拥有针对不同尺度对象的最佳感受野。 受到 PANet 中区域级特征聚合的巨大成功的启发,Zhang 等人将多个深度的 RoI(Region of Interest) 的池化特征与全局特征连接起来,以获得对小目标的更鲁棒和判别性的表示。 QueryDet 设计了级联查询策略(这是个啥?不重要,就算了),避免了对低级特征的冗余计算,使得高效检测高分辨率特征图上的小目标成为可能。
-2.2-Tailored training schemes 定制化训练
基于多尺度训练和测试可以提升检测器的性能已经成为共识,遵循该路线图的方法旨在在训练期间开发定制的数据准备策略。基于通用的多尺度训练方案,Singh 等人设计了一种新颖的训练范式,图像金字塔的尺度归一化 (SNIP),它只采用分辨率落入训练所需尺度范围的实例,其余的则被简单地忽略.通过这种设置,可以在最合理的范围内处理小目标,而不会影响对中大型目标的检测性能。
后来,Sniper 建议从多尺度图像金字塔中采样以进行高效训练。 Najibi 等人提出了一种从粗到细的管道来检测小目标。考虑到数据准备和模型优化之间的协作在以前的方法中没有得到充分的探索,Chen 等人设计了一种反馈驱动的训练范式来动态指导数据准备并进一步平衡小目标的训练损失。 Yu 等人引入了一种基于统计的匹配策略以实现规模一致性。
-3-Feature-fusion methods
深度 CNN 架构产生不同空间分辨率的分层特征图,其中低层特征描述更精细的细节以及更多定位线索,而高层特征捕获更丰富的语义信息。 由于子采样层(应该是下采样模块)的存在(使用),小目标的响应可能会在更深层消失。 另一种解决方案是利用浅层特征来检测小目标。 虽然有利于定位,但早期的特征图容易受到光照、变形和物体姿态等变化的影响,使得分类任务更具挑战性。 为了克服这一困境,比较流行的方法是利用特征融合,整合不同层或分支的特征,以获得对小目标更好的特征表示。
-3.1-Top-down information interaction 自上而下的信息交互
受手工特征时代使用的金字塔结构的启发,FPN等作品构建了自上而下的路径,以加强浅层和深层之间的交互,使高分辨率表示同时具有丰富的语义信息和对小目标的精细定位. Shrivastava 等人介绍了自顶向下调制 (TDM) 网络,其中自顶向下模块学习应保留的语义或上下文,横向模块转换低级特征以进行后续融合。
Lin 等人提出了特征金字塔网络(FPN),其中具有高分辨率但低级语义的特征与具有低分辨率但高级语义的特征聚合。这种简单而有效的设计已成为特征提取器的重要组成部分。
为了缓解单向金字塔架构中定位的不足,PANet 通过双向路径丰富了特征层次结构,通过准确的定位信号增强了更深层次的特征。
Zand 等人在 DarkNet-53 和 skip-connection 的基础上构建了 DarkNet-RI(就是这两种技术组合在一起),以生成不同尺度的高级语义特征图。
-3.2-Refined feature fusion 精细化特征融合
尽管自上而下的信息交互取得了成功,但由于基本的上采样和融合无法处理 PANet 固有的尺度不一致性,基本的交互设计并不完美。观察到这一点,以下方法旨在以适当的方式 细化 从主干不同阶段的特征(什么叫 从主干不同阶段的特征?),或通过动态控制不同层之间的信息流来优化融合过程。
吴等人提出了利用反卷积来扩大特征图的StairNet,这种learning-based up-sampling特征可以实现比kernel-based up-sampling更精细的特征,并允许不同金字塔的信息更有效地传播。
Liu等人引入了IPG-Net,将图像金字塔得到的一组不同分辨率的图像输入到设计的IPG变换模块中,提取浅层特征以补充空间信息和细节。
Gong 等人设计了一种基于统计的融合因子来控制相邻层的信息流。注意到基于 FPN 的方法中遇到的梯度不一致会降低低层特征的表示能力
SSPNet 在不同层突出特定尺度的特征,并利用 FPN 中相邻层的关系来实现适当的特征共享。
特征融合方法可以弥合较低金字塔层次和较高层次之间的空间和语义差距。 然而,由于基于尺度的金字塔分配策略,在当前检测范式中,小目标通常被分配给最低的金字塔特征(最高空间分辨率),这在实践中产生了计算负担和冗余表示。 此外,网络内的信息流并不总是有利于小目标的表示。 作者的目标是不仅赋予低级特征更多的语义,而且防止小目标的原始响应被更深的信号淹没。
