Abstract:
与 anchor-based基于锚点的检测器相比,anchor-free无锚点检测器 具有灵活性和较低计算复杂度的优点。然而,在复杂的遥感场景中,受限的几何尺寸、目标的弱特征 以及 广泛分布的与目标特征相似的环境元素 使得小目标检测成为一项具有挑战性的任务。为了解决这些问题,我们提出了一种名为 FE-CenterNet 的无锚检测器,它可以在复杂的遥感场景中准确检测车辆等小物体。首先,我们设计了一个由特征聚合结构(FAS)和注意力生成结构(AGS)组成的 特征增强模块(FEM)。该模块通过 挖掘多尺度上下文信息 并 结合坐标注意机制,有助于抑制场景中虚警的干扰,从而提高对小目标的感知。同时,为了满足小目标的高定位精度要求,我们提出了一种新的损失函数,在推理过程中不需要额外的计算和时间成本。最后,为验证算法性能并为后续研究提供基础,我们建立了包含各种目标和复杂场景的昏暗小型车辆数据集(DSVD)。实验结果表明,所提出的方法比主流目标检测器性能更好。具体来说,我们方法的平均精度 (AP) 指标比原始 CenterNet 高 7.2%,仅降低 1.3 FPS。
1. Introduction
遥感图像中的自动目标检测在商业和军事领域引起了越来越多的关注,可广泛应用于空中侦察、交通监控和区域监视应用。然而,由于遥感图像分辨率和质量的限制,大多数感兴趣的目标如车辆[1-4]表现出以下特征:尺寸小,特征暗淡模糊,对比度低[5,6] 。此外,独特的遥感成像系统导致场景的复杂性 和 目标方位的多变性,给检测任务带来了极大的困难。因此,研究一种有效的遥感图像小目标检测方法具有重要意义。在本文中,我们将面积小于 32×32 像素的物体定义为小目标[7],主要关注遥感图像中的小型车辆检测。
卷积神经网络 (CNN) [8] 可以通过自适应学习代表性特征来实现端到端检测,而无需手工制作特征。典型的检测网络大致可以分为两类:anchor-based 和 anchor-free检测器。基于锚点的检测器,例如 Faster-RCNN [9] 和 YOLO [10],需要根据数据集中 目标的纵横比 对锚点参数进行微调,以实现有希望的性能。然而,不同遥感场景中目标的长宽比显得如此多样化,这使得调整锚点的参数变得困难且耗时[11]。无需考虑anchor的选择,anchor-free检测器 独立于anchor的超参数,降低了算法的计算复杂度。此外,anchor-free 检测器依赖关键点 从高分辨率特征图中检测目标,容易捕获小范围内的目标。
CenterNet [12]作为anchor-free检测器的典型代表,通过提取的特征图直接预测物体的中心点。与其他方法相比,CenterNet 简洁的目标检测框架 使其具有在检测精度和速度之间取得平衡的潜力。此外,CenterNet 使用从输入图像中四倍下采样的高分辨率特征进行预测,其优势在于可以实现对小而密集目标的理想检测性能。然而,由于场景的多样性和复杂性 以及 小目标的单调外观,很难提取鲁棒的特征来充分表示,因为 CenterNet 的性能在很大程度上依赖于获取的特征图,这在一定程度上限制了其在复杂遥感场景中的应用性能。
在本文中,我们通过设计一个特征增强模块(FEM)来帮助网络增强实用特征,同时抑制不必要的细节,从而提出特征增强中心网(FE-CenterNet)。同时,我们在CenterNet框架中采用了新的损失函数 来保证小目标的定位精度。所有上述改进都是在没有许多额外参数和计算成本的情况下实现的。此外,为了评估遥感图像中小目标检测器的性能,我们构建了一个由各种物体和复杂场景组成的昏暗小型车辆数据集(DSVD)。实验证明,FE-CenterNet 在小目标检测方面具有显着优势,并在 DSVD 上实现了最先进的性能。
我们工作的主要贡献如下:
• anchor-free无锚检测器,在复杂的遥感场景中对小目标检测具有出色的性能。
• 特征增强模块,通过挖掘多尺度特征 和 集成注意力机制,极大地提高了小目标的特征提取和表示能力。
• 已建立的小型和昏暗模糊的车辆数据集,有助于评估小型物体检测算法的性能。
本文的其余部分安排如下。在第 2 节介绍了小目标检测的相关工作之后,我们在第 3 节详细阐述了所提出的 FE-CenterNet 体系结构。在第 4 节,我们简要介绍了构建的小型和昏暗模糊的数据集,并描述为比较所提出方法和典型方法的性能而进行的实验。最后,我们在第 4 节进行总结和归纳。
2. Related Works
随着深度学习技术的快速发展,基于卷积神经网络(CNN)的遥感目标检测逐渐受到关注。众所周知,主流方法分为基于锚点和无锚点的框架。本节介绍两大品类的主要发展趋势,分析存在的问题。在此基础上,我们 说明了选择无锚框架的原因 以及所提出的遥感图像小目标检测方法的解决方案。
2.1. Anchor-Based Framework for Object Detection
2012年后,CNN的兴起将目标检测推向了一个巨大的进步。通过自动挖掘重要特征,可以缓解基于手工特征描述符的准确性差和冗余计算的问题。基于锚点的检测器 使用 数量、大小和纵横比的超参数 对从各种锚点生成的不同候选对象 进行预测和分类。无论候选者是否产生,基于锚点的框架分为两阶段和一阶段检测器。前者使用区域建议网络(RPN)[9]提取感兴趣区域(ROI)作为第一阶段,然后进行精确的边界框回归和对象分类。
R-CNN [13] 作为最早的两阶段检测器,首先使用选择性搜索方法生成候选,然后使用 CNN 提取特征。问题在于需要对所有候选者单独进行特征提取,这是一个反复耗时的过程。为了解决上述问题,Fast-RCNN [14] 直接从整体图像中提取特征,然后将其映射到感兴趣区域。同时,为了减少传统区域提议算法所消耗的时间,Faster-RCNN [9] 引入了 RPN 来实现基于深度学习的端到端目标检测,进一步简化了检测流水线。后续的改进主要出现在Faster-RCNN的模块基础上。 Mask RCNN [15] 利用 RoIAlign 代替 RoIPool,解决了特征图映射过程中的区域不匹配问题。 Cascade-RCNN [16]通过不同的IOU(interaction over union)阈值来确定正负样本,并级联多个网络来优化预测结果。对于小目标检测,Wang 等人 [17 Vehicle Detection Using Deep Learning with Deformable Convolution ] 结合基于区域的全卷积网络(R-FCN)和可变形卷积(DCN)来充分利用小型车辆的有限信息。 Zhang 等人 [18 Small-Scale Aircraft Detection in Remote Sensing Images Based on Faster-RCNN] 利用 K-means 生成锚的超参数。他们将改进后的 VGG16 和 Soft-NMS 引入到 Faster-RCNN 中,以实现对小型飞机的有效检测性能。两阶段网络建立了一种基于锚框机制的由粗到细的目标检测方法,实现了良好的检测性能。然而,两阶段过程显著增加了计算成本和推理时间。
与两阶段检测器相比,一阶段检测器将目标检测视为回归问题。它直接对提取的特征进行回归,得到目标类别概率和位置坐标值。 YOLO 架构的检测器作为主流的单阶段目标检测器,将输入图像划分为多个相同大小的网格。他们对可疑对象进行分类,并根据以网格为中心的边界框回归位置。 YOLOv2 [10] 将 Darknet 设计为特征提取网络,并在所有卷积层之后添加批量归一化 (BN)。 YOLOv3 [19] 继续改进名为 Darknet53 的主干网络,它通过卷积代替池化对特征图进行下采样。为了解决一阶段网络中正负样本不平衡的问题,RetinaNet[20]提出了focal loss来 调整损失函数中不可区分样本的权重。