-4-Super-resolution methods 通过超分辨率的技术把小目标变清晰
丰富小目标信息的一种直接方法是通过双线性插值和超分辨率网络提高输入图像的分辨率。 然而,基于插值的方法,作为一种局部操作,通常无法捕捉全局理解并受到马赛克效应的影响。 对于那些尺寸极其有限的目标,这种情况可能会变得更糟。
此外,作者希望upscaling操作可以恢复小目标的扭曲结构,而不是简单地放大它们的模糊外观。 为此,一些尝试性的方法通过从超分辨率领域借用现成的技术来超分辨率输入图像或特征。 这些方法中的大多数采用生成对抗网络(GAN)来计算有利于小目标检测的高质量表示,而其他方法则选择 参数化 上采样操作来扩大特征。
可约束的上采样——采用
插值法---很模糊
TransConv uppooling
-4.1-Learning-based upscaling
盲目地增加输入图像的规模会在特征提取阶段导致 性能饱和 和不可忽略的计算成本。 为了克服这个困难,遵循这条线的方法更喜欢对特征图进行超分辨率。 他们通常利用基于学习的上采样操作来 提高特征图的分辨率并 丰富结构。 在 SSD 之上,DSSD 采用反卷积操作来获得专门用于小目标检测的高分辨率特征。 Zhou 等人和 Deng 等人探索了亚像素卷积以进行有效的上采样。
-4.2-GAN-based super-resolution frameworks.
Goodfellow 等人提出 GAN 通过遵循生成器和判别器之间的两人极小极大游戏来生成视觉上真实的数据。不出所料,这种能力启发了研究人员探索这种强大的范式,以生成高质量的小目标表示。然而,直接对整个图像进行超分辨率处理会增加特征提取器在训练和推理方面的负担。
为了减轻这种开销,MTGAN 使用生成器网络解析 RoI 的patch。 Bai 等人将此范式扩展到人脸检测任务,Na 等人将超分辨率方法应用于小的候选区域以获得更好的性能。尽管超分辨率目标块可以部分重建小目标的模糊外观,但该方案忽略了对网络预测起重要作用的上下文线索。为了解决这个问题,Li 等人设计了 PerceptualGAN 来挖掘和利用小规模和大规模目标之间的内在相关性,其中生成器 学习 将小目标的弱表示 映射到 超分辨率的表示 以欺骗鉴别器。为了更进一步,Noh 等人对超分辨率程序引入了直接监督。
由于尺寸有限,小目标的信号在特征提取后不可避免地丢失,导致后续的 RoI 池化操作几乎无法计算结构表示。 通过挖掘小尺度目标和大尺度目标之间的内在相关性,超分辨率框架允许部分恢复小目标的详细表示。 然而,无论是基于学习的升级方法还是基于 GAN 的方法都必须在繁重的计算和整体性能之间保持平衡。 此外,基于 GAN 的方法倾向于制造虚假的纹理和伪影,对检测产生负面影响。 更糟糕的是,超分辨率架构的存在使端到端优化变得复杂。
-5-Context-modeling methods
人类可以有效地利用 环境与物体的关系 或 物体之间的关系 来 促进物体和场景的识别。 这种捕获语义或空间关联的先验知识被称为上下文contex,它将证据或线索传递到目标区域之外。 上下文信息不仅在人类的视觉系统中至关重要,而且在目标识别、语义分割和实例分割等场景理解任务中也至关重要。有趣的是,信息上下文有时可以提供比目标本身更多的决策支持,尤其是当它涉及识别具有较差观看质量的物体。 为此,有几种方法利用上下文线索来增强对小目标的检测。
Chen 等人采用了上下文区域的表示,其中包含用于后续识别的提议补丁。 Hu 等人研究了如何有效地对超出目标范围的区域进行编码,并以尺度不变的方式对局部上下文信息进行建模以检测微小的人脸。 PyramidBox 充分利用上下文线索来寻找与背景无法区分的小而模糊的面孔(确定模糊一团的这个东西是人脸)。 图像中目标的内在相关性同样可以被视为上下文。 FS-SSD 利用隐含的空间上下文信息,即类内实例和类间实例之间的距离,以低置信度重新检测目标(啊?啥意思?)。 假设原始的 RoI 池化操作会破坏小目标的结构,SINet 引入了一个上下文感知的 RoI 池化层来维护上下文信息。 IONet 通过2个4向 IRNN 结构计算全局上下文特征,以更好地检测小型和严重遮挡的目标。
从信息论的角度来看,考虑的特征类型越多,就越有可能获得更高的检测精度。 受共识的启发,上下文启动已被广泛研究以产生更具辨别力的特征,特别是对于线索不足的小目标,从而实现精确识别。
Limitation:不幸的是,整体上下文建模或局部上下文启动都混淆了哪些区域应该被编码为上下文。 换句话说,当前的上下文建模机制以启发式和经验的方式确定上下文区域,这不能保证构建的表示具有足够的可解释性以进行检测。
-6-Others
Attention-based methods
人类可以通过对整个场景的一系列局部瞥见来快速聚焦和区分物体,同时忽略那些不必要的部分,而我们感知系统中这种惊人的能力通常被称为视觉注意力机制,它在视觉系统中起着至关重要的作用。毫不奇怪,这种强大的机制已在以前的文献中进行了广泛的研究,并在许多视觉领域显示出巨大的潜力。通过为特征图 的不同部分 分配不同的权重,注意力建模 确实强调了 有价值的区域,同时抑制了那些可有可无的区域。自然地,人们可以部署这种优越的方案来突出图像中倾向于由背景和噪声图案主导的小目标。
Pang 等人采用 全局注意力块 来 抑制误检 并 有效地检测大尺度遥感图像中的小目标。 SCRDet 设计了一种定向目标检测器,其中 像素注意力 和 通道注意力 以有监督的方式进行训练,以突出小目标区域,同时消除噪声的干扰。 FBR-Net 使用提出的level-based attention扩展了anchor-free检测器 FCOS,平衡了不同金字塔的特征,并增强了复杂情况下小目标的学习。
Localization-driven optimization
定位作为检测的主要任务之一,在大多数检测范式中被表述为回归问题。 然而,在当前检测器的这个无处不在的分支中 采用的回归目标 无法 与评估指标(即 IoU)协调一致。 而这种优化的不一致会损害检测器的性能,尤其是在微小目标上。 考虑到这一点,有几种方法旨在为局部分支配备 IoU Aware 或寻求适当的指标。
TinaFace 在 RetinaNet 中添加了一个 DIoU 分支,最终获得了一个简单但强大的基线,用于小人脸检测。 观察到由于微小的目标预测框的轻微偏移,IoU 指标发生了巨大变化,Xu 等人提出了一种新的度量,Dot Distance,以缓解这种情况。 同样,NWD 引入了归一化 Wasserstein 距离来优化微小目标检测器的位置度量。
Density analysis guided detection
高分辨率图像中的小目标往往 分布不均匀 且 稀疏 ,而 一般的分检测方案 在这些空块上 消耗过多的计算量,导致推理效率低下。 我们可以过滤掉那些没有目标的区域,从而减少无用的操作来提高检测吗? 答案是肯定的! 该领域的努力打破了处理高分辨率图像的通用管道链,他们首先抽象出包含目标的区域,然后在这些区域上执行检测。 Yang等人提出了一个集群检测网络(ClusDet),它 充分利用目标之间的语义和空间信息 来生成集群chips,然后进行检测。 按照这种范式,Duan 等人和 Li 等人都利用像素级监督来进行密度估计,获得了更准确的密度图,可以很好地表征物体的分布。
Other issues
一些试验性策略采用了其他领域的有趣技术来更好地检测小目标。 认为传统的注释方式会引入偏差和歧义,Song 等人建议为行人提供一种新颖的拓扑注释 ,它允许使用所提出的 体细胞拓扑线定位 (TLL) 在小规模实例上进行更精确的定位。 与超分辨率方法类似,Wu 等人采用提议的 模拟损失 来弥合小型行人的区域表示与大型行人的区域表示之间的差距。 Kim 等人受到 人类视觉理解机制的记忆过程 的启发,设计了一种 基于记忆学习 的小规模行人检测新框架。
用的什么模型做的evaluation
评估指标用的AP(Average Precision)
代码用的mmdetection这个packag代码用的mmdetection这个package,同时也用到了mmrotate这个package
https://github.com/open-mmlab/mmrotate
SDOA-D
SDOA-A

主要是看下面这些代码,在我的论文上能不能用
下面这两个数据集,使用的模型,是不是在mmdetection和mmrotate里面出现呢?