现在,基于 YOLOv3 提出了许多改进版本 [3,21,22],它们应用并结合了大量先进的检测技术技巧。他们逐渐在准确性和速度之间取得了出色的平衡。对于小目标检测,Bashir 等人 [23 Small Object Detection in Remote Sensing Images with Residual Feature Aggregation-Based Super-Resolution and Object Detector Network ] 将循环生成对抗网络 (GAN) 与 YOLO 检测架构相结合,以实现小目标的图像超分辨率。 Zhou等人[24 Vehicle Detection in Remote Sensing Image Based on Machine Vision]将伽马校正应用于图像预处理,使图像的阴影部分变亮,并提出了一种特征融合结构IR-PANet,以提高对小目标的识别能力。Kim 等人 [25 ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image] 提出了一种高效的通道注意力金字塔 YOLO(ECAP-YOLO),它增加了一个用于小目标检测的检测层。
然而,基于anchor的方法作为目标检测最早的重要分支,其检测性能在很大程度上取决于正负样本的数量和anchor boxes的超参数。由于遥感独特的俯视视角,物体的方位变化使得需要设置大量不同尺度和纵横比的anchor boxes,显著增加了算法的计算复杂度。它限制了遥感场景中的检测性能和速度。
2.2. Anchor-Free Framework for Object Detection
无锚检测器 移除了锚机制 并 应用关键点来生成候选者。这些方法不需要为锚点设置超参数,降低了算法的计算复杂度。基于关键点的anchor-free框架通常检测高分辨率特征图上的物体,因此它们倾向于感知小尺度的物体。这种方法对于特殊鸟瞰遥感图像中的目标检测 具有更高的灵活性和普适性。它们有可能在复杂场景中实现对昏暗和小目标的有效检测。
CornerNet [26] 通过 预测对角线角点 来实现目标的定位和检测。它利用角点嵌入向量之间的距离来匹配相同的目标。基于 CornerNet,CentripetalNet [27] 引入了向心位移模块和十字星可变形卷积,以实现更高质量的边界框预测。 ExtremeNet [28] 用每个类别的四个极端关键点预测中心关键点,并使用暴力枚举进行匹配。 FCOS [29] 直接预测边界框的四个边到中心的距离。上述方法虽然删除了锚框机制,但都包含了一些复杂的后处理方法来匹配关键点。与其他方法相比,CenterNet [12] 作为一种简洁的目标检测框架,在检测精度和速度之间取得了平衡。它预测物体的中心点热图,并通过中心周围的特征获取长度和宽度等信息。受区域生成网络(RPN)的启发,FII-CenterNet [30]引入前景信息 以减少复杂场景的影响 并集中在感兴趣的对象上。在 [31] 中,基于 CenterNet 结合目标似然 和 条件分类得分 构建了概率两阶段检测器。在 [32] 中,CenterNet++ 将中心关键点与角点关键点相结合,将目标检测为三元组以全局捕获显著信息。上述改进方法主要受两阶段检测器的启发,可以在一定程度上提高检测精度。然而,前景信息 或 区域提议的引入破坏了 CenterNet 的结构简单性,并显着增加了计算复杂度和推理时间。因此,我们 提出 FE-CenterNet 以 在检测时间几乎没有增加的情况下 实现有前途的检测性能。为了增强小目标的感知能力,我们设计了一个 集成 坐标注意力机制 和 多尺度特征提取 的特征增强模块。同时,在训练过程中提出了一种 整合鲁棒的定位信息的 损失函数,无需额外计算进行推断 即可提高定位的回归精度。
3. Proposed Method