SDOA-D mmdetection
有的:Faster RCNN、Cascade RCNN、RetinaNet、CornerNet、CenterNet、FCOS、RepPoints、ATSS、Deformable-DETR、Sparse RCNN、YOLOX
没的:RFLA
SDOA-A mmrotate
有的:Rotated Faster RCNN;Rotated RetinaNet;RoI Transformer;Gliding Vertex;Oriented RCNN;S2A-Net;Oriented RepPoints;
没的:DODet;DHRec
去看两个repo的config文件,看看有没有规定调用哪个模型?——sodaa-benchmarks.和sodaa-benchmarks
SDOA-D,文件位置:https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/sodad-benchmarks ,除了RFLA 这个代码里都有
SDOA-A,文件位置:https://github.com/shaunyuan22/SODA-mmrotate/tree/main/configs/sodaa-benchmarks,除了DODet;DHRec,都有
-
Faster RCNN——[1]:S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” TPAMI,vol. 39, no. 6, pp. 1137–1149, 20
——faster-rcnn是二阶段检测算法的经典之作了
——感觉就是RCNN做了一些改动,使得实时性变得更好
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/faster_rcnn
-
Cascade RCNN——[160] J. Han, J. Ding, J. Li, and G.-S. Xia, “Align deep features for oriented object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/cascade_rcnn
-
RetinaNet——[3]T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for ´ dense object detection,” TPAMI, vol. 42, no. 2, pp. 318–327, 2020.
——是one-stage网络,是one-stage 网络首次超越 two-stage 网络
——这篇文章解决的问题是dense object detection,这里的dense的意思不是 极小的目标 目标很多的 密集情景下的 识别,dense指的是 采样的图像区域数量(或者说anchor数量/proposals数量)很多,一般数量可以达到~100k
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/retinanet
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
CornerNet——[51]H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” in ECCV, 2018, pp. 734–750
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/cornernet
-
CenterNet——[47]X. Zhou, D. Wang, and P. Krahenb ¨ uhl, “Objects as points,” ¨ arXiv preprint arXiv:1904.07850, 2019.
——anchor-free的目标检测网络
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/centernet
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
FCOS——[4]Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: A simple and strong anchor-free object detector,” TPAMI, vol. 44, no. 4, pp. 1922–1933, 2022.
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/fcos
——不是为了小目标识别而设计的,属于通用的目标识别模型
是常用的anchor-free的目标检测算法之一
-
RepPoints——[162]Z. Yang, S. Liu, H. Hu, L. Wang, and S. Lin, “Reppoints: Point set representation for object detection,” in ICCV, 2019, pp. 9656–9665.
——一种anchor-free网络
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/reppoints
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
ATSS——[163]S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” in CVPR, 2020, pp. 9759–9768.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/atss
-
Deformable-DETR——[52]X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”in ICLR, 2020
——DETR算是Transformer应用在目标检测中比较有代表性的方法了,本文主要是将可变卷积的思路用在了DETR上,
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/deformable_detr
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
Sparse RCNN——[164]P. Sun et al., “Sparse r-cnn: End-to-end object detection with learnable proposals,” in CVPR, 2021, pp. 14 449–14 458.
——Sparse R-CNN抛弃了anchor boxes或者reference point等dense概念,直接从a sparse set of learnable proposals出发,没有NMS后处理,整个网络异常干净和简洁,可以看做是一个全新的检测范式。稀疏框架,端到端的目标检
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/sparse_rcnn
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
YOLOX——[161]Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,” arXiv preprint arXiv:2107.08430, 2021.
——YOLOx创新在于使用Decoupled Head、SIMOTA等方式
——mmdetection里面有https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/yolox
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
RFLA——[63]C. Xu, J. Wang, W. Yang, H. Yu, L. Yu, and G.-S. Xia, “Rfla: Gaussian receptive based label assignment for tiny object detection,”in ECCV, 2022.
——mmdetection里面没有,但是代码论文作者公布了https://github.com/Chasel-Tsui/mmdet-rfla
——专门用于极小目标检测
SDOA-A mmrotate
识别的目标都是航拍图的目标,实际上目标图的尺寸都很小,但是是不是属于SOD,也看你的标准,不好说
-
Rotated Faster RCNN——[1]S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” TPAMI,vol. 39, no. 6, pp. 1137–1149, 2017
——前面有了
——mmrotate里面有https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/rotated_faster_rcnn/README.md
-
Rotated RetinaNet——[3]T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for ´dense object detection,” TPAMI, vol. 42, no. 2, pp. 318–327, 2020.
——前面有了
——mmrotate里面有https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/rotated_retinanet/README.md
-
RoI Transformer——[169] J. Ding, N. Xue, Y. Long, G.-S. Xia, and Q. Lu, “Learning roi transformer for oriented object detection in aerial images,” in CVPR, 2019, pp. 2844–2853.
——mmrotate里面有https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/roi_trans/README.md
——虽然是在卫星航拍图上做的任务,不是为了小目标识别而设计的,属于通用的目标识别模型
-
Gliding Vertex——[170] Y. Xu, M. Fu, Q. Wang, Y. Wang, K. Chen, G.-S. Xia, and X. Bai, “Gliding vertex on the horizontal bounding box for multioriented object detection,” TPAMI, vol. 43, no. 4, pp. 1452–1459, 2021.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmrotate里面有https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/gliding_vertex/README.md
-
Oriented RCNN——[171]X. Xie, G. Cheng, J. Wang, X. Yao, and J. Han, “Oriented r-cnn for object detection,” in ICCV, 2021, pp. 3520–3529.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmrotate里面有https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/oriented_rcnn/README.md
-
S2A-Net——[172] J. Han, J. Ding, J. Li, and G.-S. Xia, “Align deep features for oriented object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmrotate里面有https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/s2anet/README.md
-
DODet——[173]G. Cheng, Y. Yao, S. Li, K. Li, X. Xie, J. Wang, X. Yao, and J. Han, “Dual-aligned oriented detector,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmrotate里面没有
——(SODA-mmrotate/configs/sodaa-benchmarks/)里面没有
-
Oriented RepPoints——[174]W. Li, Y. Chen, K. Hu, and J. Zhu, “Oriented reppoints for aerial object detection,” in CVPR, 2022, pp. 1829–1838.
——是航空图,专用于小目标识别
——mmrotate里面https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/rotated_reppoints/README.md
——不是为了小目标识别而设计的,属于通用的目标识别模型
-
DHRec——[175]G. Nie and H. Huang, “Multi-oriented object detection in aerial images with double horizontal rectangles,” TPAMI, pp. 1–13,2022.