FE-CenterNet 的主要架构如图 1 所示。与 CenterNet 类似,FE-CenterNet 利用修改后的 DLA-34 [12] 作为主干来提取多层次的特征,并获得四倍下采样的特征图。具体来说,我们在骨干网络之后提出了特征增强模块(FEM),提高了小目标特征的表示能力。该模块由特征聚合结构(FAS)和 注意力生成结构(AGS)组成,这两个结构的详细解释在第 3.1 节中提供。 FAS 将多尺度特征与上下文信息的引入相结合,以抑制复杂场景的虚警。此外,AGS将坐标关系嵌入到注意力机制中,加强了对小目标的感知能力。在训练过程中,我们提出了一种新的损失函数来适应对定位精度的高要求,这在3.2节中进行了阐述。损失函数在推理过程中无需额外计算即可提高检测性能。

3.1 Feature-Enhanced Module
遥感图像中小目标的检测主要面临两个挑战:(1)场景复杂,虚警过多,干扰小目标检测; (2)目标尺度小,特征弱,难以捕捉到实际特征。针对上述问题,我们提出了一种特征增强模块(FEM),它由特征聚合结构(FAS)和注意力生成结构(AGS)组成。该模块提取多尺度特征以聚合图像中的上下文信息,并通过注意力机制增强对小尺度物体有效特征的感知能力。通过FEM,对骨干提取网络提取的高分辨率特征图进行特征聚合和增强,可以有效提高对小目标的检测性能。特征聚合增强模块的主要结构如图2所示。
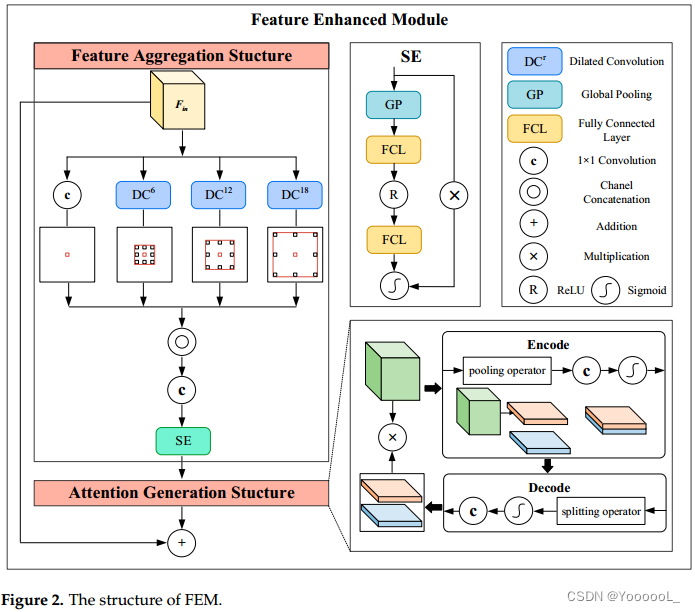
由于遥感图像的复杂性,容易出现与目标具有相似特征的虚警,极大地影响了检测性能。虚警与目标具有相同的特征,仅凭其特征很难识别。因此,需要引入全局上下文信息,利用场景的语义信息来抑制虚警。普通卷积具有固定的感受野,只能对固定大小的局部区域进行特征提取。在特征聚合结构 (FAS) 中,受 ASPP 块启发,我们利用多个并行的膨胀卷积来收集的特征图中的多尺度信息 [33]。由于有效语义信息的聚合,所收集的输出受复杂场景的影响较小。
与普通卷积相比,膨胀卷积通过调整膨胀率来获得不同尺度的感受野。在这里,我们将扩张率为 m 且内核大小为 n × n 的扩张卷积表示为 ![]() 。对于输入的特征图
。对于输入的特征图 ![]() ,h和w分别表示特征图的长度和宽度。c 是通道数。得到 与输入特征图同维 的特定感受野下的特征提取结果:
,h和w分别表示特征图的长度和宽度。c 是通道数。得到 与输入特征图同维 的特定感受野下的特征提取结果:
![]()
我们 将扩张率设置为 6、12 和 18,并对输入的特征图进行扩张卷积运算,以获得不同尺度的聚合特征。此外,使用 1×1 卷积来保持特征表示与输入特征图具有精确的分辨率。然后,应用连接运算符和 1×1 卷积得到最终输出。计算过程如下所示,其中Fcat是多尺度信息的聚合结果。在这里,1×1 卷积有助于使特征图通道的输出与输入图的通道相同。

在不同通道中提取的多尺度特征对检测小目标做出了不同的贡献。因此,我们加入了通道注意力机制,根据特征融合后的重要性给每个通道分配不同的权重。通道注意力机制通过学习自动获取每个通道的重要性,从而加强边缘细节和语义信息。受 SE 块 [34] 的启发,我们通过空间池化算子获得每个通道的全局信息,产生 1×1×C 通道特征向量。特征向量 vc 的第 k 个通道表示为:

其中![]() 表示 第 i 行 第 j 列第 k 通道的Fcat的值。
表示 第 i 行 第 j 列第 k 通道的Fcat的值。
之后,我们使用了由两个全连接层组成的瓶颈层。特征向量的维度先被降低,然后恢复到原来的维度。瓶颈层可以更好地适应通道间复杂的相关性,减少计算量。 sigmoid函数对特征向量进行处理,得到每个通道的归一化权重。最后,将每个通道中的特征图乘以权重因子得到重新缩放的结果。最终输出写为:
![]()
其中FC代表全连接层,ReLU和Sigmoid是非线性激活函数。