——不是为了小目标识别而设计的,属于通用的目标识别模型
——mmrotate里面没有
——(SODA-mmrotate/configs/sodaa-benchmarks/)里面没有
这两个数据集使用的评估模型完全不同,两个数据集 使用的数据集没有一个模型是相同的,只是有几个模型是某个原始模型的变种
两个模型都用了的模型
Faster RCNN:都是同一篇论文,D用的原始的,A用的加了Rotated的,
RetinaNet(视网膜):都是同一篇论文,D用的最原始的,A用的加了Rotated
RepPoints:,不是同一篇论文,D用的是最原始的,A用的是带Oriented
RCNN系列变种:不是同一篇
D中使用了三个RCNN的变种:Faster RCNN[1], Cascade RCNN[160], Sparse RCNN[164]
A中使用了两个RCNN的变种:Rotated Faster RCNN[1], Oriented RCNN[171]
(还没统计完)
好像上面这个图,和论文里写的使用的模型好像是不一样的——是不一样的吗?——完全一样,且上面这些模型更加全面,上这个更可信
——去github代码找有一页里面列满了它代码里囊括的所有模型,——你先找到这一页——然后对照里面的模型名字和我列出这些模型名字,https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs_————是不是完全一致,如果完全一致,那就正好对上了————如果没有,那么哪些是没有的?把没有的这些模型的名字也列出来
——SODA模型 A和D的代码不同一定是因为他们使用的模型不同,这一部分是代码的主要差异,才分成了两个github项目。——你复制去对比两个代码,看看那部分不同,最终就找到了每个模型代码的部分,这也是两个项目代码的主要不同。
——最后你去确认作者用的这十几个模型,是“主流的识别模型,不是专门来做小目标识别的”,还是说是“专门为小目标识别而设计的模型”——检验的方式很简单,你把每个模型引用的文章名拿到,然后你去看文章的解读博客,看博客他的创新之处在哪里,如果没有博客讲这篇文章,你就去看原文,看看作者这个模型是为了解决什么问题而设计的————如果是后者这个代码有参考意义,如果是前者那就对我完成论文创新的任务意义不大了
作者提供的这个代码,我给你介绍一下
两个数据集的代码如下。(1)首先两个数据集使用的模型肯定是不同的,但是我目前没有找到使用的模型的那个列表的代码的位置。(2)二者使用的识别的工具library、package也是不同的,Driven使用的是mmdetection这个包,Aerial使用的是mmrotate这个包(可能是应为航空图中的目标经常旋转各种角度,所以用这个包吧)
-
SODA-D Benchmark: SODA-mmdetection
它讲了什么:
——是基于mmdetection做的。
——这个repo使用的工具的版本号如下 Python 3.8, PyTorch 1.10 and mmdet 2.23.0。
——相对应的各项配置写在了这个位置 sodad-benchmarks ((1)首先找到这个位置(2)看里面写的是什么,有没有调用现成的模型,有没有规定是使用mmdetection这个工具调用哪些现成写好的工具)
——不同于经典的数据集,有对图片特殊的预处理,训练之前要做了image split。如何做split的细节,写在了这个位置(对于我来说没用)
-
SODA-A Benchmark: SODA-mmrotate
——是基于mmrotate这个package/library来做的
——是基于后面这些包来做的Python 3.8, PyTorch 1.10 and mmrotate 0.3.0
——相应的配置文件放在了sodaa-benchmarks.(等待你去看,是否列出了选择调用哪些模型?)