由于几何比例有限,小目标缺乏纹理细节。同时,对于小目标的定位精度要求要高于大目标。这意味着中心位置的轻微偏差可能会导致不准确的边界框回归。因此,在使用特征聚合结构(FAS)获得融合了多尺度信息的特征图后,我们提出了一种基于坐标注意机制的注意力生成结构(AGS)。通过嵌入坐标位置,该结构 增强了小目标的有效特征,提高了定位和感知能力。

注意力机制通过 对通道和区域 应用不同的重要性 来帮助网络提高 对特定的细节特征和语义信息的感知。受 CA [35 Coordinate attention for efficient mobile network design.] 块的启发,AGM 由 空间信息编码 和 解码程序 组成。坐标嵌入有助于挖掘有利于定位小目标的空间维度信息。
首先,AGS 通过一对分别沿维度 x 和 y 的池化算子 将空间信息嵌入到通道关系中。与全局池化相比,这种池化可以在获取通道描述的同时保留坐标信息。由于坐标位置的嵌入,编码后的特征图可以捕获感兴趣区域的空间信息,这有助于满足小目标检测对位置信息的依赖性。对于来自 FAS 的特征图 ![]() ,池化向量
,池化向量 ![]() 和
和 ![]() ,沿单个空间维度,可以表示如下:
,沿单个空间维度,可以表示如下:


其中 ![]() 是第 k 个通道和第 i 个位置沿垂直方向的池化结果,
是第 k 个通道和第 i 个位置沿垂直方向的池化结果,![]() 是第 k 个通道和第 j 个位置沿水平方向的池化结果。
是第 k 个通道和第 j 个位置沿水平方向的池化结果。
对于从等式 (5) 和 (6) 计算的合并向量,我们应用通道级联来获得聚合向量 ![]() 。此外,还利用 1×1 卷积来实现通道维数的减少。这种通道压缩过程有助于表示通道相关性,同时减少参数数量。最终编码结果
。此外,还利用 1×1 卷积来实现通道维数的减少。这种通道压缩过程有助于表示通道相关性,同时减少参数数量。最终编码结果 ![]() 表示为:
表示为:
![]()
其中 conv1×1 表示 1×1 卷积变换。
在获得对空间信息进行编码的特征向量 vencode 之后,下一步是对空间信息进行解码并将解码后的注意力权重应用于输入特征图。编码向量 vencode 沿垂直和水平维度拆分,得到单向编码向量 ![]() 和
和 ![]() :
:
![]()
其中 split(·) 表示维拆分算子。
对于分割向量,使用 1×1 卷积变换来恢复通道缩减的影响,产生与输入特征图相同的通道维度。沿不同空间方向的解码的注意力权重可以写为:
![]()
![]()
其中 wx 和 wy 分别是嵌入在垂直和水平空间信息中的一对注意力权重。通过应用解码的注意力权重,最终输出的特征图![]() 可以表示为:
可以表示为:
![]()
3.2. Loss Function
为了提高小目标边界框的回归精度,将 CenterNet 的原始损失更新为完整的交并比(CIOU)[36],最终由关键点热图、交并比、大小和中心偏移量组成。整个函数 Ldet 表示为:
![]()
我们将(1, 0.1, 1)设置为 ![]() ,它们是调整损失函数中各部分权重的超参数。
,它们是调整损失函数中各部分权重的超参数。
CenterNet 将目标检测为点 并在预测之前 生成关键点热图 ![]() 、大小预测
、大小预测 ![]() 和 中心偏移
和 中心偏移 ![]() [11],其中 W、H 和 C 分别表示宽度、长度和 目标类别。R 是下采样步长,我们将其设置为 4,以确保足够高分辨率的特征图用于小目标检测。关键点损失定义为:
[11],其中 W、H 和 C 分别表示宽度、长度和 目标类别。R 是下采样步长,我们将其设置为 4,以确保足够高分辨率的特征图用于小目标检测。关键点损失定义为:
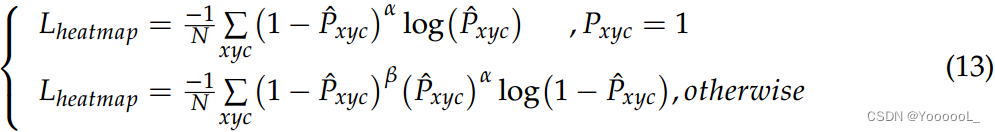
其中 Pxyc 是由与 CenterNet 相同的高斯函数生成的真值热图。由于只有那些 Pxyc = 1 被视为正样本,这带来了正负样本之间的不平衡,我们使用 focal loss 来缓解这种情况。a 和 b 是 focal loss 中的超参数,默认设置为 2 和 4。 N 是用于归一化的关键点总数。
对于表示为 ![]() 的第 k 个真值边界框,其长度和宽度为
的第 k 个真值边界框,其长度和宽度为![]() ,而中心位置为
,而中心位置为 ![]() 。 size 和 offset 都是用 L1 loss 训练的,计算如下,
。 size 和 offset 都是用 L1 loss 训练的,计算如下,
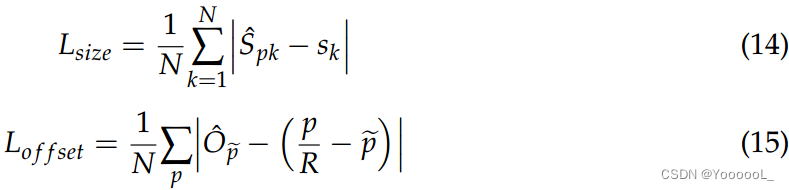
其中 ![]() 表示位置经过R次下采样后的整数部分。
表示位置经过R次下采样后的整数部分。
原有的CenterNet损失函数 独立优化 中心位置和目标大小,导致对小目标的定位精度不佳。因此,我们在预测边界框和真值边界框重叠的监督下,在损失函数计算训练中引入了 CIOU。 CIOU综合考虑距离、重叠度、长宽比,综合优化预测框和真值边界框的匹配度。 CIOU 写成:

其中 IOU 是预测边界框和 真值边界框之间的交并比。 ppred和pgt分别是 预测和真值的中心点 。ρ代表欧式距离算子,a为权重因子。纵横比相似度公式为:

CIOU loss的加入可以提高CenterNet对小目标的定位精度,提高网络的收敛效率。
4. Experimental Results
4.1. Dim and Vehicle Datasets
我们基于 UNICORN 2008 数据集 [37] 构建了一个昏暗的小型车辆数据集(DSVD),以评估所提出算法的小目标检测性能。UNICORN 2008 源数据集是一种广域运动图像 (WAMI) 数据集,包含 6471 张图像。每幅图像的覆盖面积约为 5 km × 5 km,图像大小约为 10,000 × 10,000 像素。基于UNICORN 2008构建的小目标数据集存在以下检测难点:
• 外观相对单调的车辆体积小,特征暗淡,对比度低。很难为这些目标获得稳健的特征表示。目标的局部区域如图 3 所示。
• 图像覆盖面广,场景复杂多样,如停车场、马路、小区等。此外,场景中存在大量疑似物体,容易成为虚警源。复杂的场景如图 4 所示。
上述场景的复杂性和目标的弱特性使得 UNICORN 2008 中的车辆检测变得相当具有挑战性。我们将 UNICORN 2008 中的图像分成几个 640 × 640 像素的块,并选择不同的场景。对于高达 3225 的拾取图像,我们使用矩形边界框对车辆进行了彻底标记。总共从整幅图像中随机抽取2257幅图像用于网络训练,其余968幅图像作为网络性能评估的测试数据。
4.2. Evaluation Metrics
我们应用精度、召回率、F1 分数和 AP(平均精度)指标来评估所提出方法的检测性能。检测到的边界框和真值边界框的交并比 (IOU) 设置为阈值 0.5。在这些指标中,精度和召回率可用于评估漏报和虚警的检测,计算如下:

其中 TP、FP 和 FN 代表真正样本、假正样本和假负样本。
F1 score和AP可以更全面的评价检测方法。 F1,精确率和召回率的调和平均值,写为:

AP 被定义为召回率-精确率曲线包围的面积,公式为:
![]()
为了评估检测算法的推理速度,我们使用了 FPS(每秒帧数)指标。
4.3. Implementation Details and Ablation Analysis
所有实验均在 Inter Xeon® Silver 4210R CPU 和 NVIDIA Quadro RTX 4000 GPU 中使用 Pytorch 框架进行。在训练过程中,输入分辨率为512×512像素,我们得到一个128×128像素的特征图进行预测。我们以 4 的批量大小训练了 140 个时期的模型。选择学习率为 8 × 10−5 的 Adam 优化器,在 90 和 120 个 epoch 时分别减少了 10 倍。