tiny和small的定义的区别,取决于defined by an area(在图片上的面积) threshold or length(在图片上的长度) threshold,比如对于COCO这个数据集,数据集的作者定义面积小于1024的就是small这个级别的object
——这让我想到一个问题,我们做训练的这个数据集, MOT和其他 行人检测pedistrain detection,以及 行人追踪、video crowd counting的数据集放在一起训练的时候,会存在一个问题。(1)首先有些摄像头是moving的不是static的,有的是人拿着摄像机走着拍,有的是公交车顶上往下拍摄,大家的追踪难度不同(目标的移动速度不同)(2)这些摄像头距离地面的距离是不同的,有的是在离地3米的监控摄像头拍摄的,有的是和人差不多高度(离地1.6m左右),那么距离地面高度不同,人的平均 长宽和面积大小是不同的,在一些数据集上适用的 small object的阈值,到了另一个视频上就不适用了。比如高空3m的这个 3pix乘3px这么小才算比较远的小目标,但是到了另一个距离地面1.6m的摄像头上可能5px乘5px这么大才算小目标。我觉得几乎不可能找到一组参数(比如10px是离摄像头近,5px是距离摄像头不近不远, 2px是远距离小目标),因为每个拍摄角度(1.6m的平视和3m高空的俯视),每个距离地面的距离拍摄出来的录像都有自己时候的一套参数。
——我觉得最合适的是,我们自己按照一个高度拍出视频数据集,在这个数据集上找到合适的参数,然后以后的人想用我们这个模型,他也把摄像头安装到距离地面和我们一样的高度,录完像,用我买的模型,用我提供好的距离阈值参数选择对几米以内的人进行计数。数据标注的过程很耗时,可以前期的东西跑通了,有空再去收集自己的数据集。
术语Term解释
SSD(Single Shot Detector )
与SSD思路完全相反的模型:像RCNN,fast RCNN,faster RCNN,这类检测方法都需要先通过一些方法得到候选区域,然后对这些候选区使用高质量的分类器进行分类。这类方法的检测准确率比较高但是计算开销非常大,不利于实时检测和嵌入式等设备。
SSD的思路:(1)将提取候选区和进行分类这两个任务融合到一个网络中。(2)既不使用预定义的box(3)也不使用候选区proposal生成网络来进行寻找目标物体。而是(4)通过一些的卷积核来对卷积网络得到的特征来计算类别分数和位置偏差。细节看https://www.bbsmax.com/A/RnJWPBWy5q/;https://blog.csdn.net/qq_36926037/article/details/105678787;https://zhuanlan.zhihu.com/p/39734758
一句话概括SSD的原理:将bounding boxes的输出空间离散化为一系列default boxes(这些default boxes建立在feature map的每个单元格位置上,且拥有不同比例和尺度)
SSD对small object detection有用的一个特性:结合了多个不同分辨率(大小)的feature map的预测,有利于处理多尺度的目标。
shot
One-shot learning :(这篇文章用到的shot,指的不是这个)
one shot learning的意思是,当一个类别在数据集中的样本量很少,少到一个类别只有一张图片(数据样本)的时候,在这种条件下,你如何做分类或识别?这就是一个小样本学习的问题。
举个one-shot learning的例子。如某公司有20个员工,数据库里每个员工的照片只有一张,总共20张。考勤的时候需要刷脸来记attendance,在每个类别的数据量为1情况下,你要做一个模型,去识别,来刷脸打卡的这个人是这二十个员工中的哪一个一个(属于哪个类别的),亦或不是这个公司的员工。
上面讲的这个one-shot learning的这个具体问题如何解决呢?首先你不能使用Conv+全连接+softamx CNN这种参数量很大的深度学习模型(只是我这里举得这个例子我不用,你要是用了深度学习模型以后work了那也很好),因为样本量太小了,根本不够拟合模型用的,无法得到一个有效的模型。那咋办?很简单你设计一个计算差异度的模型(反过来就是相似度),把来公司打卡签到的这个人的照片和数据库中这个20张照片一一逐一计算差异度。差异度高于一个阈值,就说明这个人不是数据库中的这个员工。低于一个阈值,就说明这个人就是这个员工。就完成了这个任务
MMRotate
功能是干什么的呢?简单来讲就是当你打开手机上的扫描软件的时候,准备扫描一个文档或者文件,这时候,拍照之后,整张纸或者文档,扫描的图像不是方方正正的,然后扫描软件是不是可以帮你自动纠正,然后旋转,让你扫描到的文档图片变成了一个保存或者打印的文档了。
没错,这个库就是干这个用的。
用专业的术语介绍就是:在真实场景中,我们见到的图像不都是方方正正的,比如扫描的图书和遥感图像,需要检测的目标通常是有一定旋转角度的。这时候就需要用到旋转目标检测方法,对目标进行精确的定位,方便后面的识别、分析等高级任务。所谓旋转目标检测(Rotated Object Detection),又称为有向目标检测(Oriented Object Detection),试图在检测出目标位置的同时得到目标的方向信息。它通过重新定义目标表示形式,以及增加回归自由度数量的操作,实现旋转矩形、四边形甚至任意形状的目标检测。旋转目标检测在人脸识别、场景文字、遥感影像、自动驾驶、医学图像、机器人抓取等领域都有广泛应用。