图 5 和图 6 显示了我们方法的一些检测结果,它可以对小而暗的目标取得良好的性能。如图 5 所示,一些外观特征有限的目标对比度较低,而我们的方法可以检测到所有目标而不会漏报。对于类似于图 6 中的目标具有大量干扰的复杂场景,我们的方法也可以在没有虚警的情况下表现良好。

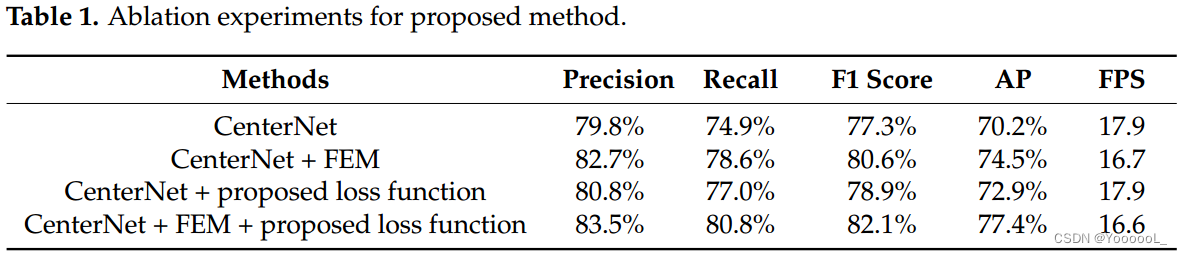
 基于构建的 DSVD,我们对所提出的方法进行了消融实验,以评估小目标检测的性能改进。在训练和评估过程中应用相同的策略和参数以确保公平比较。如表 1 所示,我们使用精度、召回率、F1 分数和 AP 来评估检测性能,使用 FPS 来比较检测速度。显然,与 CenterNet 相比,所提出的方法在检测性能指标方面具有出色的优势,并且几乎不影响推理速度。 FEM 的加入和损失函数的改进将 AP 指标提高了 4.3% 和 2.7%,FPS 指标略有下降。最后,在本文中,与最初的CenterNet相比, FE-CenterNet,将 AP 提高了 7.2%,几乎没有增加额外的推理时间(FPS 从 17.9 到 16.6)。同时,为了直观地说明 FEM 的效果,我们在图 7 中提供了一些特征可视化。在增强之前,存在大量干扰,这些干扰可能会在特征图中突出显示。但是,经过 FEM 的增强后,它们被抑制了很多。另外,左右两边特征较弱的物体在特征图中并没有清晰的表现出来。通过特征增强,这些目标都被突出显示。
基于构建的 DSVD,我们对所提出的方法进行了消融实验,以评估小目标检测的性能改进。在训练和评估过程中应用相同的策略和参数以确保公平比较。如表 1 所示,我们使用精度、召回率、F1 分数和 AP 来评估检测性能,使用 FPS 来比较检测速度。显然,与 CenterNet 相比,所提出的方法在检测性能指标方面具有出色的优势,并且几乎不影响推理速度。 FEM 的加入和损失函数的改进将 AP 指标提高了 4.3% 和 2.7%,FPS 指标略有下降。最后,在本文中,与最初的CenterNet相比, FE-CenterNet,将 AP 提高了 7.2%,几乎没有增加额外的推理时间(FPS 从 17.9 到 16.6)。同时,为了直观地说明 FEM 的效果,我们在图 7 中提供了一些特征可视化。在增强之前,存在大量干扰,这些干扰可能会在特征图中突出显示。但是,经过 FEM 的增强后,它们被抑制了很多。另外,左右两边特征较弱的物体在特征图中并没有清晰的表现出来。通过特征增强,这些目标都被突出显示。
 为了更直观地展示检测性能的改进,将 CenterNet 和提出的 FE-CenterNet 的检测结果可视化,如图 8 所示。其中,数据集中的道路、停车场和社区三个典型场景被选中。可以看出,基于特征增强模块和改进后的损失函数,FE-CenterNet不易受到虚警源的干扰,对小目标的感知能力更强。在场景复杂多变的遥感影像中,容易出现与目标具有相似特征的自然景观和人工设备,如阴影块(区域1、3、5、6、9、10)、屋顶(区域2)和树木(区域 4 和 7)。 CenterNet 不能很好地利用上下文信息,这使得很难从此类虚警中区分目标。本文提出的网络可以 通过特征聚合结构 聚合多尺度特征,有效减少虚警错误,提高精度。同时,遥感图像中的车辆目标几何尺度小,纹理和结构特征较弱,难以被网络充分感知。如区域 8 和区域 11 所示,CenterNet 未能检测到微小目标。同时,FE-CenterNet可以通过注意力生成结构实现对它们更有效的感知,提高召回率。
为了更直观地展示检测性能的改进,将 CenterNet 和提出的 FE-CenterNet 的检测结果可视化,如图 8 所示。其中,数据集中的道路、停车场和社区三个典型场景被选中。可以看出,基于特征增强模块和改进后的损失函数,FE-CenterNet不易受到虚警源的干扰,对小目标的感知能力更强。在场景复杂多变的遥感影像中,容易出现与目标具有相似特征的自然景观和人工设备,如阴影块(区域1、3、5、6、9、10)、屋顶(区域2)和树木(区域 4 和 7)。 CenterNet 不能很好地利用上下文信息,这使得很难从此类虚警中区分目标。本文提出的网络可以 通过特征聚合结构 聚合多尺度特征,有效减少虚警错误,提高精度。同时,遥感图像中的车辆目标几何尺度小,纹理和结构特征较弱,难以被网络充分感知。如区域 8 和区域 11 所示,CenterNet 未能检测到微小目标。同时,FE-CenterNet可以通过注意力生成结构实现对它们更有效的感知,提高召回率。


4.4. Algorithm Performance Comparison
为了验证我们提出的方法的整体性能,我们将其与基于相同实现环境、数据集和评估指标的多个代表性检测算法进行了比较。在选定的方法中,CascadeRCNN [15] 是一种从 Faster-RCNN 改进而来的两阶段检测器,它通常优于单阶段和无锚检测器,具有更高的计算复杂度。 ImYOLOv3 [3 Improved YOLOv3 Based on Attention Mechanism for Fast and Accurate Ship Detection in Optical Remote Sensing Images ] 在单阶段 YOLOv3 中引入了注意力机制,在遥感目标检测方面表现良好。 YOLOv7 [21] 目前是 YOLO 架构的最新算法,它结合了大量先进的检测技巧。 FII-CenterNet [23],同样基于anchor-free CenterNet,通过从两阶段网络中提取的 前景区域生成网络 提高了交通对象的检测能力。
评估结果如表2所示。在这些方法中,Cascade-RCNN的由粗到精的检测流程 和 FII-CenterNet中前景信息的引入有助于提高精度,但很难检测到所有目标。 两阶段的思想也对推理速度有很大的影响。而 imYOLOv3 通过应用注意力机制提高了对小而暗目标的感知能力,召回率相对较高。然而,它容易受到与目标相似的虚警的干扰。YOLOv7采用无锚anchor-free机制,速度优势明显。高级训练和推理策略的结合也使其优于其他比较算法。然而,由于缺乏为小目标设计的策略,它不如我们的 FE-CenterNet 有效。我们的方法基于多尺度特征融合结构和注意力生成结构,确保了最高的精度、召回率、F1 和 AP,同时保持相对较高的检测速度。
通过可视化图 9 中的检测结果直观地反映了上述结论。我们展示了 imYOLOv3、Cascade-RCNN、FII-CenterNet 和提出的方法的检测结果以进行比较。我们从停车场、社区、道路等各种复杂场景中选择显示的图像。同时,目标和场景之间的遮挡和低对比度给检测带来了很大的困难。从目标密集分布的区域1到区域3,Cascade-RCNN和FII-CenterNet的检测结果遗漏了大量目标,而imYOLOv3和提出的方法可以在此类场景中检测到更多目标。对于区域4有遮挡的目标和区域5到区域8特征较弱的物体,对比方法很难感知到目标,造成大量漏检。然而,所提出的方法可以实现上述复杂场景的最佳检测性能,而不会出现漏检和误检。
5. Conclusions
在本文中,我们提出了一种名为 FE-CenterNet 的无锚检测器,旨在复杂遥感场景中的小而暗的目标检测。首先,我们引入多尺度上下文信息来抑制与目标相似的虚警干扰,并集成坐标注意机制来改善对小目标的感知,从而提出了 FEM。然后,为了提高定位回归精度,我们提出了一种新的损失函数,将 CenterNet 的原始损失函数与 CIOU 损失相结合。最后,为了验证检测性能,我们构建了由各种复杂场景和对象组成的 DSVD。实验结果表明,与其他典型算法相比,我们的方法具有更好的检测性能和更高的推理速度,证明了其在复杂遥感场景中小物体检测的潜力。